說透IO多路復(fù)用模型
作者:京東零售 石朝陽
在說IO多路復(fù)用模型之前,我們先來大致了解下Linux文件系統(tǒng)。在Linux系統(tǒng)中,不論是你的鼠標(biāo),鍵盤,還是打印機(jī),甚至于連接到本機(jī)的socket client端,都是以文件描述符的形式存在于系統(tǒng)中,諸如此類,等等等等,所以可以這么說,一切皆文件。來看一下系統(tǒng)定義的文件描述符說明:
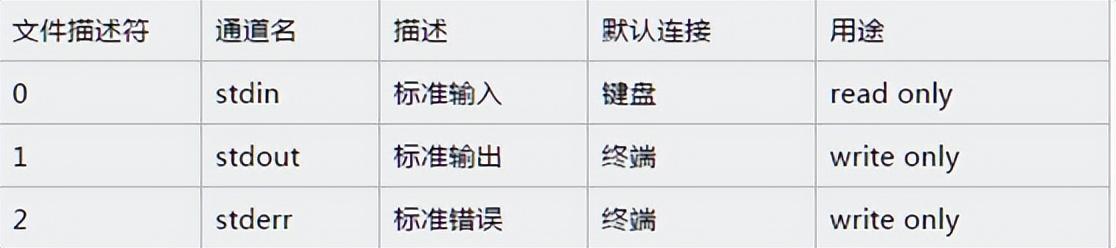
從上面的列表可以看到,文件描述符0,1,2都已經(jīng)被系統(tǒng)占用了,當(dāng)系統(tǒng)啟動的時(shí)候,這三個(gè)描述符就存在了。其中0代表標(biāo)準(zhǔn)輸入,1代表標(biāo)準(zhǔn)輸出,2代表錯(cuò)誤輸出。當(dāng)我們創(chuàng)建新的文件描述符的時(shí)候,就會在2的基礎(chǔ)上進(jìn)行遞增。可以這么說,文件描述符是為了管理被打開的文件而創(chuàng)建的系統(tǒng)索引,他代表了文件的身份ID。對標(biāo)windows的話,你可以認(rèn)為和句柄類似,這樣就更容易理解一些。
由于網(wǎng)上對linux文件這塊的原理描述的文章已經(jīng)非常多了,所以這里我不再做過多的贅述,感興趣的同學(xué)可以從Wikipedia翻閱一下。由于這塊內(nèi)容比較復(fù)雜,不屬于本文普及的內(nèi)容,建議讀者另行自研,這里我非常推薦馬士兵老師將linux文件系統(tǒng)這塊,講解的真的非常好。
select模型
此模型是IO多路復(fù)用的最早期使用的模型之一,距今已經(jīng)幾十年了,但是現(xiàn)在依舊有不少應(yīng)用還在采用此種方式,可見其長生不老。首先來看下其具體的定義(來源于man二類文檔):
這里解釋下其具體參數(shù):
參數(shù)一:nfds,也即maxfd,最大的文件描述符遞增一。這里之所以傳最大描述符,為的就是在遍歷fd_set的時(shí)候,限定遍歷范圍。
參數(shù)二:readfds,可讀文件描述符集合。
參數(shù)三:writefds,可寫文件描述符集合。
參數(shù)四:errorfds,異常文件描述符集合。
參數(shù)五:timeout,超時(shí)時(shí)間。在這段時(shí)間內(nèi)沒有檢測到描述符被觸發(fā),則返回。
下面的宏處理,可以對fd_set集合(準(zhǔn)確的說是bitmap,一個(gè)描述符有變更,則會在描述符對應(yīng)的索引處置1)進(jìn)行操作:
FD_CLR(inr fd,fd_set* set) 用來清除描述詞組set中相關(guān)fd 的位,即bitmap結(jié)構(gòu)中索引值為fd的值置為0。
FD_ISSET(int fd,fd_set *set) 用來測試描述詞組set中相關(guān)fd 的位是否為真,即bitmap結(jié)構(gòu)中某一位是否為1。
FD_SET(int fd,fd_set*set) 用來設(shè)置描述詞組set中相關(guān)fd的位,即將bitmap結(jié)構(gòu)中某一位設(shè)置為1,索引值為fd。
FD_ZERO(fd_set *set) 用來清除描述詞組set的全部位,即將bitmap結(jié)構(gòu)全部清零。
首先來看一段服務(wù)端采用了select模型的示例代碼:
上面的代碼我加了比較詳細(xì)的注釋了,大家應(yīng)該很容易看明白,說白了大概流程其實(shí)如下:
首先,創(chuàng)建socket套接字,創(chuàng)建完畢后,會獲取到此套接字的文件描述符。
然后,bind到指定的地址進(jìn)行監(jiān)聽listen。這樣,服務(wù)端就在特定的端口啟動起來并進(jìn)行監(jiān)聽了。
之后,利用開啟accept方法來監(jiān)聽客戶端的連接請求。一旦有客戶端連接,則將獲取到當(dāng)前客戶端連接的connection文件描述符。
雙方建立連接之后,就可以進(jìn)行數(shù)據(jù)互傳了。需要注意的是,在循環(huán)開始的時(shí)候,務(wù)必每次都要重新設(shè)置當(dāng)前connection的文件描述符,是因?yàn)槲募杳枋龇碓趦?nèi)核中被修改過,如果不重置,將會導(dǎo)致異常的情況。
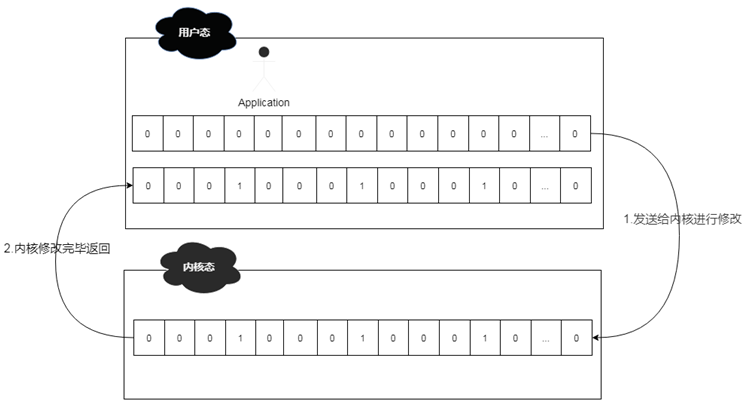
重新設(shè)置文件描述符后,就可以利用select函數(shù)從文件描述符表中,來輪詢哪些文件描述符就緒了。此時(shí)系統(tǒng)會將用戶態(tài)的文件描述符表發(fā)送到內(nèi)核態(tài)進(jìn)行調(diào)整,即將準(zhǔn)備就緒的文件描述符進(jìn)行置位,然后再發(fā)送給用戶態(tài)的應(yīng)用中來。
用戶通過FD_ISSET方法來輪詢文件描述符,如果數(shù)據(jù)可讀,則讀取數(shù)據(jù)即可。
舉個(gè)例子,假設(shè)此時(shí)連接上來了3個(gè)客戶端,connection的文件描述符分別為 4,8,12,那么其read_fds文件描述符表(bitmap結(jié)構(gòu))的大致結(jié)構(gòu)為 00010001000100000....0,由于read_fds文件描述符的長度為1024位,所以最多允許1024個(gè)連接。

