













AntPathMatcher路徑匹配器,Ant風格的URL
前言
你好,我是YourBatman。
- @RequestMapping的URL是支持Ant風格的
- @ComponentScan的掃描包路徑是支持Ant風格的
- @PropertySource導入資源是支持Ant分隔的(如:classpath:app-*.properties)
- ...
在描述路徑時有個常見叫法:Ant風格的URL。那么到底什么是Ant風格?關于這個概念,我特地的谷歌一下、百度一下、bing一下,無一所獲(沒有一個確切的定義),難道這個盛行的概念真的只能意會嗎?
直到我在Spring中AntPathMatcher的描述中看到一句話:這是從Apache Ant借用的一個概念。“年輕”的朋友可能從沒用過甚至沒聽過Ant,它是一個構建工具,在2010年之前發揮著大作用,但之后逐漸被Maven/Gradle取代,現已幾乎銷聲匿跡。雖然Ant“已死”,但Ant風格似乎要千古。借助Spring強大的號召力,該概念似乎已是規范一樣的存在,大家在不成文的約定著、交流著、書寫著。
那么,既然Ant風格貫穿于開發的方方面面,懷著一知半解的態度使用著實為不好。今天咱們就深入聊聊,進行全方位的講解。
所屬專欄
點撥-Spring技術棧
本文提綱
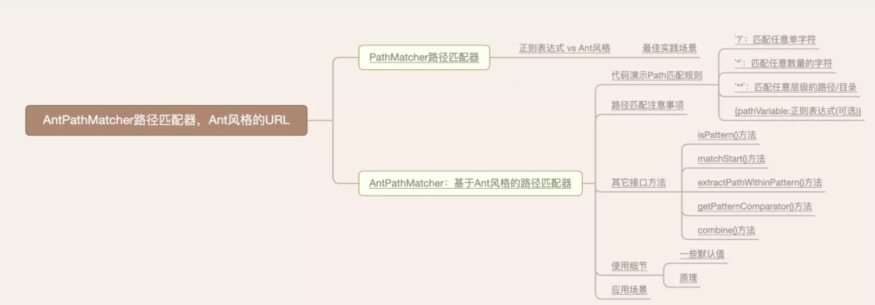
版本約定
- JDK:8
- Spring Framework:5.3.x
正文
在Spring 5之前,Spring技術棧體系內幾乎所有的Ant風格均由AntPathMatcher提供支持。
PathMatcher路徑匹配器
PathMatcher是抽象接口,該接口抽象出了路徑匹配器的概念,用于對path路徑進行匹配。它提供如下方法:
❝細節:PathMatcher所在的包為org.springframework.util.PathMatcher,屬于spring-core核心模塊,表示它可運用在任意模塊,not only for web。❞
- // Since: 1.2
- public interface PathMatcher {
- boolean isPattern(String path);
- boolean match(String pattern, String path);
- boolean matchStart(String pattern, String path);
- String extractPathWithinPattern(String pattern, String path);
- Map<String, String> extractUriTemplateVariables(String pattern, String path);
- Comparator<String> getPatternComparator(String path);
- String combine(String pattern1, String pattern2);
- }
一個路徑匹配器提供這些方法在情理之中,這些方法見名知意理解起來也不難,下面稍作解釋:
- boolean isPattern(String path):判斷path是否是一個模式字符串(一般含有指定風格的特殊通配符就算是模式了)
- boolean match(String pattern, String path):最重要的方法。判斷path和模式pattern是否匹配(注意:二者都是字符串,傳值不要傳反了哈)
- boolean matchStart(String pattern, String path):判斷path是否和模式pattern前綴匹配(前綴匹配:path的前綴匹配上patter了即可,當然全部匹配也是可以的)
- String extractPathWithinPattern(String pattern, String path):返回和pattern模式真正匹配上的那部分字符串。舉例:/api/yourbatman/*.html為pattern,/api/yourbatman/form.html為path,那么該方法返回結果為form.html(注意:返回結果永遠不為null,可能是空串)
- Map
- String combine(String pattern1, String pattern2):合并兩個pattern模式,組合算法由具體實現自由決定
該接口規定了作為路徑匹配器一些必要的方法,同時也開放了一些行為策略如getPatternComparator、combine等由實現類自行決定。或許你還覺得這里某些方法有點抽象,那么下面就開始實戰。
正則表達式 vs Ant風格

正則表達式(regular expression):描述了一種字符串匹配的模式(pattern),可以用來檢查一個串是否含有某種子串、將匹配的子串替換或者從某個串中取出符合某個條件的子串等。
正則表達式是由普通字符(例如字符a到z)以及特殊字符(又稱"元字符")組成的文字模式。重點是它的元字符,舉例說明:
- ?:匹配前面的子表達式零次或一次
- *:匹配前面的子表達式零次或多次
- +:匹配前面的子表達式一次或多次
- .:匹配除換行符 \n 之外的任何單字符
- ...
