比開源快30倍的自研SQL Parser設計與實踐
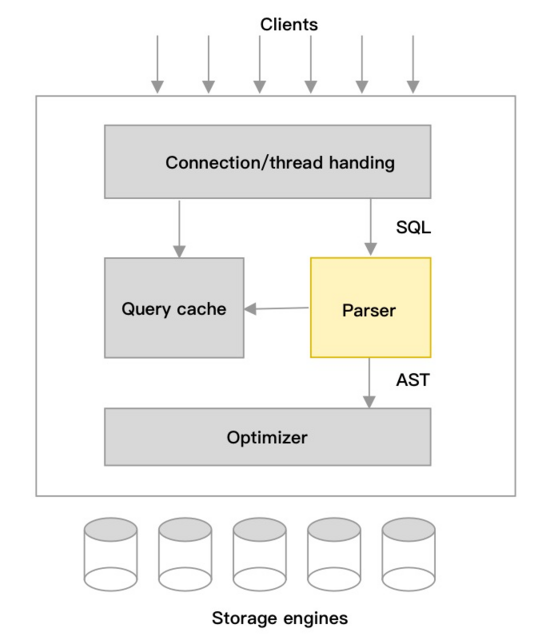
SQL(Structured Query Language)作為一種領域語言(編程語言),最早用于關系型數據庫,方便管理結構化數據;SQL由多種不同的類型的語言組成,包括數據定義語言,數據控制語言、數據操作語言;各數據庫產品都有不同的聲明和實現;用戶可以很方便的使用SQL操作數據,數據庫系統中的詞法語法分析器負責分析和理解SQL文本的含義,包括詞法分析、語法分析、語義分析3部分。經過詞法語法分析器生成AST(Abstract Syntax Tree),會被優化器處理生成生成執行計劃,再由執行引擎執行,下圖以MySQL架構為例展示詞法語法分析器所處的位置。
本文通過介紹詞法語法分析器技術和業界的做法,以及過去使用自動生成的詞法語法分析器遇到的問題,分享自研SQL Parser的設計與實踐,以及其帶來的性能和功能的提升。
一、業界產品如何開發SQL Parser?
按照解析器代碼開發方式,可分為以下兩種:
1.自動生成
為方便開發詞法、語法分析的過程,業界有許多詞法、語法分析工具,例如:Flex、Lex、Bison工具常用于生成以C、C++作為目標語言的詞法、語法代碼;如果以Java作為目標語言,可以使用比較流行的ANTLR和JavaCC等工具,ANTLR、JavaCC工具都以用戶編寫的詞法語法規則文件作為輸入,其中語法文件需要滿足EBNF(extended Backus–Naur form)[1]語法規則, 這2個工具使用LL(k) (Left-to-right, Leftmost derivation)[2] 算法“自頂向下[3]”解析SQL文本并構建SQL AST, Presto,Spark、Hive等數據庫和大數據系統多采用該方式生成。生成的代碼包含詞法和語法解析部分,語義分析還需要結合Meta數據,各數據庫內核自己處理;更多自動生成工具的功能和算法對比[4]在參考文獻中。
2.手工編寫
與自動生成工具不同,InfluxDB、H2、Clickhouse等流行的數據庫的SQL Parser組件均是手工編寫而成。
優點:
-
代碼邏輯清晰,方便開發人員調試和排錯;
-
性能更好:有更多代碼優化的空間交給開發人員,可以使用更優秀的算法和數據結構提升性能;
-
自主可控:無licence約束,可讀性和可維護性更高;
-
不需要額外依賴第三方詞法語法代碼生成工具。
不足:
-
對開發人員的技術要求較高,需了解編譯原理技術;
-
開發工作量較大,實現MySQL常用語法的各類分支,需要投入很多時間和精力;
-
需要長時間、大規模測試才會趨于穩定。
二、問題與挑戰
1.復雜查詢的性能問題
在實時分析型數據庫的實際生產環境中,經常需要處理數以千行的復雜查詢請求或者深層嵌套的查詢請求,自動生成的解析器,由于狀態機管理復雜,線程堆棧太深,導致個別查詢請求在詞法語法解析階段性能下降嚴重。
2.大批量寫入吞吐問題
分析型數據庫要穩定處理大批量、高并發寫入的場景,要求SQL Parser組件有很好的性能和穩定性,我們嘗試使用過ANTLR,JavaCC等工具生成SQL 的詞法語法解析器,大批量寫入時,values子句在解析過程會產生太多AST臨時對象,導致垃圾回收耗時的問題。
3.Query Rewriting的靈活性問題
需要快速方便的遍歷AST樹,找到符合某種規則的葉子節點,修改改節點,自動生成的解析器并不能很靈活的支持。
自動生成的代碼可讀性差,排查問題成本高,復雜查詢場景下,性能不足,影響系統穩定性和版本迭代速度;在設計之初,我們放棄了自動生成的技術方案,完全手工編寫詞法語法解析器。
三、自研詞法語法分析器的技術要點
自動生成工具主要處理生成下圖中左側的 SQL Parser Core和 SQL Tree Nodes的部分,右側featrues的部分需要開發同學處理,當右側功能(例如:SQL rewriting)對左側有的Tree nodes的更改功能有更多的需求時,想修改自動生成的代碼,則無從下手。
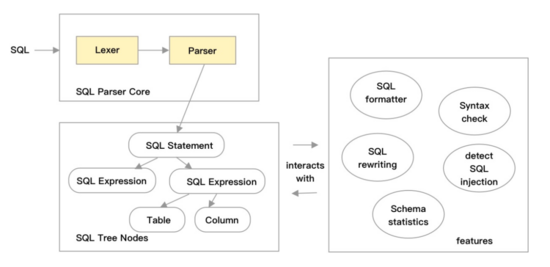
自動生成工具是面向生成通用語法解析器而設計的,針對SQL這一特定領域語言,有特定的優化技術提升穩定性和性能,從設計之初,我們選擇LL(k)作為語法分析的算法,其自頂向下的特性,在手工編寫分析器時,邏輯清晰,代碼易讀,方便開發和維護,LL(k)的“左遞歸”問題,可通過手工判定循環編程的方式避免。
1.詞法和語法分析
