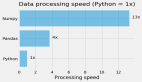
時(shí)間序列數(shù)據(jù)處理,不再使用Pandas
本文中,云朵君和大家一起學(xué)習(xí)了五個(gè)Python時(shí)間序列庫(kù),包括Darts和Gluonts庫(kù)的數(shù)據(jù)結(jié)構(gòu),以及如何在這些庫(kù)中轉(zhuǎn)換pandas數(shù)據(jù)框,并將其轉(zhuǎn)換回pandas。
Pandas DataFrame通常用于處理時(shí)間序列數(shù)據(jù)。對(duì)于單變量時(shí)間序列,可以使用帶有時(shí)間索引的 Pandas 序列。而對(duì)于多變量時(shí)間序列,則可以使用帶有多列的二維 Pandas DataFrame。然而,對(duì)于帶有概率預(yù)測(cè)的時(shí)間序列,在每個(gè)周期都有多個(gè)值的情況下,情況又如何呢?圖(1)展示了銷售額和溫度變量的多變量情況。每個(gè)時(shí)段的銷售額預(yù)測(cè)都有低、中、高三種可能值。盡管 Pandas 仍能存儲(chǔ)此數(shù)據(jù)集,但有專門的數(shù)據(jù)格式可以處理具有多個(gè)協(xié)變量、多個(gè)周期以及每個(gè)周期具有多個(gè)樣本的復(fù)雜情況。
 圖片
圖片
在時(shí)間序列建模項(xiàng)目中,充分了解數(shù)據(jù)格式可以提高工作效率。本文的目標(biāo)是介紹 DarTS、GluonTS、Sktime、pmdarima 和 Prophet/NeuralProphet 庫(kù)的數(shù)據(jù)格式。由于 Sktime、pmdarima 和 Prophet/NeuralProphet 都與 pandas 兼容,因此只需花更多時(shí)間學(xué)習(xí)。
- DarTS
- GluonTS
Pandas DataFrame是許多數(shù)據(jù)科學(xué)家的基礎(chǔ)。學(xué)習(xí)的簡(jiǎn)單方法是將其轉(zhuǎn)換為其他數(shù)據(jù)格式,然后再轉(zhuǎn)換回來。本文還將介紹長(zhǎng)格式和寬格式數(shù)據(jù),并討論庫(kù)之間的轉(zhuǎn)換。
請(qǐng)用 pip 安裝以下庫(kù):
!pip install pandas numpy matplotlib darts gluonts
!pip install sktime pmdarima neuralprophet獲取長(zhǎng)式數(shù)據(jù)集
加載一個(gè)長(zhǎng)式數(shù)據(jù)集。
這里我們將使用Kaggle.com上的沃爾瑪數(shù)據(jù)集,其中包含了45家商店的多元時(shí)間序列數(shù)據(jù)。我們選擇這個(gè)數(shù)據(jù)集是因?yàn)樗且粋€(gè)長(zhǎng)式數(shù)據(jù)集,所有組的數(shù)據(jù)都是垂直堆疊的。該數(shù)據(jù)集以Pandas數(shù)據(jù)幀的形式加載。
data = pd.read_csv('/walmart.csv', delimiter=",")
# 數(shù)據(jù)獲取:公眾號(hào):數(shù)據(jù)STUDIO 后臺(tái)回復(fù) 云朵君
data['ds'] = pd.to_datetime(data['Date'], format='%d-%m-%Y')
data.index = data['ds']
data = data.drop('Date', axis=1)
data.head()將字符串列 "Date" 轉(zhuǎn)換為 Pandas 中的日期格式是十分關(guān)鍵的,因?yàn)槠渌麕?kù)通常需要日期字段采用 Pandas 數(shù)據(jù)時(shí)間格式。圖(2)展示了最初的幾條記錄。
 圖(2):沃爾瑪數(shù)據(jù)
圖(2):沃爾瑪數(shù)據(jù)
該數(shù)據(jù)集包含
- Date - 日期 - 銷售周