正則表達式幾乎所有編程語言都支持的通用模式,具有普適性(適用于任意字符串的匹配)、功能非常強大等特點。除此之外正則表達式還有“重”、“難”等特點,具有一定上手門檻、高并發情況下執行效率低也都是它擺脫不了的“特性”。

Ant風格(Ant Style):該風格源自Apache的Ant項目,若你是個“老”程序員或許你還用過Apache Ant,若你是個小鮮肉也許聞所未聞,畢竟現在是Maven(Gradle)的天下。
Ant風格簡單的講,它是一種精簡的匹配模式,僅用于匹配路徑or目錄。使用大家熟悉的(這點很關鍵)的通配符:

看到沒,這才比較符合咱們的習慣:*代表任意通配符才是正解嘛,而不是像正則一樣代表匹配的數量來得讓人“費解”。
❝**直接用于目錄級別的匹配,可謂對URL這種字符串非常友好❞
最佳實踐場景
正則表達式具有功能非常強大的特性,從理論上來講,它可以用于任何場景,但是有些場景它并非最佳實踐。
舉個例子:在自定義的登錄過濾器中,經常會放行一些API接口讓免登錄即可訪問,這是典型的URL白名單場景,這個時候就會涉及到URL的匹配方式問題,一般會有如下方案:
- 精確匹配:url.equals("/api/v1/yourbatman/adress")。缺點:硬編碼式一個個羅列,易造成錯誤且不好維護
- 前綴匹配:url.startsWith("/api/v1/yourbatman")。這也算一種匹配模式,可以批量處理某一類URL。缺點是:匹配范圍過大易造成誤傷,或者范圍過小無法形成有效匹配,總之就是欠缺靈活度
- 包含匹配:url.contains("/yourbatman")。這個缺點比較明顯:強依賴于URL的書寫規范(如白名單的URL都必須包含指定子串),并且極易造成誤傷
- 正則表達式匹配:Pattern.compile("正則表達式")..matcher(url).find()。它的最大優點是可以滿足幾乎任意的URL(包括精確、模式等),但最大的缺點是書寫比較復雜,用時多少這和coder的水平強相關,另外這對后期維護也帶來了一定挑戰~
經常會聽到這樣一句話:“通過正則表達式或者Ant風格的路徑表達式來做URL匹配”。正所謂“殺雞何必用牛刀”,URL相較于普通的字符串具有很強的規律性:標準的分段式。因此,使用輕量級Ant風格表達式作為URL的匹配模式更為合適:
1.輕量級執行效率高
2.通配符(模式)符合正常理解,使用門檻非常低
*和**對層級路徑/目錄的支持感覺就是為此而生的
3.對于復雜場景亦可包含正常表達式來達到通用性
總的來講,所謂為誰更好。Ant風格和正則表達式都有它們場景的最佳實踐:
- Ant風格:用于URL/目錄這種標準分段式路徑匹配
- 正則表達式:用于幾乎沒規律(或者規律性不強)的普通字符串匹配
AntPathMatcher:基于Ant風格的路徑匹配器
PathMatcher接口并未規定路徑匹配的具體方式,在Spring的整個技術棧里(包括Spring Boot和Cloud)有且僅有一個實現類AntPathMatcher:基于Ant風格的路徑匹配器。它運用在Spring技術棧的方方面面,如:URL路徑匹配、資源目錄匹配等等。
這里有個有趣的現象:AntPathMatcher是Since:16.07.2003,而其接口PathMatcher是Since:1.2(2005.12)整整晚了2年+才出現。Spring當初的設想是把路徑匹配抽象成為一種模式(也就是PathMatcher)而不限定具體實現,但奈何近20年過去了AntPathMatcher仍舊為PathMatcher接口的唯一實現。
❝說明:Spring 5新增了更高效的、設計更好的、全新的路徑匹配器PathPattern,但它并未實現PathMatcher接口而是一套全新“生態”,用于逐步替換掉AntPathMatcher。關于此,下篇文章有詳盡分析❞說一千,道一萬。了解PathMatcher/AntPathMatcher最為重要的是什么?當然是了解它的匹配規則,做到心里有數。安排,下面我就通過代碼示例方式演示其匹配,盡量做到全乎,讓你一文在手全部都有。
代碼演示Path匹配規則
要什么記憶,有這些代碼示例收藏起來就足夠了。
在具體代碼示例之前,公示所有示例的公有代碼如下:
- private static final PathMatcher MATCHER = new AntPathMatcher();
使用缺省的 AntPathMatcher實例,并且API的使用全部面向PathMatcher接口而非具體實現類。
- private static void match(int index, PathMatcher matcher, String pattern, String reqPath) {
