













從ClickHouse遷移到Apache Doris后發生了什么?
譯文譯者 | 布加迪
審校 | 重樓
從一個OLAP數據庫遷移到另一個OLAP數據庫是個大工程。即使您對當前的數據工具不滿意,并且已經找到了一些大有前途的候選工具,可能仍然會猶豫是否要對數據架構進行一番大動作,因為您不確定事情會如何進展。所以您需要過來人分享一下經驗。

幸運的是,Apache Doris的一個用戶已經撰文寫下了從ClickHouse遷移到Doris的過程,包括他們為什么需要遷移,需要注意什么,以及如何在環境中比較兩種數據庫的性能。
為了要決定是否繼續讀下去,請檢查您是否符合以下其中一項:
- 您需要更快地執行連接查詢
- 您需要靈活的數據更新
- 您需要實時數據分析
- 您需要最小化組件
如果符合上述任何一項,本文對您可能會有所幫助。
把Kylin、ClickHouse和Druid換成Apache Doris
經歷這番變化的用戶是一家電子商務SaaS提供商。其數據系統提供實時和離線報告、客戶細分以及日志分析。最初,他們為這些不同的目的使用不同的OLAP引擎:
- 用于離線報告的Apache Kylin:該系統為500余萬賣家提供離線報告服務。其中規模較大的賣家有1000余萬注冊會員和100000個單品,詳細信息被存儲在該平臺上的400多個數據立方體(Data Cube)中。
- 用于客戶細分和Top-N日志查詢的ClickHouse:這需要高頻更新、每秒查詢(QPS)次數高以及復雜的SQL。
- 用于實時報告的Apache Druid:賣家通過結合不同的維度提取自己需要的數據,這種實時報告需要數據更新快速、查詢響應迅速和系統極其穩定。
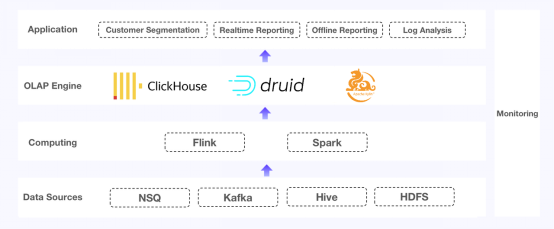 圖1. 這三大部分有各自的痛點
圖1. 這三大部分有各自的痛點
- 面對固定的表模式,Apache Kylin可以很好地運行。但每當您想要添加一個維度,就需要創建一個新的數據立方體,并往里面重新填充歷史數據。
- ClickHouse不是為多表處理而設計的,因此您可能需要為聯合查詢和多表連接查詢提供另外的解決方案。而在本文這個例子中,它在高并發場景下未達到預期。
- Apache Druid實現了冪等寫入,因此它本身不支持數據更新或刪除。這意味著當上游出現問題時,您將需要完整的數據替換。如果您考慮到所有的數據備份和移動,這種數據修復是一個涉及多步驟的過程。此外,新攝取的數據將無法供查詢訪問,除非它被放在Druid的片段中。這意味著窗口較長,從而使得上游和下游之間的數據不一致。
當這些組件協同工作時,這個架構可能要求太高而無法導航,因為它需要在開發、監控和維護方面了解所有這些組件。此外,每當用戶擴展集群,必須停止當前集群,并遷移所有數據庫和表,這不僅僅是一項大工程,還會嚴重干擾業務的正常運營。
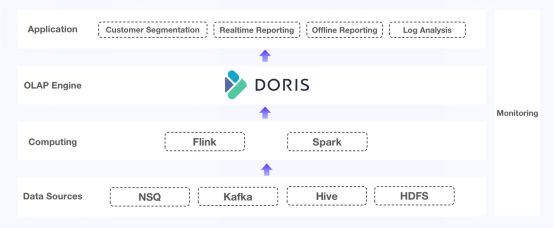 圖2. Apache Doris填補了這些空白
圖2. Apache Doris填補了這些空白