詞法分析中,Lexer持續讀取連續SQL 文本,將具有某特征的一段連續文本標識為Token,并標識Token的類別,比如賦值語句 x = 30,經過詞法分析后x, = , 30 分別被標識為ID、等號操作符、數值常量;尤其在識別標識符(變量,表名,列名等)和保留字(TABLE,FROM,SELECT等)需要對字符串進行反復對比。自動生成工具在這一階段使用DFA(Deterministic Finite Automaton)和預先定義的詞法文件,確定每個Token的值和類型,手工編寫解析器不需要額外維護一個狀態機,使用分支預測,減少計算量和調用堆棧的深度。
語法分析器會使用詞法分析中的Token作為輸入,以SQL語法描述作為規則,自頂向下,依次將非葉子節點展開,構建語法樹,整個過程就像是走迷宮,只有一個正確入口和出口,走完迷宮后,會生成一個正確的AST。
快速Token比較
- selECT c1 From T1;
由于大部分數據庫系統對大小寫不敏感,上述query中 selECT 和 From 會被識別為保留字,c1和T1會被識別為標識符。識別2者的類型不同,字符串匹配操作是必不可少的,通常將字符統一轉為大寫或者小寫,再比較字面值,是一個可行的方案。首先把數據庫保留字按照 Map<String, Token> 初始化在內存里,key是保留字的大寫字符串,value是Token類型;其中key在作大寫轉化時,可使用ASCII值+32的方法取代 toUpperCase() 方法,在不影響正確性的前提下,獲得數倍性能提升。
快速數值分析
在解析常量值時,通常的做法是讀取SQL中的字符串,把字符串作為參數,調用Java自帶的 Integer.parseInt() / Float.parseFloat() / Long.parseLong() ,可以直接在原文本上邊讀取邊計算數值,該過程只使用基礎類型,避免構造字符串,可以節省內存,又提升了解析速度,該優化對大批量寫入數值的場景優化非常明顯。
避免回溯 [5]
SQL語法解析過程中,通常只需要預讀一個Token,就可以決定如何構建語法節點的關系,或者構建哪種語法節 點,有些語法分支較多,需要預讀2個及以上的Token才可以做出判斷,預讀多個Token可以降低回溯帶來的性能消耗,極少情況下,2個以上的Token預讀都也沒有匹配到正確的語法分支,需要撤銷預讀,走其他分支; 為了提高撤銷的速度,可以在預讀前保存Token位點,撤銷時,可以快速回到保存點。
在insert into values語句中,出現常量字面值的概率比出現其他的token要高,通過分支預測可以減少判斷邏輯,避免回溯,提升性能。
表達式替換
Query rewriting[6]技術基于“關系代數”修改AST,保證正確性的前提下,使新的AST在具備更好的執行性能,例如:A,B兩張表的大小相差懸殊,而且錯誤的Join順序對數據庫系統不友好,通過更改A,B表的Join順序可以獲得更高的執行性能。使用工具生成的解析器,通常不允許直接更改AST的節點,每次更改AST某個節點都需要重新構建整個AST,性能并不好。自研的Parser中,每個AST節點類實現都replace接口,只需要修改AST中的子樹就可以達到改寫的目的。
- public interface Replaceable {
- boolean replace(Node expr, Node target);
- }
- public class BetweenNode implements Replaceable {
- public Node beginExpr;
- public Node endExpr;
- @Override
- public int hashCode(){...}
- @Override
- public boolean equals(Object obj) {...}
- @Override
- public boolean replace(SQLExpr expr, SQLExpr target) {
- if (expr == beginExpr) {
- setBeginExpr(target);
- return true;
- }
- if (expr == endExpr) {
- setEndExpr(target);
- return true;
- }
- return false;
- }
- }
其他優化
-
支持AST Clone:如果保持原AST結構不變,克隆出一個新的AST,在新的AST修改節點結構,比如:增加Hint,刪減where條件,增加limit 限制等。
-