- boolean match = matcher.match(pattern, reqPath);
- System.out.println(index + "\tmatch結果:" + pattern + "\t" + (match ? "【成功】" : "【失敗】") + "\t" + reqPath);
- }
- private static void extractUriTemplateVariables(PathMatcher matcher, String pattern, String reqPath) {
- Map<String, String> variablesMap = matcher.extractUriTemplateVariables(pattern, reqPath);
- System.out.println("extractUriTemplateVariables結果:" + variablesMap + "\t" + pattern + "\t" + reqPath);
- }
對PathMatcher最常用的match方法、extractUriTemplateVariables方法做簡易封裝,主要為了輸出日志,方便控制臺里對應著查看。
?:匹配任意單字符
因為是匹配單字符,所以一般“夾雜”在某個path片段內容中間
- @Test
- public void test1() {
- System.out.println("=======測試?:匹配任意單個字符=======");
- String pattern = "/api/your?atman";
- match(MATCHER, pattern, "/api/youratman");
- match(MATCHER, pattern, "/api/yourBatman");
- match(MATCHER, pattern, "/api/yourBatman/address");
- match(MATCHER, pattern, "/api/yourBBBatman");
- }
- =======匹配任意單字符=======
- 1 match結果:/api/your?atman 【失敗】 /api/youratman
- 2 match結果:/api/your?atman 【成功】 /api/yourBatman
- 3 match結果:/api/your?atman 【失敗】 /api/yourBatman/address
- 4 match結果:/api/your?atman 【失敗】 /api/yourBBBatman
關注點:
- ?表示匹配精確的1個字符,所以0個不行(如結果1)
- 即使?匹配成功,但“多余”部分和pattern并不匹配最終結果也會是false(如結果3,4)
*:匹配任意數量的字符
因為是匹配任意數量的字符,所以一般使用*來代表URL的一個層級
- @Test
- public void test2() {
- System.out.println("=======*:匹配任意數量的字符=======");
- String pattern = "/api/*/yourbatman";
- match(1, MATCHER, pattern, "/api//yourbatman");
- match(2, MATCHER, pattern, "/api/ /yourbatman");
- match(2, MATCHER, pattern, "/api/yourbatman");
- match(3, MATCHER, pattern, "/api/v1v2v3/yourbatman");
- }
- =======*:匹配任意數量的字符=======
- 1 match結果:/api/*/yourbatman 【失敗】 /api//yourbatman
- 2 match結果:/api/*/yourbatman 【成功】 /api/ /yourbatman
- 3 match結果:/api/*/yourbatman 【失敗】 /api/yourbatman
- 4 match結果:/api/*/yourbatman 【成功】 /api/v1v2v3/yourbatman
關注點:
- 路徑的//間必須有內容(即使是個空串)才能被*匹配到
- *只能匹配具體某一層的路徑內容
**:匹配任意層級的路徑/目錄
匹配任意層級的路徑/目錄,這對URL這種類型字符串及其友好。
- @Test
- public void test3() {
