













聊聊Greenplum集群部署
Greenplum屬于一種看起來“較重”的數據庫MPP架構,不像基于MySQL基于中間件的架構那么輕量,但是要說一些具體的場景,比如Greenplum支持存儲過程,支持列式存儲,加上分區表和內置的數據分片等多種模式,都是典型的OLAP場景,術業有專攻還是有一定道理的。
最近因為業務需求和改造需要部署幾套GP集群,總體來說也是需要解決以前的一些頑疾并加以改進,運行幾個上百節點的集群還是有一定的壓力的,不過前幾年在飛祥同學的勞動成果之上,整個集群還是比較穩定的,在運行中也發現了一些額外的問題和痛點。
1)之前的GP segment數量設計過度,因為資源限制,過多考慮了功能和性能,對于集群的穩定性和資源平衡性考慮有所欠缺,在每個物理機節點上部署了10個Primary,10個Mirror,導致一旦出現Segment節點不可用,對于整個集群的穩定性會是一個大的隱患,最尷尬的莫過于一個Segment節點不可用,另外一個Segment節點負載過高,最后集群不可用,所幸這種情況暫未出現
2)GP集群的存儲資源和性能的平衡不夠。GP存儲對標基本都是百TB,相對來說和我們所說的大數據體系的PB還是有很大差異的,GP里面計算的數據總體都是比較重要,而且總體的存儲容量不會特別大,磁盤現在有8T的規格,如果放12塊盤,則RAID-5會有近70多T的存儲空間,而RAID-10則有48T左右的空間,如果RAID-5同時壞了2塊盤就尷尬了,但是對于RAID-10來說還是有轉機的,這個情況之前碰到過一次,在替換一塊壞盤的時候,工程師發現另外一塊盤也快壞了,RAID-5要一塊一塊的換,當時還因為這個熬了個通宵,想了很多預案,說了這么多是想表達,GP存儲的容量不用那么大,如果在損失一定存儲容量的基礎上能夠最大程度降低隱患是很劃算的,所以在存儲容量和性能的綜合之上,我們是選擇了RAID-10
3)集群的驗收和保障工作補充。如果一個GP集群用過很長一段時間就會發現啟停都是一個大工程,之前啟停要耗時半個小時,讓小心臟壓力很大。 這個過程中也發現了以前遺漏了一些環節,比如性能壓測,導致不太確定整個集群的支撐能力到底如何。
在此基礎上,還需要額外考慮如下的一些因素:
1)集群的跨機房遷移如何做到平滑,或者影響最低,之前一次機房搬遷,導致IP變化后的集群無法啟動,當時真是嚇壞了,因為在這種問題面前,就是0和1的博弈,如果是0就意味著數據都丟棄了,所以在這方面還是需要做一些扎實的鋪墊。
2)服務器后續過保要做硬件替換,如何能夠實現滾動替換,這是在已有的基礎之上需要前瞻考慮的重要點,幾年后的服務器過保如何應對,如果有了可靠的方案,以后也會從容一些。
3)GP的版本和基礎環境需要同步升級,比如我們目前的主流操作系統為CentOS7,如果繼續使用CentOS 6就不應該了,同時對于GP的版本也需要重新評估,在較新版本和穩定版本之間進行平衡。
整個GP集群的部署架構如下:
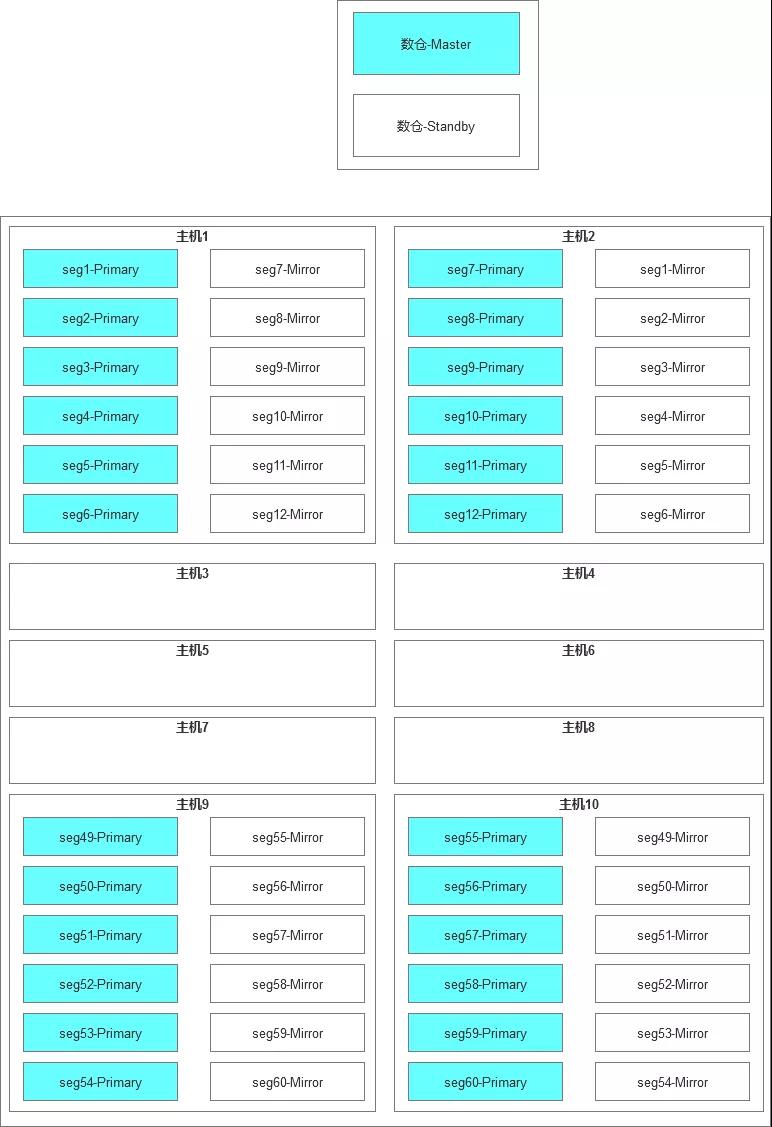
Greenplum是我知道的數據庫中的角色最完整的。Master,Standby,Primary,Mirror,各種數據庫中的不同角色在這里有一套完整的體系命名。
新的這一套環境注定在我手中構建,所以我希望完善以下的一些細節。
1)Greenplum的版本選擇,目前有兩個主要的版本類別,一個是開源版(Open Source distribution)和Pivotal官方版,它們的其中一個差異就是官方版需要注冊,簽署協議,在此基礎上還有GPCC等工具可以用,而開源版本可以實現源碼編譯或者rpm安裝,無法配置GPCC。綜合來看,我們選擇了開源版本的6.16.2,這其中也詢問了一些行業朋友,特意選擇了幾個涉及穩定性bug修復的版本。
2)GP的容量規劃,這一次經過討論是選擇了折中的配置,即(6+6)*10+2,具體解釋就是一共12臺服務器,其中有10臺服務器是Segment節點,每臺上面部署了6個Primary,6個Mirror,另外2臺部署了Master和Standby
3)內核參數的配置和調整
除了基礎的kernel.shmmax和kernel.shmall配置之外,還有如下的一些配置需要調整:
- vm.swappiness=10
- vm.zone_reclaim_mode = 0