維護AST 父子關系:自動生成的解析器維護了父到子節點的關系,是單向的引用關系。手寫代碼可以增加子節點對父節點的引用,構建AST節點的雙向引用關系,實現節點的快速“回跳”,使得AST的遍歷效率更高。
- public abstract class Node {
- public abstract List<Node> getChildren()
- }
- public class BetweenNode extends Node {
- public Node beginExpr;
- public Node endExpr;
- @Override
- public List<Node> getChildren() {
- return Arrays.<Node>asList(beginExpr, this.endExpr);
- }
- @Override
- public BetweenNode clone() {
- BetweenNode x = new BetweenNode();
- if (beginExpr != null) {
- x.setBeginExpr(beginExpr.clone());
- }
- if (endExpr != null) {
- x.setEndExpr(endExpr.clone());
- }
- return x;
- }
- public void setBeginExpr(Node beginExpr) {
- if (beginExpr != null) {
- beginExpr.setParent(this);
- }
- this.beginExpr = beginExpr;
- }
- public void setEndExpr(Node endExpr) {
- if (endExpr != null) {
- endExpr.setParent(this);
- }
- this.endExpr = endExpr;
- }
- }
2.語義分析
寫入事件回調
前面提到大批量導入數據時,詞法語法分析階段會產生很多AST小對象,給垃圾回收帶來壓力,解決這個問題的核心是要盡量使用基礎數據類型,盡量不要產生AST 節點對象。需要從詞法分析階段入手,避免進入語法分析階段。在詞法分析階段,允許外部注冊實現了寫入接口的類,每當詞法分析器解析出values中的每個具體值,或者完整解析出values中的一行,同時回調寫入接口,實現數據庫寫入邏輯。
- public interface InsertValueHandler {
- Object newRow() throws SQLException;
- void processInteger(Object row, int index, Number value);
- void processString(Object row, int index, String value);
- void processDate(Object row, int index, String value);
- void processDate(Object row, int index, java.util.Date value);
- void processTimestamp(Object row, int index, String value);
- void processTimestamp(Object row, int index, java.util.Date value);
- void processTime(Object row, int index, String value);
- void processDecimal(Object row, int index, BigDecimal value);
- void processBoolean(Object row, int index, boolean value);
- void processNull(Object row, int index);
- void processFunction(Object row, int index, String funcName, Object... values);
- void processRow(Object row);
- void processComplete();
- }
- public class BatchInsertHandler implements InsertValueHandler {
- ...