- System.out.println("=======**:匹配任意層級的路徑/目錄=======");
- String pattern = "/api/yourbatman/**";
- match(1, MATCHER, pattern, "/api/yourbatman");
- match(2, MATCHER, pattern, "/api/yourbatman/");
- match(3, MATCHER, pattern, "/api/yourbatman/address");
- match(4, MATCHER, pattern, "/api/yourbatman/a/b/c");
- }
- =======**:匹配任意層級的路徑/目錄=======
- 1 match結果:/api/yourbatman/** 【成功】 /api/yourbatman
- 2 match結果:/api/yourbatman/** 【成功】 /api/yourbatman/
- 3 match結果:/api/yourbatman/** 【成功】 /api/yourbatman/address
- 4 match結果:/api/yourbatman/** 【成功】 /api/yourbatman/a/b/c
**其實不僅可以放在末尾,還可放在中間。
- @Test
- public void test4() {
- System.out.println("=======**:匹配任意層級的路徑/目錄=======");
- String pattern = "/api/**/yourbatman";
- match(1, MATCHER, pattern, "/api/yourbatman");
- match(2, MATCHER, pattern, "/api//yourbatman");
- match(3, MATCHER, pattern, "/api/a/b/c/yourbatman");
- }
- =======**:匹配任意層級的路徑/目錄=======
- 1 match結果:/api/**/yourbatman 【成功】 /api/yourbatman
- 2 match結果:/api/**/yourbatman 【成功】 /api//yourbatman
- 3 match結果:/api/**/yourbatman 【成功】 /api/a/b/c/yourbatman
關注點:
- **的匹配“能力”非常的強,幾乎可以匹配一切:任意層級、任意層級里的任意“東西”
- **在AntPathMatcher里即可使用在路徑中間,也可用在末尾
{pathVariable:正則表達式(可選)}
該語法的匹配規則為:將匹配到的path內容賦值給pathVariable。
- @Test
- public void test5() {
- System.out.println("======={pathVariable:可選的正則表達式}=======");
- String pattern = "/api/yourbatman/{age}";
- match(1, MATCHER, pattern, "/api/yourbatman/10");
- match(2, MATCHER, pattern, "/api/yourbatman/Ten");
- // 打印提取到的內容
- extractUriTemplateVariables(MATCHER, pattern, "/api/yourbatman/10");
- extractUriTemplateVariables(MATCHER, pattern, "/api/yourbatman/Ten");
- }
- ======={pathVariable:可選的正則表達式}=======
- 1 match結果:/api/yourbatman/{age} 【成功】 /api/yourbatman/10
- 2 match結果:/api/yourbatman/{age} 【成功】 /api/yourbatman/Ten
- extractUriTemplateVariables結果:{age=10} /api/yourbatman/{age} /api/yourbatman/10
- extractUriTemplateVariables結果:{age=Ten} /api/yourbatman/{age} /api/yourbatman/Ten
❝熟不熟悉?一不小心,這不碰到了Spring-Web中@PathVariable的底層原理(之一)么?❞可能你能察覺到,age是int類型,不應該匹配到Ten這個值呀。這個時候我們就可以結合正則表達式來做進一步約束啦。