- Store - 商店 - 商店編號(hào)
- Weekly sales - 周銷售額 - 商店的銷售額
- Holiday flag - 假日標(biāo)志 - 本周是否為特殊假日周 1 - 假日周 0 - 非假日周
- Temperature - 溫度 - 銷售當(dāng)天的溫度
- Fuel price - 燃料價(jià)格 - 該地區(qū)的燃料成本
兩個(gè)宏觀經(jīng)濟(jì)指標(biāo),即消費(fèi)者價(jià)格指數(shù)和失業(yè)率,對(duì)零售額有影響。沃爾瑪數(shù)據(jù)集堆疊了 45 家商店的多個(gè)序列,每家店有 143 周的數(shù)據(jù)。
使數(shù)據(jù)集成為寬格式
寬格式數(shù)據(jù)結(jié)構(gòu)是指各組多元時(shí)間序列數(shù)據(jù)按照相同的時(shí)間索引橫向附加,接著我們將按商店和時(shí)間來透視每周的商店銷售額。
# 將數(shù)據(jù)透視成正確的形狀
storewide = data.pivot(index='ds', columns='Store', values='Weekly_Sales')
storewide = storewide.loc[:,1:10] # Plot only Store 1 - 10
# 繪制數(shù)據(jù)透視表
storewide.plot(figsize=(12, 4))
plt.legend(loc='upper left')
plt.title("Walmart Weekly Sales of Store 1 - 10") 圖(3): 沃爾瑪商店的銷售額
圖(3): 沃爾瑪商店的銷售額
10 家商店的每周銷售額如圖(3)所示:
: 商店銷售額曲線圖") (4): 商店銷售額曲線圖
(4): 商店銷售額曲線圖
檢查一下時(shí)間索引,它是一個(gè) Pandas DateTimeIndex。
print(storewide.index) 圖片
圖片
除了每周商店銷售額外,還可以對(duì)其他任何列進(jìn)行同樣的長(zhǎng)格式到寬格式的轉(zhuǎn)換。
Darts
Darts 庫(kù)是如何處理長(zhǎng)表和寬表數(shù)據(jù)集的?
Python的時(shí)間序列庫(kù)darts以投擲飛鏢的隱喻為名,旨在幫助數(shù)據(jù)分析中的準(zhǔn)確預(yù)測(cè)和命中特定目標(biāo)。它為處理各種時(shí)間序列預(yù)測(cè)模型提供了一個(gè)統(tǒng)一的界面,包括單變量和多變量時(shí)間序列。這個(gè)庫(kù)被廣泛應(yīng)用于時(shí)間序列數(shù)據(jù)科學(xué)。
Darts的核心數(shù)據(jù)類是其名為TimeSeries的類。它以數(shù)組形式(時(shí)間、維度、樣本)存儲(chǔ)數(shù)值。
- 時(shí)間:時(shí)間索引,如上例中的 143 周。
- 維度:多元序列的 "列"。
- 樣本:列和時(shí)間的值。在圖(A)中,第一周期的值為 [10,15,18]。這不是一個(gè)單一的值,而是一個(gè)值列表。例如,未來一周的概率預(yù)測(cè)值可以是 5%、50% 和 95% 量級(jí)的三個(gè)值。習(xí)慣上稱為 "樣本"。
Darts--來自長(zhǎng)表格式 Pandas 數(shù)據(jù)框
轉(zhuǎn)換長(zhǎng)表格式沃爾瑪數(shù)據(jù)為darts格式只需使用from_group_datafrme()函數(shù),需要提供兩個(gè)關(guān)鍵輸入:組IDgroup_cols和時(shí)間索引time_col。在這個(gè)示例中,group_cols是Store列,而time_col是時(shí)間索引ds。
from darts import TimeSeries
darts_group_df = TimeSeries.from_group_dataframe(data, group_cols='Store', time_col='ds')
