MySQL系列之執行SQL 語句時發生了什么?
前言
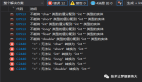
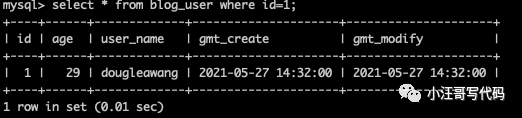
當我們用 navicat、mysql workbench 等mysql 的客戶端執行一條sql語句后,我們就能得到相應的結果。例如:
那么這個過程發生了什么呢?
執行一條sql 就是一次Rpc的調用
mysql 是一個客戶端、服務端的架構。我們平時使用的大部分程序app其實是由兩部分組成的,一部分是客戶端程序,一部分是服務器程序。
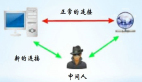
以我們常用的微信、qq 為例。我們手機里面裝的客戶端,機房的服務器中運行著server端。我們平時發信息都是其實都是用客戶端和服務端打交道。比如你和你女朋友發信息的過程:
- 消息被客戶端包裝了一下,添加了發送者和接收者信息,然后從你的微信客戶端傳送給微信服務器;
- 微信服務器從消息里獲取到它的發送者和接收者,根據消息的接收者信息把這條消息送達到你女朋友的微信客戶端,你女朋友的微信客戶端里就顯示出你給他發了一條消息。
mysql的使用過程跟這個是一樣的,它的服務器程序直接和我們存儲的數據打交道,然后可以有好多客戶端程序連接到這個服務器程序,發送增刪改查的請求,然后服務器就響應這些請求,從而操作它維護的數據。
主要流程如下:
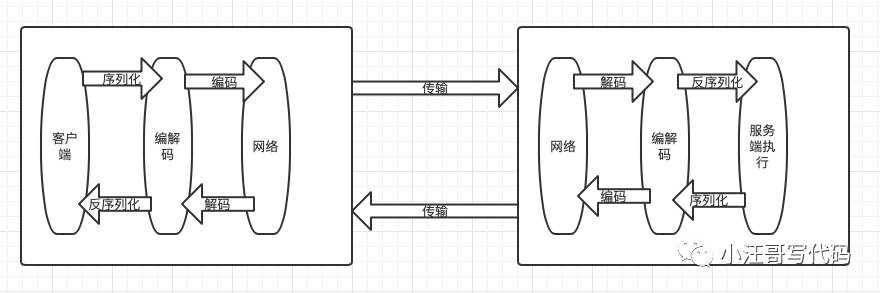
所以,一條sql的執行,就是一次rpc的調用。后面有時間也會分享RPC 相關的東西,一起交流學習!
服務器怎么處理客戶端請求
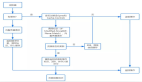
不管我們用了哪種客戶端和服務器進程是采用哪種方式進行通信,最后實現的效果都是:客戶端進程向服務器進程發送一段文本(MySQL語句),服務器進程處理后再向客戶端進程發送一段文本(處理結果)。主要過程如下:
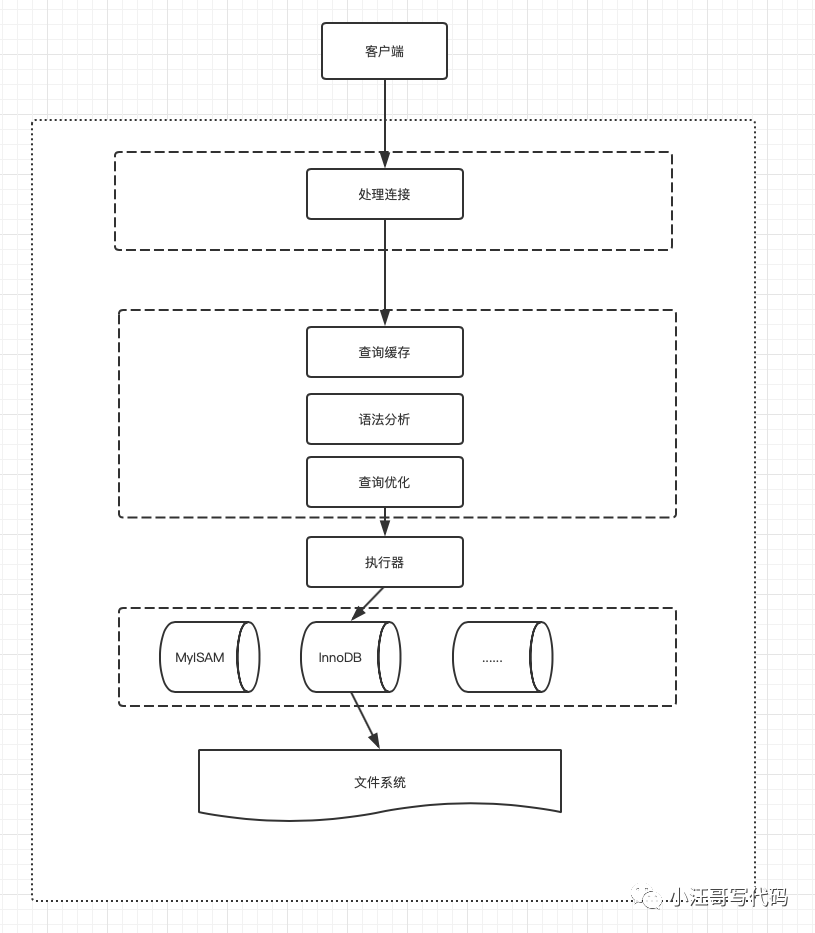
從圖中我們可以看出,服務器程序處理來自客戶端的查詢請求大致需要經過三個部分,分別是 連接管理、解析優化與執行、存儲引擎三個部分。其中連接管理、解析優化與執行常常被分為mysql的 server 層。
連接管理
客戶端進程可以采用TCP/IP、命名管道或共享內存、Unix域套接字這幾種方式之一來與服務器進程建立連接。
對連接的管理也使用了池化技術:每當有一個客戶端進程連接到服務器進程時,服務器進程都會創建一個線程來專門處理與這個客戶端的交互,當該客戶端退出時會與服務器斷開連接,服務器并不會立即把與該客戶端交互的線程銷毀掉,而是把它緩存起來,在另一個新的客戶端再進行連接時,把這個緩存的線程分配給該新客戶端。這樣就起到了不頻繁創建和銷毀線程的效果,從而節省開銷。
查詢緩存
由于表經常更新,查詢緩存的失效頻繁,查詢緩存往往利大于弊。,MySQL 8.0 版本開始直接將查詢緩存的整塊功能刪掉了。
語法解析