- @Test
- public void test6() {
- System.out.println("======={pathVariable:可選的正則表達式}=======");
- String pattern = "/api/yourbatman/{age:[0-9]*}";
- match(1, MATCHER, pattern, "/api/yourbatman/10");
- match(2, MATCHER, pattern, "/api/yourbatman/Ten");
- // 打印提取到的內容
- extractUriTemplateVariables(MATCHER, pattern, "/api/yourbatman/10");
- extractUriTemplateVariables(MATCHER, pattern, "/api/yourbatman/Ten");
- }
- ======={pathVariable:可選的正則表達式}=======
- 1 match結果:/api/yourbatman/{age:[0-9]*} 【成功】 /api/yourbatman/10
- 2 match結果:/api/yourbatman/{age:[0-9]*} 【失敗】 /api/yourbatman/Ten
- extractUriTemplateVariables結果:{age=10} /api/yourbatman/{age:[0-9]*} /api/yourbatman/10
- java.lang.IllegalStateException: Pattern "/api/yourbatman/{age:[0-9]*}" is not a match for "/api/yourbatman/Ten"
關注點:
- 該匹配方式可以結合正則表達式一起使用對具體值做約束,但正則表示式是可選的
- 只有匹配成功了,才能調用extractUriTemplateVariables(...)方法,否則拋出異常
路徑匹配注意事項
請確保模式和路徑都屬于同一種類型的路徑才有匹配的意義:要么都是絕對路徑,要么都是相對路徑。當前,強烈建議是絕對路徑(以/開頭)。
在實操中,建議在調用匹配邏輯之前統一對path路徑進行“清理”(如Spring提供的StringUtils#cleanPath方法的做法):使得確保其均以/開頭,因為這樣在其上下文中匹配才是有意義的。
其它接口方法
對于路徑匹配器接口PathMatcher來講最最最重要的當屬match方法。為了雨露均沾,下面對其它幾個方法捎帶解釋以及用代碼示例一波。
isPattern()方法
- @Test
- public void test7() {
- System.out.println("=======isPattern方法=======");
- System.out.println(MATCHER.isPattern("/api/yourbatman"));
- System.out.println(MATCHER.isPattern("/api/your?atman"));
- System.out.println(MATCHER.isPattern("/api/*/yourBatman"));
- System.out.println(MATCHER.isPattern("/api/yourBatman/**"));
- }
- false
- true
- true
- true
關注點:
1.只要含有? * ** {xxx}這種特殊字符的字符串都屬于模式
matchStart()方法
它和match方法非常像,區別為:
- match:要求全路徑完全匹配
- matchStart:模式部分匹配上,然后其它部分(若還有)是空路徑即可
- @Test
- public void test8() {
- System.out.println("=======matchStart方法=======");
- String pattern = "/api/?";
- System.out.println("match方法結果:" + MATCHER.match(pattern, "/api/y"));
- System.out.println("match方法結果:" + MATCHER.match(pattern, "/api//"));
- System.out.println("match方法結果:" + MATCHER.match(pattern, "/api////"));
