Julia開源新框架SimpleChain:小型神經網絡速度比PyTorch快5倍!
?Julia從一出生開始,就瞄準了科學計算領域,并且一直在與Python暗中較量。
在神經網絡的框架上,Python有PyTorch和TensorFlow,幾乎是深度學習開發的首選框架,并且獲得了Meta和Google在技術和資金上的支持,蓬勃發展。
雖然Julia也有Flux.jl框架,但Julia社區一直依賴于語言本身的高性能產生的生產力,所以Flux.jl的代碼量相比Python框架來說,可以稱得上是特別「苗條」了,例如PyTorch和TensorFlow包括了整個獨立的語言和編譯器(torchscript、XLA等),而Flux.jl僅僅由Julia語言編寫。

當然,世界上沒有免費的午餐,如果以不同的視角來看,想要在機器學習領域開發出一個簡單、通用且高性能的框架幾乎是不可能的,只能不斷權衡。
比如對于一個特定的問題,如果需要稀疏的小模型,想要獲得最高性能的方法就是重寫一遍,而非采用通用框架。
最近Julia社區又開源了一個新框架SimpleChains.jl,在小模型場景下相比PyTorch最少能提速5倍。
代碼鏈接:https://github.com/PumasAI/SimpleChains.jl
開發人員表示,這個框架不會對所有人都有用,但對那些需要它的人來說,它是非常有用的。
有網友表示十分贊同:「不同的任務用不同的工具」,因為TF和pyTorch消耗了大量的內存,并且沒有原地操作,所以在小模型上很浪費時間。他數年前在Netflex時就設計開發了一個D語言的框架vectorflow,目前在github已獲1200個stars

