













MaxCompute 挑戰使用SQL進行序列數據處理
日常編寫數據加工任務,主要的方法就是使用SQL。第一是因為自己對SQL掌握的比較好(十多年數據開發經驗,就這幾個關鍵字,也不敢跟別人說自己不行),所以,MR和函數涉及不多。在接觸MaxCompute這些年,寫過的函數應該不超過10個,主要還是因為自己JAVA水平挫。記得早些年寫過一個身份證號碼校驗函數,當時有個項目反饋一段SQL原來2分鐘,使用我的函數就變成12分鐘了。當時這個項目組還找到MaxCompute的研發,研發負責人又找到我,讓我把我的代碼調優下。我很惶恐啊,我是什么渣,我自己心里知道啊。最后還是厚著臉皮求研發幫我優化了下,性能終于改進了。這以后,我更不敢隨機作函數了,畢竟MaxCompute官方建議盡可能使用SQL,SQL是優化過的方法,自己用MR和自定義函數性能是很難保障的。這也導致我至今在這方面也是渣渣,當然我認為錯不在我,我只是聽了“媽媽”的話而已。
最近很奇妙,接連有兩個項目遇到了序列值計算的問題,還都是要求不能使用函數和MR。同事把問題送給我,我發現光讀懂題都要半天(題目有點繞),不在一線搞開發太久了,有點生疏了。同樣的問題,第一次搞了一天,第二次還搞了半天,沒說很快能搞出來的,未免有點丟范。所以,總結出來跟大家分享下。
先說下什么是序列值的處理。表中的記錄本身是無序的,但是業務上數據都是有序的,一般來說時間就是一個自然的序列。比如利用我一天的作息的時點記錄,計算我一天吃了幾次飯,吃了多久。乍一看,好像要寫個函數。
問題模擬如下:
問題:吃了幾次飯,都吃了多久?
條件:1-兩個“吃飯”狀態間隔在1小時內,算作一頓飯
2-最后一個“吃飯”狀態后的下一個其他狀態的開始時間,是“吃飯”的結束時間
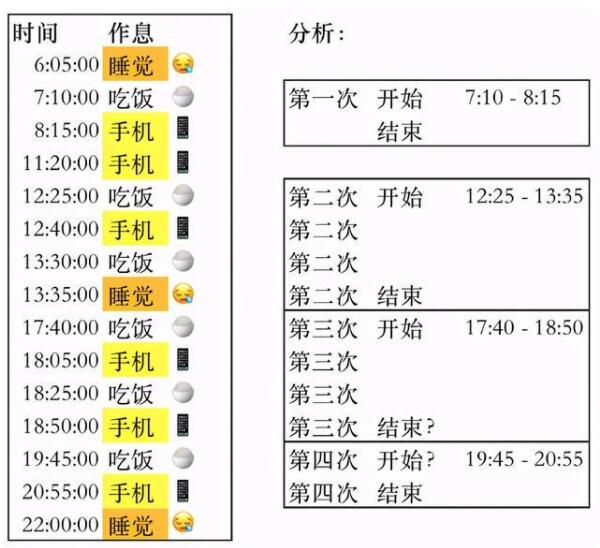
通過上面的分析,我們可以得到結果:大約吃了四次飯,因為晚上吃飯的時間很長,按照規則算作吃了兩次飯(第四次看起來是去擼串了)。我是怎么做的呢?第一步,我先把無關的信息剔除了,第1行、第4行、最后1行。第二步,后我利用數據是連續的時間的特質,找到了狀態的結束時間。第三步,我識別了狀態間隔1小時這個特征,識別出了一個“吃飯”中混雜的其他無關狀態,并且還分析得到第三個“吃飯”和第四個“吃飯”狀態是兩個獨立的狀態。
那么用SQL怎么實現?排序是一定的了,要排序還要處理狀態,必須使用窗口函數。能選的窗口函數似乎只有lag、lead。
窗口函數:
LAG 按偏移量取當前行之前第幾行的值。
LEAD 按偏移量取當前行之后第幾行的值。
官方文檔:https://help.aliyun.com/document_detail/34994.html
即便有了這個函數,還有一個問題很頭疼,函數需要指定偏移量,而這個問題里面并不知道到底會出現多少個狀態。是不是也沒有用呢?看看再說。
問題分解分解如下:
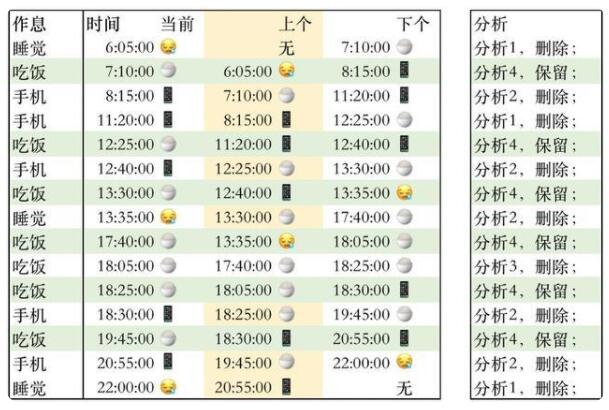
使用LAG\LEAD函數取到前一條記錄和后一條記錄的狀態和時間,分析記錄:
1-當前狀態不是“吃飯”,上一個狀態也不是“吃飯”,記錄不保留。
2-當前狀態不是“吃飯”,上一個狀態是“吃飯”,為上一個狀態提供結束時間,記錄不保留。
3-當前狀態是“吃飯”,記錄上一個和下一個狀態都是“吃飯”,記錄不保留。
4-當前狀態是“吃飯”,記錄下一個狀態時間,作為當前狀態結束時間,記錄保留。
如下圖:
然后我們就得到了下面一個表格:
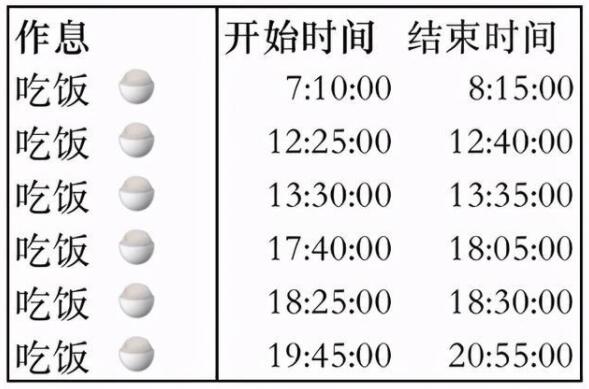
很明顯,這不是我們最后需要的。雖然我們找到了狀態為“吃飯”的行,并且通過窗口函數給它找到了狀態的結束實際。但是表格還需要再作一次處理,才能變成我們想要的結果。再次使用LAG\LEAD函數,我們需要把間隔在1小時內的“吃飯”狀態進行合并。
問題再次分解分解如下:
使用LAG\LEAD函數取到前一條記錄和后一條記錄的開始和結束時間,分析記錄:
1-當前記錄的“開始時間”減去上個時點的“結束時間”,如果小于1小時,該行記錄不保留。這一行記錄的狀態需要與上一行合并為一次“吃飯”狀態。下圖中綠色標注行。
2-下個時點的“開始時間”減去當前記錄的“結束時間”,如果小于1小時,該行記錄與下一行記錄合并。修改當前時點“吃飯”狀態的結束時間為下一個時點的結束時間。下圖橙色標注行。
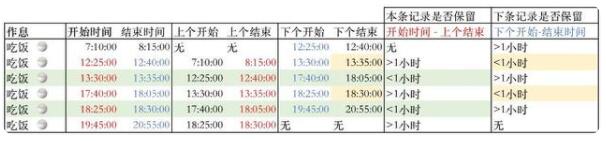
然后我們得到了下面的表格:
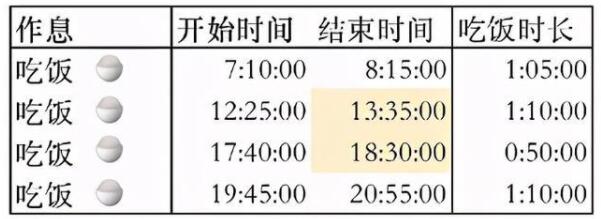
不管之前我們想的多復雜,需要用什么循環或者遞歸邏輯實現,但是現在問題解決了。我們通過這個表格回答了最開始題目的問題。這個人吃過4次飯,開始時間分別是7點10分、12點25分、17點40分、19點45分,每次持續的時間大約都在1小時。這個過程就是一個找到需要的信息,剔除無關信息的過程,只不過這個where有點復雜。
其實從分析問題的角度來看,這個問題本身就有點復雜,搞懂問題一般都需要一定的時間。從實現問題的角度來看,使用高級語言JAVA或者python實現更容易點,循環擼一遍有什么解決不了的(一遍不夠再來一遍)。用SQL實現,看起來有點復雜(可能是我常年使用SQL語言的原因,我覺得我好像分析問題的過程跟實現的過程是一樣的。),但是代碼量一定是最少的(性能可能也是最佳的)。再從可維護性上去綜合比較,還是使用SQL實現更優。
所以,后面再遇到類似的問題,你應該可以搞定了。如果有點困難,至少你可以再回過頭來看下這個例子,畢竟我花了好久來設計。
SQL問題解答:
- with ta as(
- select*
- from values
- (1001,'06:05:00','sleep')
- ,(1001,'07:10:00','eat')
- ,(1001,'08:15:00','phone')
- ,(1001,'11:20:00','phone')
- ,(1001,'12:25:00','eat')
- ,(1001,'12:40:00','phone')
- ,(1001,'13:30:00','eat')