- System.out.println("matchStart方法結果:" + MATCHER.matchStart(pattern, "/api//"));
- System.out.println("matchStart方法結果:" + MATCHER.matchStart(pattern, "/api////"));
- System.out.println("matchStart方法結果:" + MATCHER.matchStart(pattern, "/api///a/"));
- }
- =======matchStart方法=======
- match方法結果:true
- match方法結果:false
- match方法結果:false
- matchStart方法結果:true
- matchStart方法結果:true
- matchStart方法結果:false
關注點:
1.請對比結果,看出和match方法的差異性
matchStart方法的使用場景少之又少,即使在代碼量巨大的Spring體系中,也只有唯一使用處:PathMatchingResourcePatternResolver#doRetrieveMatchingFiles
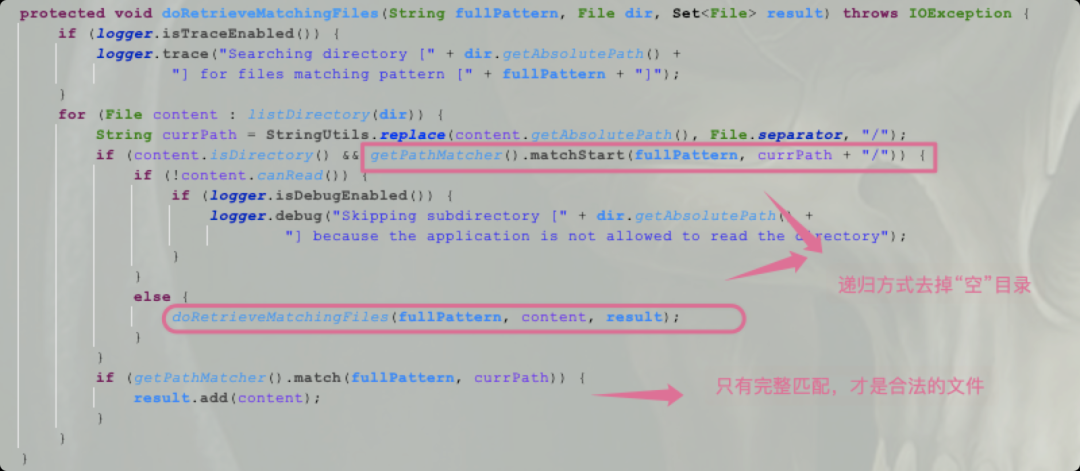
extractPathWithinPattern()方法
該方法通過一個實際的模式來確定路徑的哪個部分是動態匹配的,換句話講:該方法用戶提取出動態匹配的那部分
❝說明:該方法永遠不可能返回null❞
- @Test
- public void test9() {
- System.out.println("=======extractPathWithinPattern方法=======");
- String pattern = "/api/*.html";
- System.out.println("是否匹配成功:" + MATCHER.match(pattern, "/api/yourbatman/address")
- + ",提取結果:" + MATCHER.extractPathWithinPattern(pattern, "/api/yourbatman/address"));
- System.out.println("是否匹配成功:" + MATCHER.match(pattern, "/api/index.html")
- + ",提取結果:" + MATCHER.extractPathWithinPattern(pattern, "/api/index.html"));
- }
- =======extractPathWithinPattern方法=======
- 是否匹配成功:false,提起結果:yourbatman/address
- 是否匹配成功:true,提起結果:index.html
關注點:
1.該方法和extractUriTemplateVariables()不一樣,即使匹配不成功也能夠返回參與匹配的那部分,有種“重在參與”的趕腳
下面再看個復雜點pattern情況(pattern里具有多個模式)表現如何:
- @Test
- public void test10() {
- System.out.println("=======extractPathWithinPattern方法=======");
- String pattern = "/api/**/yourbatman/*.html/temp";
- System.out.println("是否匹配成功:" + MATCHER.match(pattern, "/api/yourbatman/address")
- + ",提取結果:" + MATCHER.extractPathWithinPattern(pattern, "/api/yourbatman/address"));
- System.out.println("是否匹配成功:" + MATCHER.match(pattern, "/api/yourbatman/index.html/temp")
- + ",提取結果:" + MATCHER.extractPathWithinPattern(pattern, "/api/yourbatman/index.html/temp"));
- }
- =======extractPathWithinPattern方法=======
- 是否匹配成功:false,提取結果:yourbatman/address