而在select的時(shí)候,涉及到用戶態(tài)和內(nèi)核態(tài)的轉(zhuǎn)換,所以整體轉(zhuǎn)換方式如下:
所以,綜合起來,select整體還是比較高效和穩(wěn)定的,但是呈現(xiàn)出來的問題也不少,這些問題進(jìn)一步限制了其性能發(fā)揮:
- 文件描述符表為bitmap結(jié)構(gòu),且有長度為1024的限制。
- fdset無法做到重用,每次循環(huán)必須重新創(chuàng)建。
- 頻繁的用戶態(tài)和內(nèi)核態(tài)拷貝,性能開銷較大。
- 需要對文件描述符表進(jìn)行遍歷,O(n)的輪詢時(shí)間復(fù)雜度。
poll模型
考慮到select模型的幾個(gè)限制,后來進(jìn)行了改進(jìn),這也就是poll模型,既然是select模型的改進(jìn)版,那么肯定有其亮眼的地方,一起來看看吧。當(dāng)然,這次我們依舊是先翻閱linux man二類文檔,因?yàn)檫@是官方的文檔,對其有著最為精準(zhǔn)的定義。
其實(shí),從運(yùn)行機(jī)制上說來,poll所做的功能和select是基本上一樣的,都是等待并檢測一組文件描述符就緒,然后在進(jìn)行后續(xù)的IO處理工作。只不過不同的是,select中,采用的是bitmap結(jié)構(gòu),長度限定在1024位的文件描述符表,而poll模型則采用的是pollfd結(jié)構(gòu)的數(shù)組fds,也正是由于poll模型采用了數(shù)組結(jié)構(gòu),則不會有1024長度限制,使其能夠承受更高的并發(fā)。
pollfd結(jié)構(gòu)內(nèi)容如下:
從上面的結(jié)構(gòu)可以看出,fd很明顯就是指文件描述符,也就是當(dāng)客戶端連接上來后,fd會將生成的文件描述符保存到這里;而events則是指用戶想關(guān)注的事件;revents則是指實(shí)際返回的事件,是由系統(tǒng)內(nèi)核填充并返回,如果當(dāng)前的fd文件描述符有狀態(tài)變化,則revents的值就會有相應(yīng)的變化。
events事件列表如下:
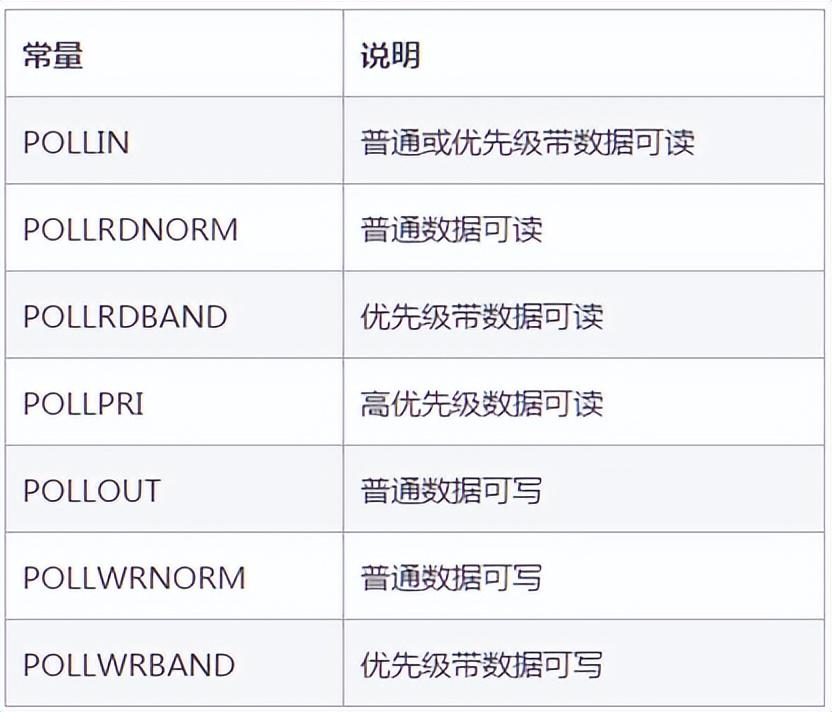
revents事件列表如下:
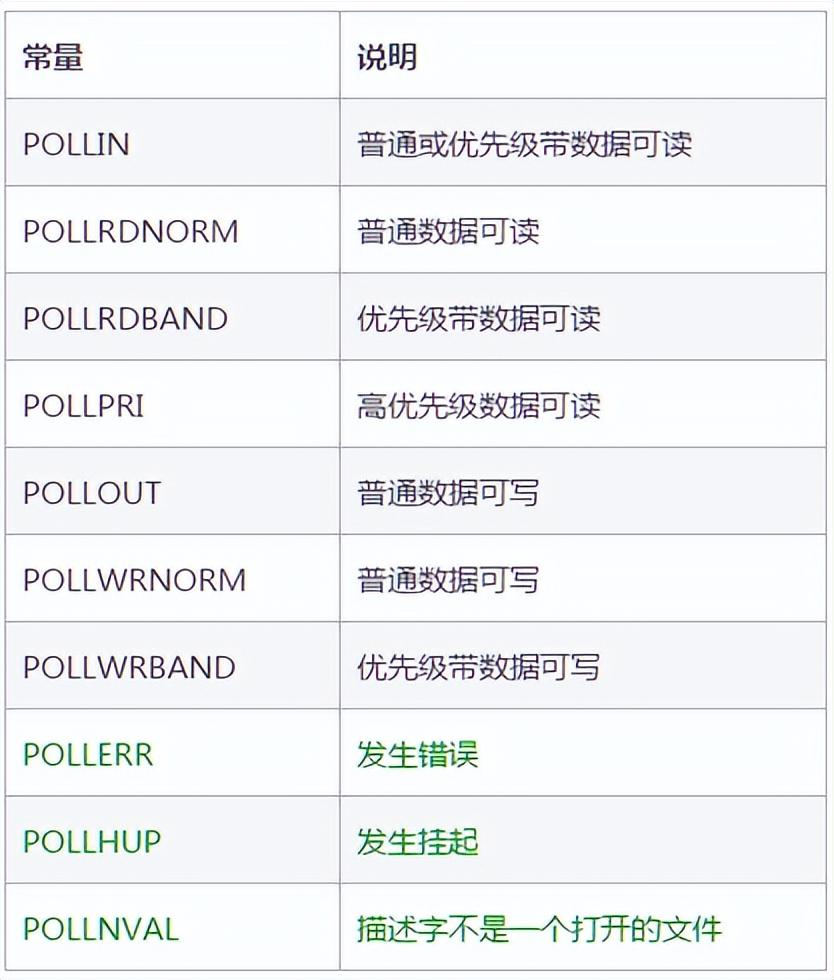
從列表中可以看出,revents是包含events的。接下來結(jié)合示例來看一下:
由于源碼中,我做了比較詳細(xì)的注釋,同時(shí)將和select模型不一樣的地方都列了出來,這里就不再詳細(xì)解釋了。總體說來,poll模型比select模型要好用一些,去掉了一些限制,但是仍然避免不了如下的問題:
- 用戶態(tài)和內(nèi)核態(tài)仍需要頻繁切換,因?yàn)閞events的賦值是在內(nèi)核態(tài)進(jìn)行的,然后再推送到用戶態(tài),和select類似,整體開銷較大。
- 仍需要遍歷數(shù)組,時(shí)間復(fù)雜度為O(N)。
epoll模型
如果說select模型和poll模型是早期的產(chǎn)物,在性能上有諸多不盡人意之處,那么自linux 2.6之后新增的epoll模型,則徹底解決了性能問題,一舉使得單機(jī)承受百萬并發(fā)的課題變得極為容易。現(xiàn)在可以這么說,只需要一些簡單的設(shè)置更改,然后配合上epoll的性能,實(shí)現(xiàn)單機(jī)百萬并發(fā)輕而易舉。同時(shí),由于epoll整體的優(yōu)化,使得之前的幾個(gè)比較耗費(fèi)性能的問題不再成為羈絆,所以也成為了linux平臺上進(jìn)行網(wǎng)絡(luò)通訊的首選模型。
講解之前,還是linux man文檔鎮(zhèn)樓:linux man epoll 4類文檔 linux man epoll 7類文檔,倆文檔結(jié)合著讀,會對epoll有個(gè)大概的了解。和之前提到的select和poll不同的是,此二者皆屬于系統(tǒng)調(diào)用函數(shù),但是epoll則不然,他是存在于內(nèi)核中的數(shù)據(jù)結(jié)構(gòu),可以通過epoll_create,epoll_ctl及epoll_wait三個(gè)函數(shù)結(jié)合來對此數(shù)據(jù)結(jié)構(gòu)進(jìn)行操控。
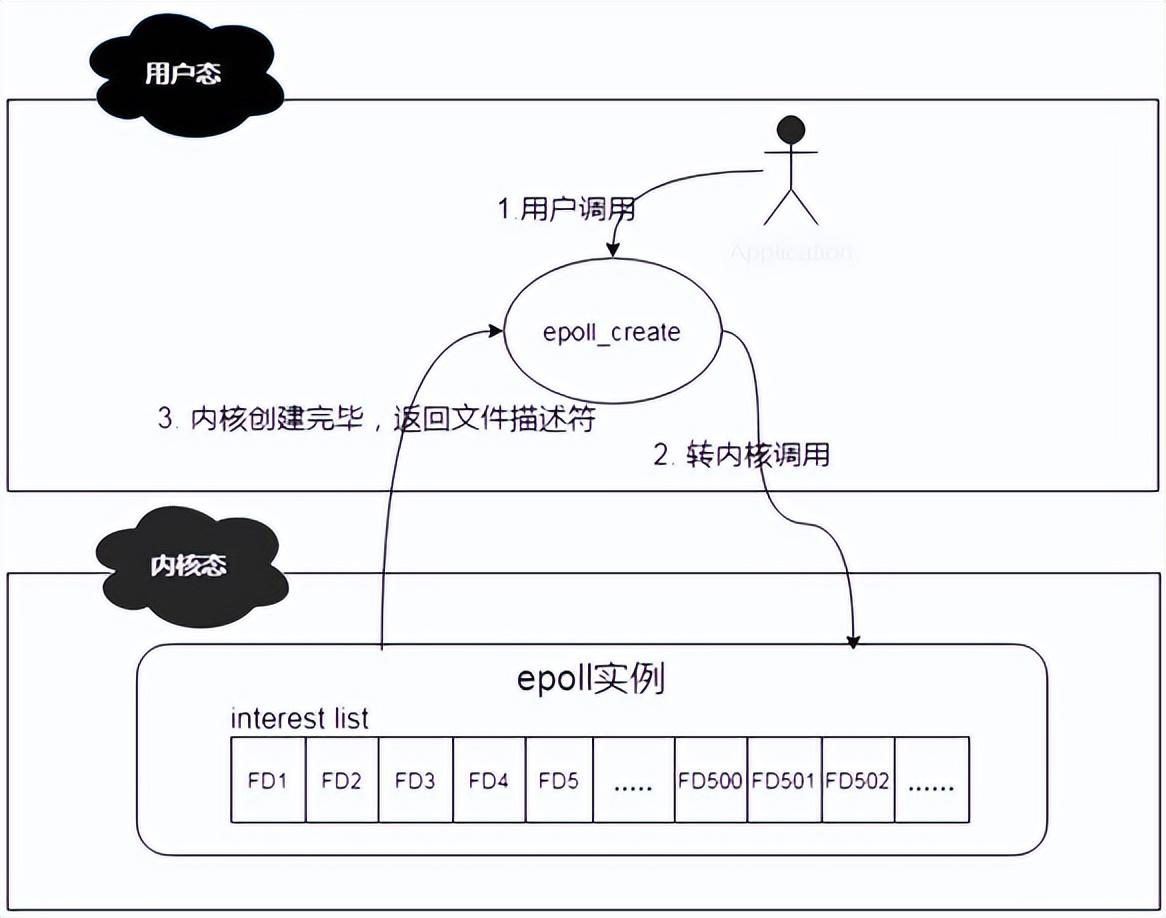
說道epoll_create函數(shù),其作用是在內(nèi)核中創(chuàng)建一個(gè)epoll數(shù)據(jù)結(jié)構(gòu)實(shí)例,然后將返回此實(shí)例在系統(tǒng)中的文件描述符。此epoll數(shù)據(jù)結(jié)構(gòu)的組成其實(shí)是一個(gè)鏈表結(jié)構(gòu),我們稱之為interest list,里面會注冊連接上來的client的文件描述符。
其簡化工作機(jī)制如下:
說道epoll_ctl函數(shù),其作用則是對epoll實(shí)例進(jìn)行增刪改查操作。有些類似我們常用的CRUD操作。這個(gè)函數(shù)操作的對象其實(shí)就是epoll數(shù)據(jù)結(jié)構(gòu),當(dāng)有新的client連接上來的時(shí)候,他會將此client注冊到epoll中的interest list中,此操作通過附加EPOLL_CTL_ADD標(biāo)記來實(shí)現(xiàn);當(dāng)已有的client掉線或者主動下線的時(shí)候,他會將下線的client從epoll的interest list中移除,此操作通過附加EPOLL_CTL_DEL標(biāo)記來實(shí)現(xiàn);當(dāng)有client的文件描述符有變更的時(shí)候,他會將events中的對應(yīng)的文件描述符進(jìn)行更新,此操作通過附加EPOLL_CTL_MOD來實(shí)現(xiàn);當(dāng)interest list中有client已經(jīng)準(zhǔn)備好了,可以進(jìn)行IO操作的時(shí)候,他會將這些clients拿出來,然后放到一個(gè)新的ready list里面。
其簡化工作機(jī)制如下:
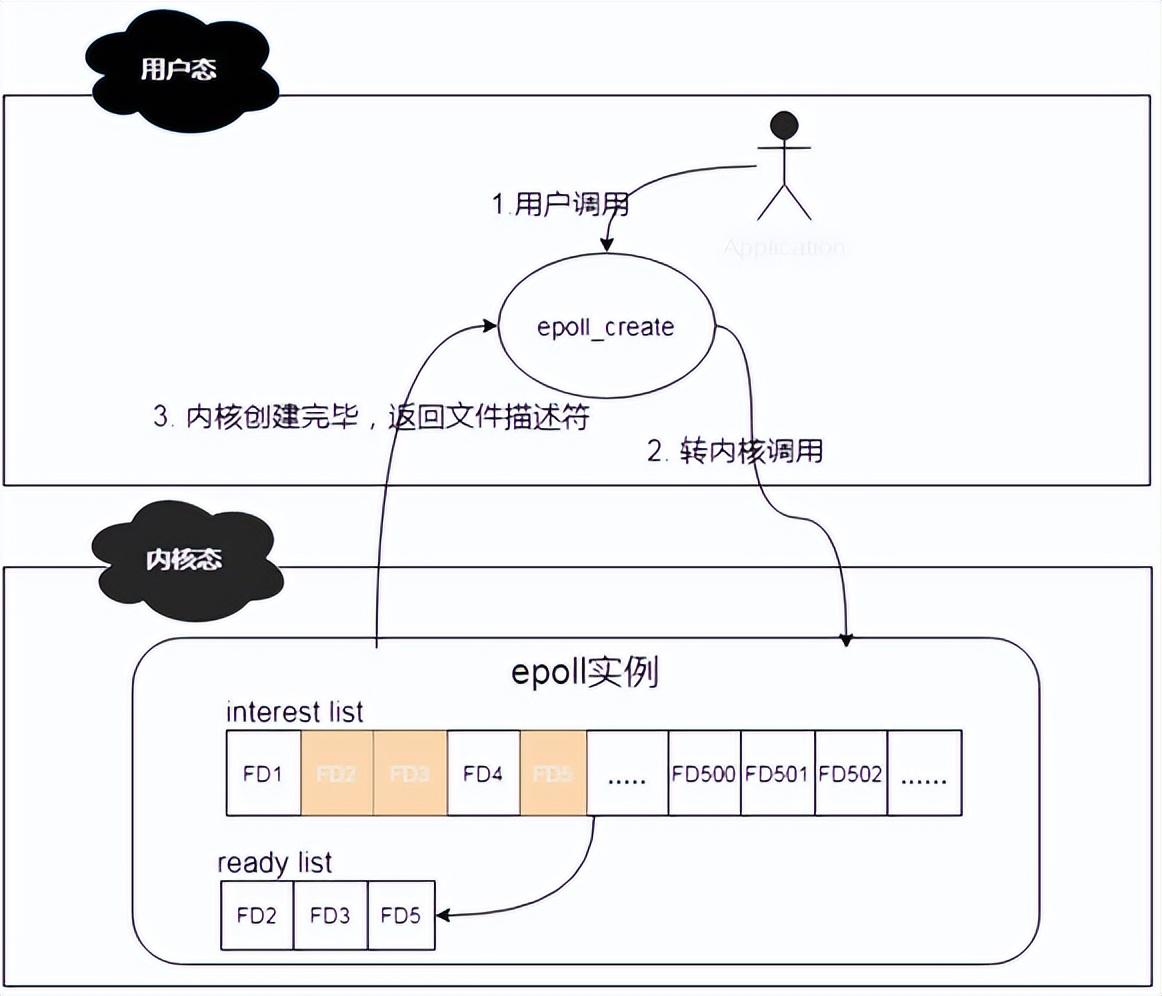
說道epoll_wait函數(shù),其作用就是掃描ready list,處理準(zhǔn)備就緒的client IO,其返回結(jié)果即為準(zhǔn)備好進(jìn)行IO的client的個(gè)數(shù)。通過遍歷這些準(zhǔn)備好的client,就可以輕松進(jìn)行IO處理了。
上面這三個(gè)函數(shù)是epoll操作的基本函數(shù),但是,想要徹底理解epoll,則需要先了解這三塊內(nèi)容,即:inode,鏈表,紅黑樹。
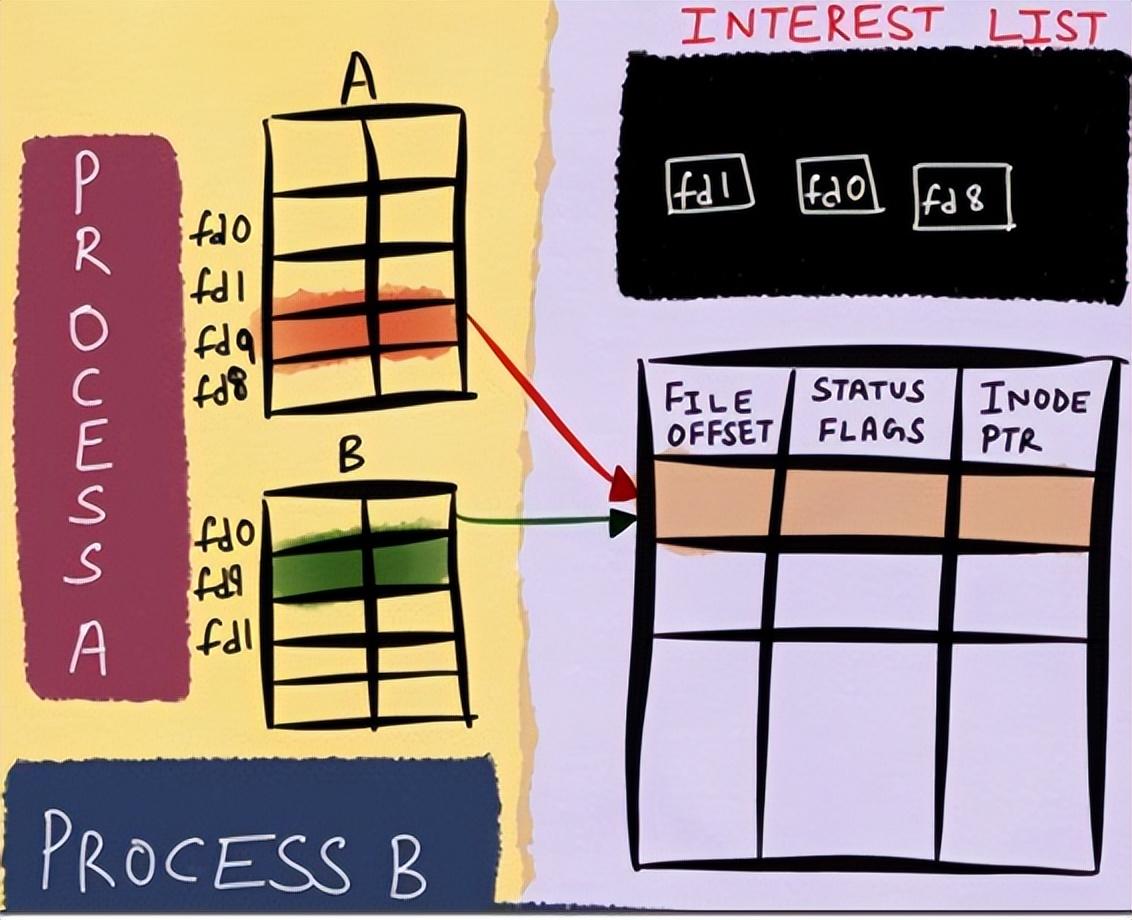
在linux內(nèi)核中,針對當(dāng)前打開的文件,有一個(gè)open file table,里面記錄的是所有打開的文件描述符信息;同時(shí)也有一個(gè)inode table,里面則記錄的是底層的文件描述符信息。這里假如文件描述符B fork了文件描述符A,雖然在open file table中,我們看新增了一個(gè)文件描述符B,但是實(shí)際上,在inode table中,A和B的底層是一模一樣的。這里,將inode table中的內(nèi)容理解為windows中的文件屬性,會更加貼切和易懂。這樣存儲的好處就是,無論上層文件描述符怎么變化,由于epoll監(jiān)控的數(shù)據(jù)永遠(yuǎn)是inode table的底層數(shù)據(jù),那么我就可以一直能夠監(jiān)控到文件的各種變化信息,這也是epoll高效的基礎(chǔ)。更多詳細(xì)信息,請參閱這兩篇文章:Nonblocking IO & The method to epoll's madness.