print("The number of groups/stores is: ", len(darts_group_df))
print("The number of time period is: ", len(darts_group_df[0]))商店 1 的數(shù)據(jù)存儲(chǔ)在 darts_group_df[0] 中,商店 2 的數(shù)據(jù)存儲(chǔ)在 darts_group_df[1] 中,以此類推。一共有 45 個(gè)商店,因此飛鏢數(shù)據(jù) darts_group_df 的長(zhǎng)度為 45。每個(gè)商店有 143 周,因此商店 1 darts_group_df[0] 的長(zhǎng)度為 143。
The number of groups/stores is: 45
The number of time period is: 143darts_group_df 圖(5):沃爾瑪商店銷售數(shù)據(jù)的darts數(shù)據(jù)格式
圖(5):沃爾瑪商店銷售數(shù)據(jù)的darts數(shù)據(jù)格式
圖 (5) 表示(ds: 143,component:6,sample:1)143 周,6 列,每個(gè)商店和周有 1 個(gè)樣本。商店 1 的數(shù)據(jù)為 darts_group_df[0]。可以使用 .components 函數(shù)列出列名。
darts_group_df[0].componentsIndex([‘Weekly_Sales’, ‘Holiday_Flag’, ‘Temperature’, ‘Fuel_Price’, ‘CPI’,
‘Unemployment’], dtype=’object’, name=’component’)Darts--從寬表格式的pandas數(shù)據(jù)框轉(zhuǎn)換
繼續(xù)學(xué)習(xí)如何將寬表格式數(shù)據(jù)框轉(zhuǎn)換為darts數(shù)據(jù)結(jié)構(gòu)。
你只需使用 Darts 中 TimeSeries 類的.from_dataframe()函數(shù):
from darts import TimeSeries
darts_df = TimeSeries.from_dataframe(storewide)
darts_df輸出結(jié)果如圖 (F) 所示:
 圖(6):Darts數(shù)據(jù)數(shù)組
圖(6):Darts數(shù)據(jù)數(shù)組
圖(6)表示(ds: 143, component:10, sample:1)143 周、10 列以及每個(gè)商店和周的 1 個(gè)樣本。可以展開小圖標(biāo)查看組件,組件指的是列名。
Darts--繪圖
如何使用 Darts 繪制曲線?
繪圖語法與 Pandas 中的一樣簡(jiǎn)單。只需執(zhí)行 .plot():
darts_df.plot() 圖(7):10個(gè)序列的曲線圖
圖(7):10個(gè)序列的曲線圖
Darts--單變量 Pandas 序列
如果我們只有一個(gè)序列呢?如何轉(zhuǎn)換為 Darts?
列 storewide[1] 是商店 1 的 Pandas 序列。可以使用 .from_series() 將 Pandas 序列方便地轉(zhuǎn)換為 Darts:
darts_str1 = TimeSeries.from_series(storewide[1])
darts_str1圖 (8) 顯示了輸出結(jié)果。如 (ds:143, component:1, sample:1) 所示,每周有 143 周、1 列和 1 個(gè)樣本。
 圖(8):序列的數(shù)據(jù)結(jié)構(gòu)
圖(8):序列的數(shù)據(jù)結(jié)構(gòu)
繪制過程如圖(9)所示:
darts_str1.plot() 圖(9):?jiǎn)巫兞康那€圖
圖(9):?jiǎn)巫兞康那€圖
Darts - 轉(zhuǎn)換回 Pandas
如何將 Darts 數(shù)據(jù)集轉(zhuǎn)換回 Pandas 數(shù)據(jù)框?