- 是否匹配成功:true,提取結果:yourbatman/index.html/temp
關注點:
- 該方法會返回所有參與匹配的片段,即使這匹配不成功
- 若有多個模式(如本例中的**和*),返回的片段不會出現跳躍現象(只截掉前面的非pattern匹配部分,中間若出現非pattern匹配部分是不動的)
getPatternComparator()方法
此方法用于返回一個Comparator
- @Test
- public void test11() {
- System.out.println("=======getPatternComparator方法=======");
- List<String> patterns = Arrays.asList(
- "/api/**/index.html",
- "/api/yourbatman/*.html",
- "/api/**/*.html",
- "/api/yourbatman/index.html"
- );
- System.out.println("排序前:" + patterns);
- Comparator<String> patternComparator = MATCHER.getPatternComparator("/api/yourbatman/index.html");
- Collections.sort(patterns, patternComparator);
- System.out.println("排序后:" + patterns);
- }
- =======getPatternComparator方法=======
- 排序前:[/api/**/index.html, /api/yourbatman/*.html, /api/**/*.html, /api/yourbatman/index.html]
- 排序后:[/api/yourbatman/index.html, /api/yourbatman/*.html, /api/**/index.html, /api/**/*.html]
關注點:
- 該方法擁有一個入參,作用為:用于判斷是否是精確匹配,也就是用于確定精確值的界限的(根據此界限值進行排序)
- 越精確的匹配在越前面。其中路徑的匹配原則是從左至右(也就是說左邊越早出現精確匹配,分值越高)
combine()方法
將兩個方法“綁定”在一起。PathMatcher接口并未規定綁定的“規則”,完全由底層實現自行決定。如基于Ant風格的匹配器的拼接原則如下:
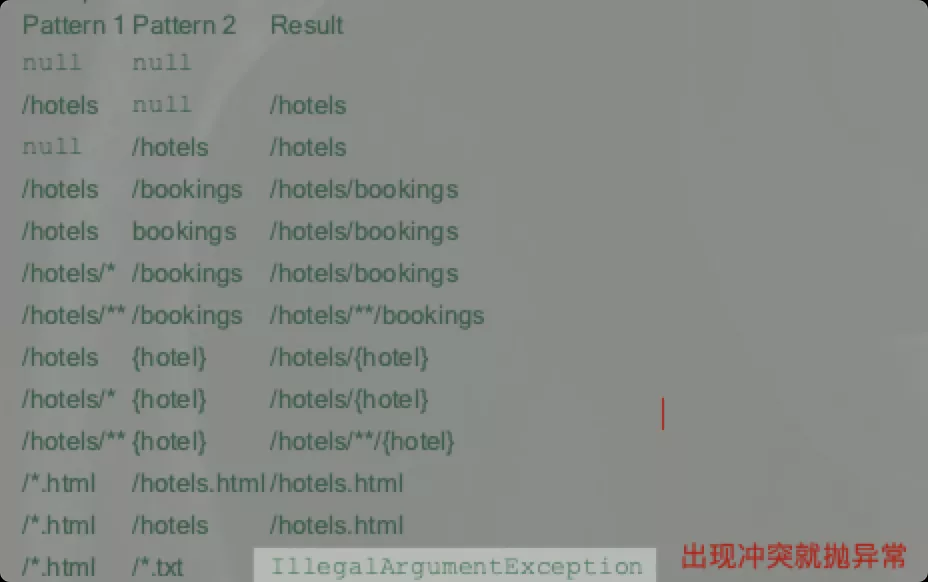
記得@RequestMapping這個注解吧,它既可以標注在類上,亦可標注在方法上。把Pattern1比作標注在類上的path(若木有標注值就是null嘛),把Pattern2比作標注在方法上的path,它倆的結果不就可以參考上圖了麼。一不小心又加深了點對@RequestMapping注解的了解有木有。
使用細節
AntPathMatcher作為PathMatcher路徑匹配器模式的唯一實現,這里有些使用細節可以幫你加深對AntPathMatcher的了解。
一些默認值
默認決定了AntPathMatcher的一些缺省行為,了解一下:
- public static final String DEFAULT_PATH_SEPARATOR = "/";
默認使用/作為路徑分隔符。若是請求路徑(如http、RPC請求等)或者是Linux的目錄名,一切相安無事。但若是Windows的目錄地址呢?
❝說明:windows目錄分隔符是\,如C:\ProgramData\Microsoft\Windows\Start Menu\Programs\7-Zip❞
- private static final Pattern VARIABLE_PATTERN = Pattern.compile("\\{[^/]+?}");
當路徑/目錄里出現{xxx:正則表達式}這種模式的字符串就被認定為是VARIABLE_PATTERN
- private static final char[] WILDCARD_CHARS = {'*', '?', '{'};
不解釋
原理
AntPathMatcher采用前綴樹(trie樹) 算法對URL進行拆分、匹配。本類代碼量還是不少的,整體呈現出比較臃腫的狀態,代碼行數達到了近1000行:
或許可以對它進行關注點的拆分,但這似乎已無必要。因為Spring 5已新增的PathPattern能以更高的運行效率、更優雅的代碼設計來替代扎根已久的AntPathMatcher,不知這是否能勾起你對PathPattern興趣呢?