- 查詢性能:Doris擅長高并發查詢和連接查詢,現在它配備了一個反向索引,以加速日志中的搜索。
- 數據更新:Doris的獨特鍵(Unique Key)模型支持大容量更新和高頻實時寫入,重復鍵(Duplicate Key)模型和獨特鍵模型支持部分列更新。它還在數據寫入時提供了精確一次(exact-once)保證,并確保基礎表、物化視圖和副本之間的一致性。
- 維護:Doris與MySQL兼容。它支持簡易擴展和輕量級模式更改。它自帶集成工具,比如Flink-Doris-Connector和Spark-Doris-Connector。
于是他們計劃遷移。
替換過程
ClickHouse是舊數據架構的主要性能瓶頸,也是用戶最初希望改變的原因,于是他們開始從ClickHouse入手。
SQL語句的變化
表創建語句
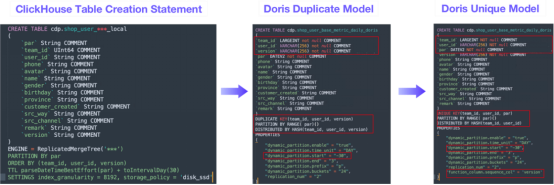 圖3
圖3
用戶構建了自己的SQL重寫工具,該工具可以將ClickHouse表創建語句轉換成Doris表創建語句。該工具可以自動執行以下更改:
- 映射字段類型:它將ClickHouse字段類型轉換成Doris中相應的字段類型。比如說,它將作為鍵字段的String轉換成Varchar,將作為分區字段的String轉換成Date V2。
- 設置動態分區表中的歷史分區數:一些表有歷史分區,在Doris中創建表時應該指定分區數,否則將會拋出“無分區”錯誤。
- 確定存儲桶數:根據歷史分區的數據量確定存儲桶數;針對非分區表,它根據歷史數據量確定存儲桶配置。
- 確定TTL:它確定動態分區表中分區的存活時間。
- 設置導入順序:針對Doris的獨特鍵模型,可以根據序列這列指定數據導入順序,以確保數據攝取的有序性。
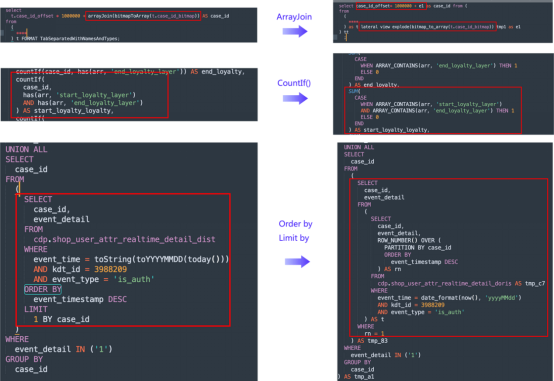 圖4
圖4
查詢語句
同樣,他們有自己的工具將ClickHouse查詢語句轉換成Doris查詢語句。這是為ClickHouse和Doris的對比測試做準備。轉換中的關鍵考慮因素包括如下:
- 表名的轉換:根據表創建語句中的映射規則,這很簡單。
- 函數的轉換:比如說,ClickHouse中的COUNTIF函數相當于SUM(CASE WHEN_THEN 1 ELSE 0),Array Join相當于Explode和Lateral View,而ORDER BY和GROUP BY應該轉換成窗口函數。
- 語義上的區別:ClickHouse使用自己的協議,而Doris與MySQL兼容,所以子查詢需要有一個別名。在這個用例中,子查詢在客戶細分中很常見,因此它們使用sqlparse。
數據攝取方法的變化
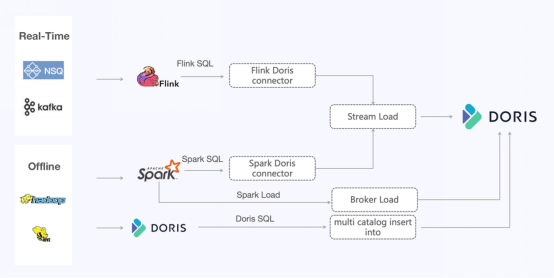 圖5
圖5
Apache Doris為數據寫入方法提供了眾多選項。對于實時鏈路,用戶采用Stream Load從NSQ和Kafka中攝取數據。
針對龐大的離線數據,用戶測試了不同的方法,以下是一些建議:
1. Insert Into
使用Multi-Catalog讀取外部數據源,并使用Insert Into攝取數據,可以滿足該用例中的大多數需求。