- vm.dirty_expire_centisecs = 500
- vm.dirty_writeback_centisecs = 100
- vm.dirty_background_ratio = 0 # See System Memory
- vm.dirty_ratio = 0
- vm.dirty_background_bytes = 1610612736
- vm.dirty_bytes = 4294967296
- vm.min_free_kbytes = 3943084
- vm.overcommit_memory=2
- kernel.sem = 500 2048000 200 4096
集群部署的大體流程:
1)首先是配置/etc/hosts,需要把所有節點的IP和主機名都整理出來。
2)配置用戶,很常規的步驟
- groupadd gpadmin
- useradd gpadmin -g gpadmin
- passwd gpadmin
3)配置sysctl.conf和資源配置
4)使用rpm模式安裝
- yum install -y apr apr-util bzip2 krb5-devel zip
- # rpm -ivh open-source-greenplum-db-6.16.2-rhel7-x86_64.rpm
- Preparing... ################################# [100%]
- Updating / installing...
- 1:open-source-greenplum-db-6-6.16.2################################# [100%]
5)配置兩個host文件,也是為了后面進行統一部署方便,在此建議先開啟gpadmin的sudo權限,可以通過gpssh處理一些較為復雜的批量操作
6)通過gpssh-exkeys來打通ssh信任關系,這里需要吐槽這個ssh互信,端口還得是22,否則處理起來很麻煩
- gpssh-exkeys -f hostlist
7)較為復雜的一步是打包master的Greenplum-db-6.16.2軟件,然后分發到各個segment機器中,整個過程涉及文件打包,批量傳輸和配置,可以借助gpscp和gpssh,比如gpscp傳輸文件,如下的命令會傳輸到/tmp目錄下
- gpscp -f /usr/local/greenplum-db/conf/hostlist /tmp/greenplum-db-6.16.2.tar.gz =:/tmp
8)Master節點需要單獨配置相關的目錄,而Segment節點的目錄可以提前規劃好,比如我們把Primary和Mirror放在不同的分區。
- mkdir -p /data1/gpdata/gpdatap1
- mkdir -p /data1/gpdata/gpdatap2
- mkdir -p /data2/gpdata/gpdatam1
- mkdir -p /data2/gpdata/gpdatam2
9)整個過程里最關鍵的就是gpinitsystem_config配置了,因為Segment節點的ID配置和命名,端口區間都是根據一定的規則來動態生成的,所以對于目錄的配置需要額外注意。
10)部署GP集群最關鍵的命令是
gpinitsystem -c gpinitsystem_config -s 【standby_hostname】
整個過程大約5分鐘~10分鐘以內會完成。
在此也走了不少彎路,比如一些配置不完整,防火墻權限不夠,導致部署的時候界面卡在那里,
比如其中一個問題,/etc/hosts 配置不全 導致Primary可以啟動,但是Mirror無法啟動,問題看起來很奇怪,而且從GP的日志里面的信息也很簡略,如果難以定位,還可以直接到相應的Segment節點上查看相應的日志,查看日志是個技術活,如果出現卡頓,不要干等著,得看看后端到底在哪個環節卡住了,需要同步查看日志的刷新來進行問題的定位和修正,在這方面GP的一些安裝體驗還是比較粗糙的。
安裝部署這件事,就像一個無形的門檻,只要自己做過一次,相信這些步驟都很簡單,反之就像一座繞不開的大山,始終繞不過去,對于安裝部署,最全面的文檔還是官方文檔。






