機器學習模型的假設
SimpleChains.jl是由Pumas-AI和Julia Computing與Roche和馬里蘭大學巴爾的摩分校合作開發的一個庫,它的主要目的就是為小型神經網絡提供盡可能高的性能。
SimpleChains.jl最開始用于在醫療數據分析中用于科學機器學習(SciML)的解決方案:小型神經網絡(和其他近似器,如傅里葉數列或切比雪夫多項式展開)可以與已知的半生理學模型(semi-physiologic models)相結合,發現以前未知的機制和預后因素。
從黑洞動力學到地震安全建筑的開發,SciML方法的有效性已經在許多學科中得到證實,能夠靈活地發現/指導(生物)物理方程。
應用場景變化太大,在這種情況下,使用一些專用(specialization)的神經網絡才有可能提升模型的運行性能。
具體來說,在機器學習模型的研究中,通常依賴于一個假設:神經網絡足夠大,其中矩陣乘法(如卷積)的O(n^3)時間成本占了運行時間的絕大部分,這基本上也是機器學習庫的大部分機制背后的4大指導原則:
1. 矩陣乘法的復雜度是立方的,而內存分配的規模是線性的,所以用非分配(non-allocating)內存的方式來操作向量的優先級并不高;
2. 目前AI加速的工作主要集中于GPU內核加速,讓指令運行盡可能快,由于這些大型矩陣-矩陣操作在GPU上是最快的,并且也是大模型的主要瓶頸,所以性能基準基本上只是衡量這些特定內核的速度;
3. 當做自動微分反向傳播時,將數值復制到內存的操作幾乎感覺不到,內存分配被較大的內核調用所隱藏;
4. 用戶可以隨意寫一個tape來生成反向傳播,雖然增加了在前向過程中建立字典的成本,但是也會被更大的內核調用所掩蓋。
但,這些假設在真實的案例中是否真的能全部成立?
如果不成立的話,能不能把重點放在這些方面的改進,從而提升更高的運算性能?
小型神經網絡的瓶頸在哪?
對于初學者來說,可以先測試一下假設1和2,通過一段Julia代碼來測試內存申請時間、GPU運算時間等。
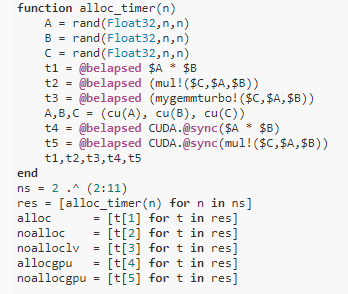
可以看到當我們進行較大的矩陣乘法操作時,比如100x100*100x100,基本可以忽略由于內存分配而產生的任何開銷。
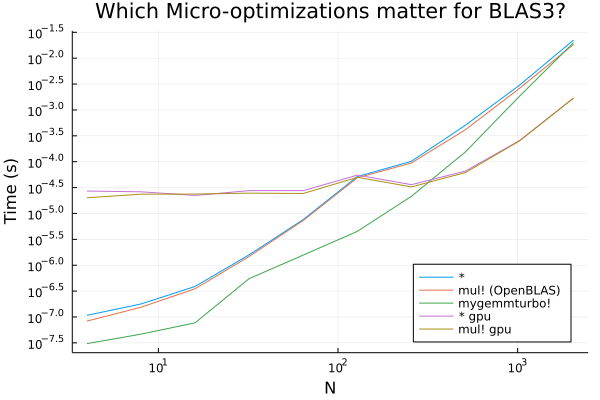
但同時也可以看到,在lower end有可能出現一些相當顯著的性能提升,這些收益是通過使用純Julia LoopVectorization.jl實現的,因為標準的BLAS工具在這個區域往往有額外的線程開銷(同樣,在這個區域沒有進行優化)。
如果你一直在利用GPU帶來的好處而不去研究細節,那么這個事實可能會讓你大吃一驚!GPU被設計成具有許多內核的慢速芯片,因此它們只對非常并行的操作有效,例如大型矩陣乘法。正是從這一點出發,假設2可以被認為是大型網絡操作。
但同樣,在小網絡的情況下,由于缺乏并行計算,使用GPU內核的性能可能還不如設計良好的CPU內核。
矩陣操作只有在能夠使用批處理(A*B中的B矩陣的每一列都是一個單獨的批處理)時才會發生。
在大部分科學機器學習的情境下,如ODE鄰接中的向量Jacobian乘積的計算,這種操作是矩陣-向量乘法。這些操作的時間復雜度只有O(n^2),在這種情況下內存開銷會被放大。
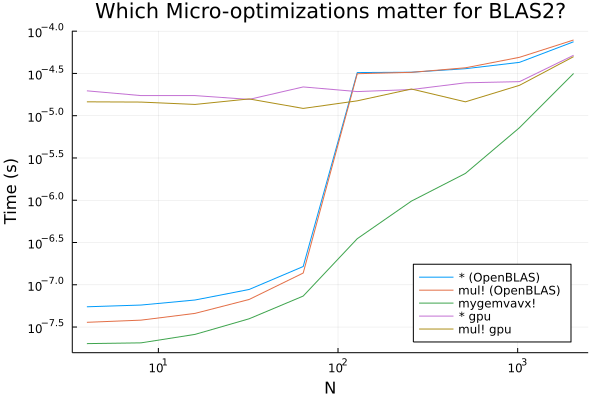
神經網絡的基本操作是Sigma,所以還有一個O(n)時間復雜度的操作,這種情況下內存開銷顯得更嚴重。
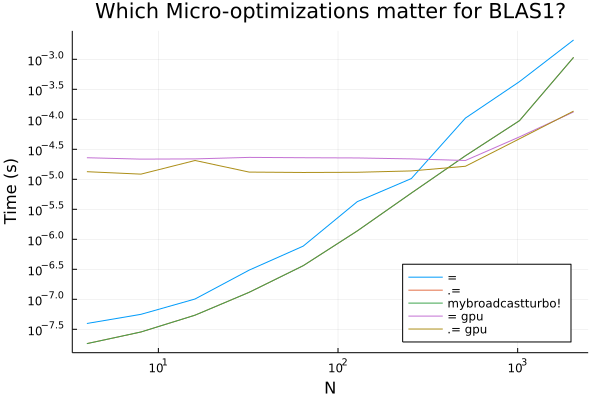
對于假設3和4來說,需要更加關注反向傳播的實現。不同機器學習庫的自動微分方法也存在著區別。有些庫是立刻反向傳播梯度值,也有些需要把梯度保存起來,這樣就又需要額外的內存開銷操作了。