2. Stream Load
Spark-Doris-Connector是一種更通用的方法。它可以處理龐大數據量,保證寫入穩定性。關鍵在于找到合適的寫入節奏和并發處理。
Spark-Doris-Connector還支持位圖。它允許您在Spark集群中移動位圖數據的計算工作負載。
Spark-Doris-Connector和Flink-Doris-Connector都依賴Stream Load。CSV是推薦的格式選擇。針對該用戶數十億行的測試表明,CSV比JSON快40%。
3. Spark Load
Spark Load方法利用Spark資源進行數據混排和排序。計算結果放在HDFS中,然后Doris直接從HDFS中讀取文件(通過Broker Load)。這種方法非常適合大量數據的攝取。數據越多,攝取的速度越快,資源效率也越高。
壓力測試
用戶比較了兩個組件在SQL連接查詢場景下的性能,并計算了Apache Doris的CPU和內存消耗情況。
SQL查詢性能
就性能而言,Apache Doris在16個SQL查詢中有10個優于ClickHouse,性能最多相差近30倍。總的來說,Apache Doris比ClickHouse快2~3倍。
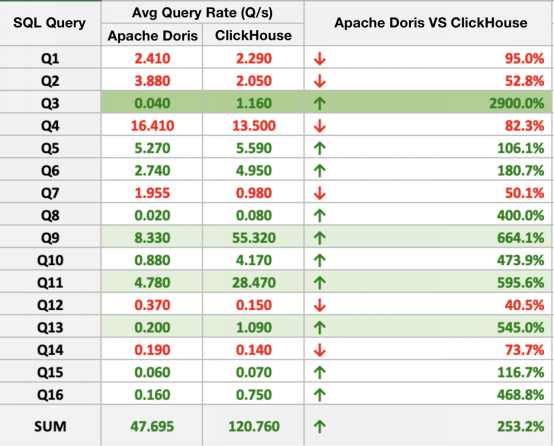 圖6
圖6
連接查詢性能
針對連接查詢測試,該用戶使用了不同大小的主表和維度表。
- 主表:用戶活動表(40億行)、用戶屬性表(250億行)和用戶屬性表(960億行)。
- 維度表:100萬行、1000萬行、5000萬行、1億行、5億行、10億行和25億行。
測試包括全連接查詢和過濾連接查詢。全連接查詢連接主表和維度表的所有行,而過濾連接查詢使用WHERE過濾器檢索某個賣家ID的數據。研究結果如下:
主表(40億行):
- 全連接查詢:Doris在所有維度表的全連接查詢中性能優于ClickHouse。性能差距隨著維度表的增大而增大,最多相差5倍。
- 過濾連接查詢:基于賣家ID,過濾器從主表中篩選出4100萬行。針對小型維度表,Doris的速度比ClickHouse快2~3倍;針對大型維度表,Doris的速度要快十倍以上;針對大于1億行的維度表,ClickHouse拋出了OOM錯誤,而Doris可以正常運行。
主表(250億行):
- 全連接查詢:Doris在所有維度表的全連接查詢中性能優于ClickHouse。ClickHouse在維度表大于5000萬行的情況下拋出了OOM錯誤。
- 過濾連接查詢:過濾器從主表中篩選出5.7億行。Doris在幾秒鐘內做出響應,ClickHouse在幾分鐘內完成,在連接大型維度表時出現了崩潰。
主表(960億行):
- Doris在所有查詢中都給出了比較快的性能,而ClickHouse無法執行所有查詢。
- 在CPU和內存消耗方面,Apache Doris在所有大小的連接查詢中都確保了集群負載的穩定性。
原文標題:Migrating From ClickHouse to Apache Doris: What Happened?,作者:Frank Z
