只需使用 .pd_dataframe():
# 將 darts 數(shù)據(jù)框轉(zhuǎn)換為 pandas 數(shù)據(jù)框
darts_to_pd = TimeSeries.pd_dataframe(darts_df)
darts_to_pd輸出結(jié)果是一個(gè)二維 Pandas 數(shù)據(jù)框:

不是所有的Darts數(shù)據(jù)都可以轉(zhuǎn)換成二維Pandas數(shù)據(jù)框。比如一周內(nèi)商店的概率預(yù)測(cè)值,無法存儲(chǔ)在二維Pandas數(shù)據(jù)框中,可以將數(shù)據(jù)輸出到Numpy數(shù)組中。
Darts--轉(zhuǎn)換為 Numpy 數(shù)組
Darts 可以讓你使用 .all_values 輸出數(shù)組中的所有值。缺點(diǎn)是會(huì)丟棄時(shí)間索引。
# 將所有序列導(dǎo)出為包含所有序列值的 numpy 數(shù)組。
# https://unit8co.github.io/darts/userguide/timeseries.html#exporting-data-from-a-timeseries
TimeSeries.all_values(darts_df) 圖片
圖片
學(xué)習(xí)了 Darts 的數(shù)據(jù)結(jié)構(gòu)后,再學(xué)習(xí)另一個(gè)流行的時(shí)間序列庫(kù) - Gluonts 的數(shù)據(jù)結(jié)構(gòu)。
Gluonts
Gluonts是亞馬遜開發(fā)的處理時(shí)間序列數(shù)據(jù)的Python庫(kù),包含多種建模算法,特別是基于神經(jīng)網(wǎng)絡(luò)的算法。這些模型可以處理單變量和多變量序列,以及概率預(yù)測(cè)。Gluonts數(shù)據(jù)集是Python字典格式的時(shí)間序列列表。可以將長(zhǎng)式Pandas數(shù)據(jù)框轉(zhuǎn)換為Gluonts。
Gluonts--從長(zhǎng)表格式 Pandas 數(shù)據(jù)框
gluons.dataset.pandas 類有許多處理 Pandas 數(shù)據(jù)框的便捷函數(shù)。要在 Pandas 中加載長(zhǎng)表格式數(shù)據(jù)集,只需使用 .from_long_dataframe():
# Method 1: from a long-form
from gluonts.dataset.pandas import PandasDataset
data_long_gluonts = PandasDataset.from_long_dataframe(
data,
target="Weekly_Sales",
item_id="Store",
timestamp='ds',
freq='W')
data_long_gluonts打印 Gluonts 數(shù)據(jù)集時(shí),會(huì)顯示元數(shù)據(jù):
PandasDataset<size=45, freq=W, num_feat_dynamic_real=0,
num_past_feat_dynamic_real=0,
num_feat_static_real=0,
num_feat_static_cat=0,
static_cardinalities=[]>Gluonts--從寬表格式的 Pandas 數(shù)據(jù)框
PandasDataset() 類需要一個(gè)時(shí)間序列字典。因此,首先要將寬表 Pandas 數(shù)據(jù)框轉(zhuǎn)換為 Python 字典,然后使用 PandasDataset():
# Method 2: from a wide-form
from gluonts.dataset.pandas import PandasDataset
data_wide_gluonts = PandasDataset(dict(storewide))
data_wide_gluonts通常,我們會(huì)將 Pandas 數(shù)據(jù)框分成訓(xùn)練數(shù)據(jù)("實(shí)時(shí)")和測(cè)試數(shù)據(jù)("非實(shí)時(shí)"),如下圖所示。
len_train = int(storewide.shape[0] * 0.85)
len_test = storewide.shape[0] - len_train
train_data = storewide[0:len_train]
test_data = storewide[len_train:]
[train_data.shape, test_data.shape] # The output is [(121,5), (22,5)如前所述,Gluonts 數(shù)據(jù)集是 Python 字典格式的數(shù)據(jù)列表。我們總是可以使用 Gluonts 中的 ListDataset()類。我們使用 ListDataset() 轉(zhuǎn)換數(shù)據(jù):
Gluonts - ListDataset() 進(jìn)行任何常規(guī)轉(zhuǎn)換
Gluonts 數(shù)據(jù)集是 Python 字典格式的時(shí)間序列列表,可使用 ListDataset() 作為一般轉(zhuǎn)換工具,該類需要時(shí)間序列的基本元素,如起始時(shí)間、值和周期頻率。