- ,(1001,'13:35:00','sleep')
- ,(1001,'17:40:00','eat')
- ,(1001,'18:05:00','eat')
- ,(1001,'18:25:00','eat')
- ,(1001,'18:30:00','phone')
- ,(1001,'19:45:00','eat')
- ,(1001,'20:55:00','phone')
- ,(1001,'22:00:00','sleep')
- t(id,stime,stat))
- -- 5 計算根據前后記錄的時間,判斷記錄是否要被合并
- selectid,stime
- ,case whens2<=60 thenetime2 else etime end asetime,stat
- from(
- -- 4 計算前后記錄的時間差
- selectid,stime,etime,stat
- ,datediff(stime,etime1,'mi') ass1
- ,datediff(stime2,etime,'mi') ass2
- ,etime2
- from(
- -- 3 計算前后記錄的時間
- selectid,stime,etime,stat
- ,lag (stime,1) over(partition byid order by stime asc)as stime1
- ,lag (etime,1) over(partition byid order by stime asc)as etime1
- ,lead(stime,1) over(partition byid order by stime asc)as stime2
- ,lead(etime,1) over(partition byid order by stime asc)as etime2
- from(
- -- 2 識別前后記錄狀態,找到狀態結束時間
- selectid,stime,stat
- ,lead(stime,1) over(partition byid order by stime asc)as etime
- ,lag (stat,1) over(partition byid order by stime asc)as stat1
- ,lead(stat,1) over(partition byid order by stime asc)as stat2
- from(
- -- 1 把字符串轉時間
- selectid,to_date(concat('2021-06-29 ',stime),'yyyy-mm-dd hh:mi:ss') asstime,stat
- fromta)t1)t2
- wherestat='eat' and not(stat='eat' andstat1='eat' andstat2='eat'))t3)t4
- wheres1 >60 ors1 is null
- ;
