簡化流程如下:
數(shù)據(jù)存儲這塊解決了,那么針對連接上來的客戶端socket,該用什么數(shù)據(jù)結(jié)構(gòu)保存進(jìn)來呢?這里用到了紅黑樹,由于客戶端socket會有頻繁的新增和刪除操作,而紅黑樹這塊時(shí)間復(fù)雜度僅僅為O(logN),還是挺高效的。有人會問為啥不用哈希表呢?當(dāng)大量的連接頻繁的進(jìn)行接入或者斷開的時(shí)候,擴(kuò)容或者其他行為將會產(chǎn)生不少的rehash操作,而且還要考慮哈希沖突的情況。雖然查詢速度的確可以達(dá)到o(1),但是rehash或者哈希沖突是不可控的,所以基于這些考量,我認(rèn)為紅黑樹占優(yōu)一些。
客戶端socket怎么管理這塊解決了,接下來,當(dāng)有socket有數(shù)據(jù)需要進(jìn)行讀寫事件處理的時(shí)候,系統(tǒng)會將已經(jīng)就緒的socket添加到雙向鏈表中,然后通過epoll_wait方法檢測的時(shí)候,其實(shí)檢查的就是這個(gè)雙向鏈表,由于鏈表中都是就緒的數(shù)據(jù),所以避免了針對整個(gè)客戶端socket列表進(jìn)行遍歷的情況,使得整體效率大大提升。 整體的操作流程為:
首先,利用epoll_create在內(nèi)核中創(chuàng)建一個(gè)epoll對象。其實(shí)這個(gè)epoll對象,就是一個(gè)可以存儲客戶端連接的數(shù)據(jù)結(jié)構(gòu)。
然后,客戶端socket連接上來,會通過epoll_ctl操作將結(jié)果添加到epoll對象的紅黑樹數(shù)據(jù)結(jié)構(gòu)中。
然后,一旦有socket有事件發(fā)生,則會通過回調(diào)函數(shù)將其添加到ready list雙向鏈表中。
最后,epoll_wait會遍歷鏈表來處理已經(jīng)準(zhǔn)備好的socket,然后通過預(yù)先設(shè)置的水平觸發(fā)或者邊緣觸發(fā)來進(jìn)行數(shù)據(jù)的感知操作。
從上面的細(xì)節(jié)可以看出,由于epoll內(nèi)部監(jiān)控的是底層的文件描述符信息,可以將變更的描述符直接加入到ready list,無需用戶將所有的描述符再進(jìn)行傳入。同時(shí)由于epoll_wait掃描的是已經(jīng)就緒的文件描述符,避免了很多無效的遍歷查詢,使得epoll的整體性能大大提升,可以說現(xiàn)在只要談?wù)搇inux平臺的IO多路復(fù)用,epoll已經(jīng)成為了不二之選。
水平觸發(fā)和邊緣觸發(fā)
上面說到了epoll,主要講解了client端怎么連進(jìn)來,但是并未詳細(xì)的講解epoll_wait怎么被喚醒的,這里我將來詳細(xì)的講解一下。
水平觸發(fā),意即Level Trigger,邊緣觸發(fā),意即Edge Trigger,如果單從字面意思上理解,則不太容易,但是如果將硬件設(shè)計(jì)中的水平沿,上升沿,下降沿的概念引進(jìn)來,則理解起來就容易多了。比如我們可以這樣認(rèn)為:
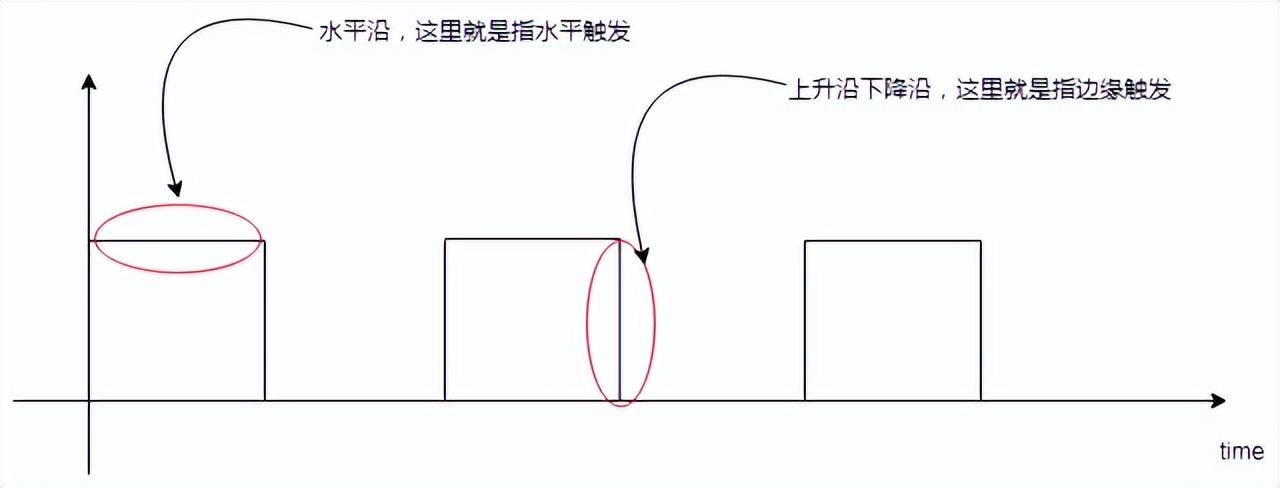
如果將上圖中的方塊看做是buffer的話,那么理解起來則就更加容易了,比如針對水平觸發(fā),buffer只要是一直有數(shù)據(jù),則一直通知;而邊緣觸發(fā),則buffer容量發(fā)生變化的時(shí)候,才會通知。雖然可以這樣簡單的理解,但是實(shí)際上,其細(xì)節(jié)處理部分,比圖示中展現(xiàn)的更加精細(xì),這里來詳細(xì)的說一下。
邊緣觸發(fā)
針對讀操作,也就是當(dāng)前fd處于EPOLLIN模式下,即可讀。此時(shí)意味著有新的數(shù)據(jù)到來,接收緩沖區(qū)可讀,以下buffer都指接收緩沖區(qū):
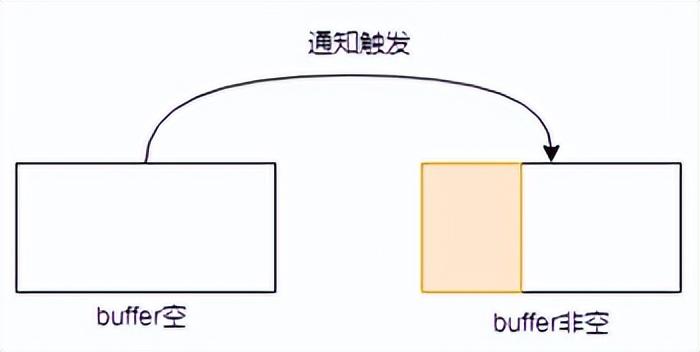
- buffer由空變?yōu)榉强眨饧从袛?shù)據(jù)進(jìn)來的時(shí)候,此過程會觸發(fā)通知。
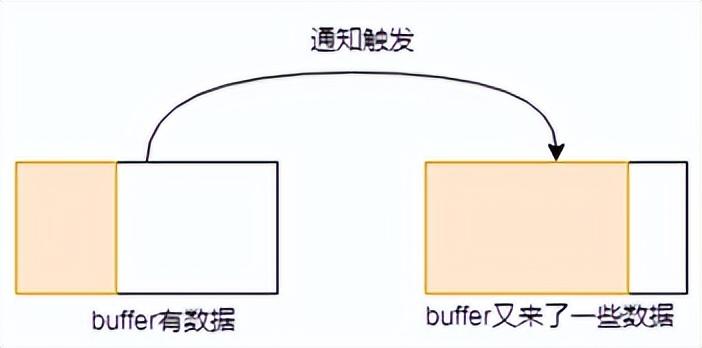
- buffer原本有些數(shù)據(jù),這時(shí)候又有新數(shù)據(jù)進(jìn)來的時(shí)候,數(shù)據(jù)變多,此過程會觸發(fā)通知。
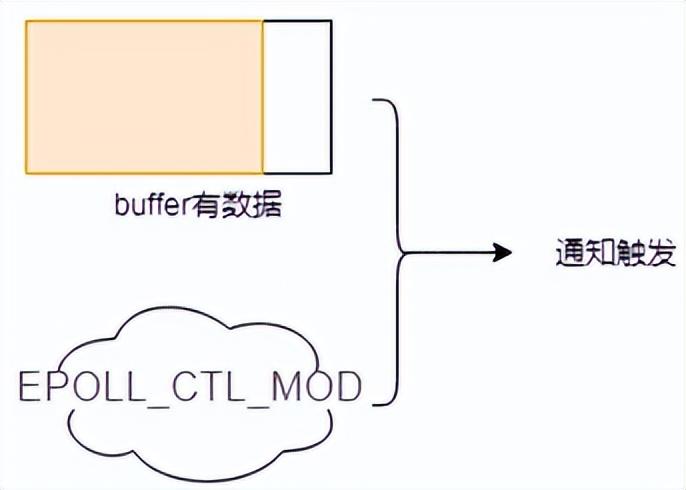
- buffer中有數(shù)據(jù),此時(shí)用戶對操作的fd注冊EPOLL_CTL_MOD事件的時(shí)候,會觸發(fā)通知。
針對寫操作,也就是當(dāng)前fd處于EPOLLOUT模式下,即可寫。此時(shí)意味著緩沖區(qū)可以寫了,以下buffer都指發(fā)送緩沖區(qū):
- buffer滿了,這時(shí)候發(fā)送出去一些數(shù)據(jù),數(shù)據(jù)變少,此過程會觸發(fā)通知。
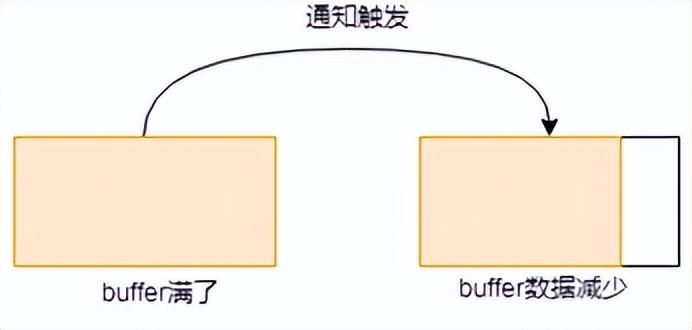
- buffer原本有些數(shù)據(jù),這時(shí)候又發(fā)送出去一些數(shù)據(jù),數(shù)據(jù)變少,此過程會觸發(fā)通知。
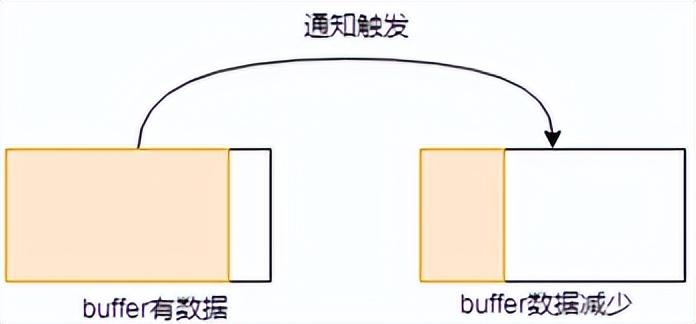
這里就是ET這種模式觸發(fā)的幾種情形,可以看出,基本上都是圍繞著接收緩沖區(qū)或者發(fā)送緩沖區(qū)的狀態(tài)變化來進(jìn)行的。
晦澀難懂?不存在的,舉個(gè)栗子:
在服務(wù)端,我們開啟邊緣觸發(fā)模式,然后將buffer size設(shè)為10個(gè)字節(jié),來看看具體的表現(xiàn)形式。
服務(wù)端開啟,客戶端連接,發(fā)送單字符A到服務(wù)端,輸出結(jié)果如下:
可以看到,由于buffer從空到非空,邊緣觸發(fā)通知產(chǎn)生,之后在epoll_wait處阻塞,繼續(xù)等待后續(xù)事件。
這里我們變一下,輸入ABCDEFGHIJKLMNOPQ,可以看到,客戶端發(fā)送的字符長度超過了服務(wù)端buffer size,那么輸出結(jié)果將是怎么樣的呢?