如果查詢緩存沒有命中,接下來就需要進入正式的查詢階段了。因為客戶端程序發送過來的請求只是一段文本而已,所以MySQL服務器程序首先要對這段文本做分析,判斷請求的語法是否正確,然后從文本中將要查詢的表、各種查詢條件都提取出來放到MySQL服務器內部使用的一些數據結構上來。
查詢優化
經過了語法解析,MySQL 就知道你要做什么了。在開始執行之前,還要先經過查詢優化的處理。優化處理是指在表里面有多個索引的時候,決定使用哪個索引;或者在一個語句有多表關聯(join)的時候,決定各個表的連接順序。我們可以使用EXPLAIN語句來查看某個語句的執行計劃 。
大部分優化的邏輯是基于成本的優化。在MySQL中一條查詢語句的執行成本是由兩個方面組成的 :
- I/O成本 :從磁盤到內存這個加載的過程損耗的時間稱之為I/O成本。
- CPU成本 :讀取以及檢測記錄是否滿足對應的搜索條件、對結果集進行排序等這些操作損耗的時間稱之為CPU成本。
對于InnoDB存儲引擎來說 ,mysql規定讀取一個頁面花費的成本默認是1.0,讀取以及檢測一條記錄是否符合搜索條件的成本默認是0.2 。
拿單表查詢來舉例,成本計算步驟如下:
- 根據搜索條件,找出所有可能使用的索引
- 計算全表掃描的代價
- 計算使用不同索引執行查詢的代價
- 對比各種執行方案的代價,找出成本最低的那一個。
存儲引擎
- 截止到服務器程序完成了查詢優化為止,還沒有真正的去訪問真實的數據表,MySQL服務器把數據的存儲和提取操作都封裝到了一個叫存儲引擎的模塊里。我們知道表是由一行一行的記錄組成的,但這只是一個邏輯上的概念,物理上如何表示記錄,怎么從表中讀取數據,怎么把數據寫入具體的物理存儲器上,這都是存儲引擎負責的事情。為了實現不同的功能,MySQL提供了各式各樣的存儲引擎,不同存儲引擎管理的表具體的存儲結構可能不同,采用的存取算法也可能不同。
- 為了管理方便,所以大部分人把連接管理、查詢緩存、語法解析、查詢優化這些并不涉及真實數據存儲的功能劃分為MySQL server的功能,
- 把真實存取數據的功能劃分為存儲引擎的功能。
執行器
執行器就是各種不同的存儲引擎向上邊的MySQL server層提供統一的調用接口(也就是存儲引擎API),包含了幾十個底層函數,像"讀取索引第一條內容"、"讀取索引下一條內容"、"插入記錄"等等。
比如執行一條查詢sql 時,開始執行的時候,要先判斷一下你對這個表 有沒有執行查詢的權限,如果沒有,就會返回沒有權限的錯誤;
拿我們開頭的例子中,id字段沒有索引,那么執行器的執行流程是這樣的:
- 調用 InnoDB 引擎接口取這個表的第一行,判斷 ID 值是不是 10,如果不是則跳過,如果是則將這行存在結果集中;
- 調用引擎接口取“下一行”,重復相同的判斷邏輯,直到取到這個表的最后一行。
- 執行器將上述遍歷過程中所有滿足條件的行組成的記錄集作為結果集返回給客戶端。
對于有索引的表,執行的邏輯也差不多。第一次調用的是“取滿足條件的第一行”這個接口,之后循環取“滿足條件的下一行”這個接口,這些接口都是引擎中已經定義好的。但是對于 插入、刪除和修改的sql語句,還要涉及到redolog、undolog 和binlog 的操作。這個我們有空再聊。
所以只需按照生成的執行計劃調用底層存儲引擎提供的API(執行器),獲取到數據后返回給客戶端就好了。一條sql 語句就執行完成了。