在特定的應用里面,如果知道梯度立刻傳播,就可以立即計算梯度,相比通用實現來說,只需要一個緩存向量解千愁,原地賦值,這樣的話所有自動微分的額外開銷都沒有了。

基于這些想法,研究人員開源了SimpleChains.jl,可以很好地解決這類優化問題,可以在CPU上快速擬合和優化小模型,早期的神經網絡原型模型設計大多都希望:
1. 達到更好的性能,最好能達到CPU的峰值FLOPs;
2. 專注于小尺寸的模型,在早期開發階段放棄一些針對大型模型的內核優化操作(如緩存平鋪);
3. 有一個API,其中的向量的參數和梯度都是first class,以便更容易地與各種優化器或求解器(如BFGS)協同工作;
4. 使用「純Julia」編寫,更方便開發和優化;在大量使用LoopVectorization.jl的同時,SimpleChains.jl并不依賴任何BLAS或NN庫。
開發人員的長期目標是將這種循環編譯器的優化方法擴展到自動產生pullbacks。但這種以編譯器為中心的方法已經被用于實現的便利性:雖然我們仍然需要手寫梯度,但我們不需要對它們進行手工優化。
SimpleChains.jl的實際性能怎么樣?
研究人員用一個2×2的矩陣做了一個實驗,在帶有AVX512指令集的Intel i9-10980XE跑了一下,1萬個epoch花了0.41秒,相比之下pyTorch花了15秒,也就是說在這種微型神經網絡上,提速大約35倍。

把實驗換到AMD EPYC 7513 帶有AVX2指令的機器上,Julia的實現花費時間為0.72秒,而PyTorch的實現則需要70秒,差距拉升到了100倍。
研究人員又在AMD Ryzen 9 5950X實驗了一份Jax代碼,Julia耗時為1.3秒,Jax則需要14秒,提升約10倍。
換到Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz 平臺上,Jax耗時為9秒,Julia需要0.4秒,大約22倍提升。
再換到差一點的處理器,6核CPU上,Jax需要19秒,而Julia需要9秒,速度提升就只有2倍了。
在稍微大一點的、實際可用的神經網絡上,訓練速度還會有這么大的差距嗎?
研究人員用LeNet5來測試MNIST,這個例子只是一個非常保守的速度估計,因為在更傳統的機器學習用例中,批處理可以使用矩陣乘法,不過即使在這種情況下,由于semi-small的網絡規模,也能看到大量的性能優勢。

在batch size為2048的情況下訓練10個epoch,用PyTorch在A100上訓練兩次耗時為17.66和17.62,準確率分別為94.91%和96.92%;在V100上訓練時間為16.29和15.94,準確率分別為95.6%和97.5%
不過這個問題對于GPU來說還是殺雞用牛刀了,在2048的batch size上運算速度還是很快,時間主要耗費在CPU轉移到GPU上了。
在AMD EPYC 7513和Intel i9 10980XE又進行了兩次實驗,結果比GPU更快,準確率也更高。
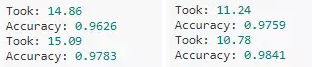
換到SimpleChains.jl,在AMD平臺上耗時為3秒,準確率98.3%;在Intel平臺上,耗時僅為1秒,準確率為98.2%;即使在筆記本的Intel平臺上,耗時也僅為5.3秒,準確率97%
目前大型機器學習框架在專注于為其99.9%的用戶提供一流的性能方面做得非常好,但在另外0.1%的小模型用戶手里,框架卻不好用。
這就是可組合性和靈活性的優勢:一種允許你輕松構建機器學習框架的語言,也是一種允許你構建替代框架的語言,這些框架針對替代人群進行優化。?