可以看到,這次發(fā)送,由于發(fā)送的長度大于buffer size,所以內(nèi)容被折成兩段進(jìn)行接收,由于用了邊緣觸發(fā)方式,buffer的情況是從空到非空,所以只會產(chǎn)生一次通知。
水平觸發(fā)
水平觸發(fā)則簡單多了,他包含了邊緣觸發(fā)的所有場景,簡而言之如下:
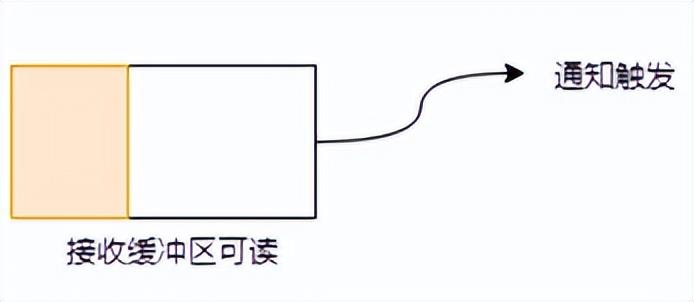
當(dāng)接收緩沖區(qū)不為空的時(shí)候,有數(shù)據(jù)可讀,則讀事件會一直觸發(fā)。
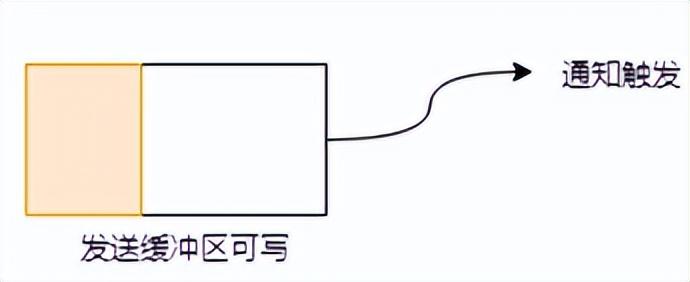
當(dāng)發(fā)送緩沖區(qū)未滿的時(shí)候,可以繼續(xù)寫入數(shù)據(jù),則寫事件一直會觸發(fā)。
同樣的,為了使表達(dá)更清晰,我們也來舉個(gè)栗子,按照上述入輸入方式來進(jìn)行。
服務(wù)端開啟,客戶端連接并發(fā)送單字符A,可以看到服務(wù)端輸出情況如下:
這個(gè)輸出結(jié)果,毋庸置疑,由于buffer中有數(shù)據(jù),所以水平模式觸發(fā),輸出了結(jié)果。
服務(wù)端開啟,客戶端連接并發(fā)送ABCDEFGHIJKLMNOPQ,可以看到服務(wù)端輸出情況如下:
從結(jié)果中,可以看出,由于buffer中數(shù)據(jù)讀取完畢后,還有未讀完的數(shù)據(jù),所以水平模式會一直觸發(fā),這也是為啥這里水平模式被觸發(fā)了兩次的原因。
有了這兩個(gè)栗子的比對,不知道聰明的你,get到二者的區(qū)別了嗎?
在實(shí)際開發(fā)過程中,實(shí)際上LT更易用一些,畢竟系統(tǒng)幫助我們做了大部分校驗(yàn)通知工作,之前提到的SELECT和POLL,默認(rèn)采用的也都是這個(gè)。但是需要注意的是,當(dāng)有成千上萬個(gè)客戶端連接上來開始進(jìn)行數(shù)據(jù)發(fā)送,由于LT的特性,內(nèi)核會頻繁的處理通知操作,導(dǎo)致其相對于ET來說,比較的耗費(fèi)系統(tǒng)資源,所以,隨著客戶端的增多,其性能也就越差。
而邊緣觸發(fā),由于監(jiān)控的是FD的狀態(tài)變化,所以整體的系統(tǒng)通知并沒有那么頻繁,高并發(fā)下整體的性能表現(xiàn)也要好很多。但是由于此模式下,用戶需要積極的處理好每一筆數(shù)據(jù),帶來的維護(hù)代價(jià)也是相當(dāng)大的,稍微不注意就有可能出錯(cuò)。所以使用起來須要非常小心才行。
至于二者如何抉擇,諸位就仁者見仁智者見智吧。
行文到這里,關(guān)于epoll的講解基本上完畢了,大家從中是不是學(xué)到了很多干貨呢? 由于從netty研究到linux epoll底層,其難度非常大,可以用曲高和寡來形容,所以在這塊探索的文章是比較少的,很多東西需要自己照著man文檔和源碼一點(diǎn)一點(diǎn)的琢磨(linux源碼詳見eventpoll.c等)。這里我來糾正一下搜索引擎上,說epoll高性能是因?yàn)槔胢map技術(shù)實(shí)現(xiàn)了用戶態(tài)和內(nèi)核態(tài)的內(nèi)存共享,所以性能好,我前期被這個(gè)觀點(diǎn)誤導(dǎo)了好久,后來下來了linux源碼,翻了一下,并沒有在epoll中翻到mmap的技術(shù)點(diǎn),所以這個(gè)觀點(diǎn)是錯(cuò)誤的。這些錯(cuò)誤觀點(diǎn)的文章,國內(nèi)不少,國外也不少,希望大家能審慎抉擇,避免被錯(cuò)誤帶偏。
所以,epoll高性能的根本就是,其高效的文件描述符處理方式加上頗具特性邊的緣觸發(fā)處理模式,以極少的內(nèi)核態(tài)和用戶態(tài)的切換,實(shí)現(xiàn)了真正意義上的高并發(fā)。