❝說明:這里對原理實現點到即止,對前綴樹(trie樹) 感興趣的同學可專門研究,至少我也只了解個大概即止,這里就不班門弄斧了❞
應用場景
AntPathMatcher作為PathMatcher的唯一實現,所以Spring框架的邏輯處理里隨處可見:
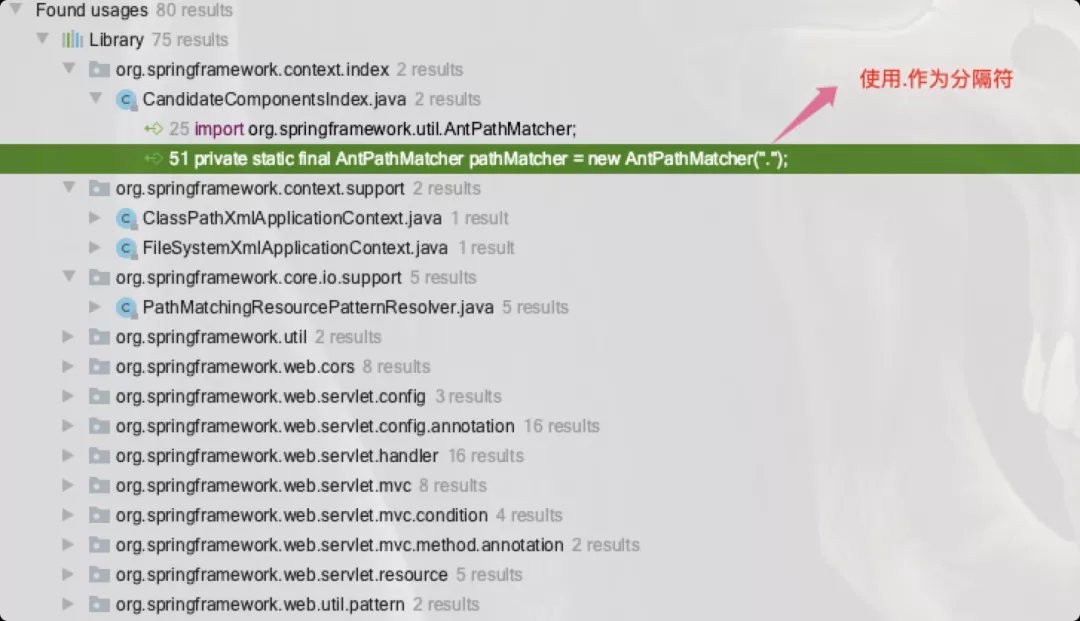
❝說明:AntPathMatcher默認使用/作為分隔符。你可根據實際情況在構造時自行指定分隔符(如windows是\,Lunux是/,包名是.)❞
在應用層面,Ant風格的URL、目錄地址、包名地址也是隨處可見:
- 掃包:@ComponentScan(basePackages = "cn.yourbatman.**.controller")
- 加載資源:classpath: config/application-*.yaml
- URL映射:@RequestMapping("/api/v1/user/{id}")
- ...
PathMatcher路徑匹配器是spring-core核心包的一個基礎組件,它帶來的能力讓Spring框架在路徑/目錄匹配上極具彈性,使用起來也是非常的方便。
❝再次強調:PathMatcher它屬于spring-core,所以not only for web.❞
總結
Ant風格雖然概念源自Apache Ant,但是借由Spring“發揚光大”。在整個Spring體系內,涉及到的URL匹配、資源路徑匹配、包名匹配均是支持Ant風格的,底層由接口PathMatcher的唯一實現類AntPathMatcher提供實現。
AntPathMatcher不僅可以匹配Spring的@RequestMapping路徑,也可以用來匹配各種字符串,包括文件資源路徑、包名等等。由于它所處的模塊是spring-core無其它多余依賴,因此若有需要(比如自己在寫框架時)我們也可以把它當做工具來使用,簡化開發。
本文轉載自微信公眾號「 BAT的烏托邦」,可以通過以下二維碼關注。轉載本文請聯系 BAT的烏托邦公眾號。