- }
- public class Application {
- BatchInsertHandler handler = new BatchInsertHandler();
- parser.parseInsertHeader(); // 頭部:解析 insert into xxx values 部分
- parser.parseValues(handler); // 批量值:values (xxx), (xxx), (xxx) 部分
- }
Query Rewriting
手動編寫的SQL Parser可以更靈活的與優化器配合,將Query rewriting 的部分優化能力前置化到SQL Parser中實現,使得優化器能更加專注于基于代價和成本的優化上。Parser可以結合Meta信息,利用“等價關系代數”,在AST上低成本實現Query Rewriting功能,以提升查詢性能,例如:常量折疊、函數變換、條件下推或上提、類型推導、隱式轉化、語義去重等。
首先,需要設計一個結構存儲catalog和table結構信息,包括庫名,表名,列名,列類型等。
然后,使用“訪問者模式”編寫Visitor程序,通過“深度優先”遍歷AST,對字段、函數、表達式、操作符進行分析,結合表結構和類型信息,推斷表達式類型,注意,嵌套的查詢語句中,相同的表達式出現的位置不同,所屬的作用域也不同。
最后,AST會經過使用“等價關系代數”編寫的RBO(Rule-Based Optimization)規則處理,達到優化器的目的。
- -- 常量折疊示例
- SELECT * FROM T1
- WHERE c_week
- BETWEEN CAST(date_format(date_add('day', -day_of_week('20180605'),
- date('20180605')), '%Y%m&d') as bigint)
- AND CAST(date_format(date_add('day', -day_of_week('20180606'),
- date('20180606')), '%Y%m&d') as bigint)
- ------------折疊后-----------
- SELECT * from T1
- WHERE c_week BETWEEN 20180602 and 20180603
- -- 函數轉換示例
- SELECT * FROM T1
- WHERE DATE_FORMAT(t1."pay_time", '%Y%m%d') >= '20180529'
- AND DATE_FORMAT(t1."pay_time", '%Y%m%d') <= '20180529'
- -----------轉化后, 更好利用索引------------
- SELECT * FROM T1
- WHERE t1."pay_time" >= '2018-05-29 00:00:00'
- AND t1."pay_time" < '2018-05-30 00:00:00'
四、最后
優化后的SQL Parser的性能和穩定性提升明顯,以TPC-DS[7] 99個Query對比來看,手工編寫的SQL Parser比ANTLR Parser(使用ANTLR生成)速度快20倍,比JSQLParser(使用JavaCC生成)速度快30倍,在批量Insert場景下,速度提升30~50倍。
本文通過介紹自動生成工具生成的詞法語法分析器和自研分析器的利弊權衡和思考,結合OLAP的大吞吐,處理復雜SQL的業務特性,選擇手工編寫解析器。性能優化手段貼近SQL解析的特點;在語義分析層面,結合Schema信息沉淀了很多語義分析工具,在離線或在線SQL統計和特征分析方面更輕量化、便捷。