將圖(3)中的寬格式商店銷售額轉(zhuǎn)換一下。數(shù)據(jù)幀中的每一列都是帶有時(shí)間索引的 Pandas 序列,并且每個(gè) Pandas 序列將被轉(zhuǎn)換為 Pandas 字典格式。字典將包含兩個(gè)鍵:字段名.START 和字段名.TARGET。因此,Gluonts 數(shù)據(jù)集是一個(gè)由 Python 字典格式組成的時(shí)間序列列表。
def convert_to_gluonts_format(dataframe, freq):
start_index = dataframe.index.min()
data = [{
FieldName.START: start_index,
FieldName.TARGET: dataframe[c].values,
}
for c in dataframe.columns]
#print(data[0])
return ListDataset(data, freq=freq)
train_data_lds = convert_to_gluonts_format(train_data, 'W')
test_data_lds = convert_to_gluonts_format(test_data, 'W')
train_data_lds生成的結(jié)果是由Python字典列表組成,其中每個(gè)字典包含 start 關(guān)鍵字代表時(shí)間索引,以及 target 關(guān)鍵字代表對(duì)應(yīng)的值。
 圖片
圖片
Gluonts - 轉(zhuǎn)換回 Pandas
如何將 Gluonts 數(shù)據(jù)集轉(zhuǎn)換回 Pandas 數(shù)據(jù)框。
Gluonts數(shù)據(jù)集是一個(gè)Python字典列表。要將其轉(zhuǎn)換為Python數(shù)據(jù)框架,首先需使Gluonts字典數(shù)據(jù)可迭代。然后,枚舉數(shù)據(jù)集中的鍵,并使用for循環(huán)進(jìn)行輸出。
在沃爾瑪商店的銷售數(shù)據(jù)中,包含了時(shí)間戳、每周銷售額和商店 ID 這三個(gè)關(guān)鍵信息。因此,我們需要在輸出數(shù)據(jù)表中創(chuàng)建三列:時(shí)間戳、目標(biāo)值和索引。
# 將 gluonts 數(shù)據(jù)集轉(zhuǎn)換為 pandas 數(shù)據(jù)幀
# Either long-form or wide-form
the_gluonts_data = data_wide_gluonts # you can also test data_long_gluonts
timestamps = [] # This is the time index
target_values = [] # This is the weekly sales
index = [] # this is the store in our Walmart case
# Iterate through the GluonTS dataset
for i, entry in enumerate(the_gluonts_data):
timestamp = entry["start"]
targets = entry["target"]
# Append timestamp and target values for each observation
for j, target in enumerate(targets):
timestamps.append(timestamp)
target_values.append(target)
index.append(i) # Keep track of the original index for each observation
# Create a pandas DataFrame
df = pd.DataFrame({
"timestamp": timestamps,
"target": target_values,
"original_index": index
})
print(df) 圖片
圖片
Darts和Gluonts支持復(fù)雜數(shù)據(jù)結(jié)構(gòu)的建模算法,可以建立多個(gè)時(shí)間序列的全局模型和概率預(yù)測(cè)。當(dāng)所有時(shí)間序列中存在一致的基本模式或關(guān)系時(shí),它就會(huì)被廣泛使用。沃爾瑪案例中的時(shí)間序列數(shù)據(jù)是全局模型的理想案例。相反,如果對(duì)多個(gè)時(shí)間序列中的每個(gè)序列都擬合一個(gè)單獨(dú)的模型,則該模型被稱為局部模型。在沃爾瑪數(shù)據(jù)中,我們將建立45個(gè)局部模型,因?yàn)橛?5家商店。
在熟悉了Darts和Gluonts的數(shù)據(jù)結(jié)構(gòu)后,我們將繼續(xù)學(xué)習(xí)Sktime、pmdarima和Prophet/NeuralProphet的數(shù)據(jù)格式,它們與pandas兼容,因此無需進(jìn)行數(shù)據(jù)轉(zhuǎn)換,這將使學(xué)習(xí)變得更加容易。
Sktime
Sktime旨在與scikit-learn集成,利用各種scikit-learn時(shí)間序列算法。它提供了統(tǒng)一的界面和實(shí)現(xiàn)常見的時(shí)間序列分析任務(wù),簡(jiǎn)化了時(shí)間序列數(shù)據(jù)處理過程。提供了預(yù)測(cè)、分類和聚類等算法,可用于處理和分析時(shí)間序列數(shù)據(jù)。
import lightgbm as lgb
from sktime.forecasting.compose import make_reduction
lgb_regressor = lgb.LGBMRegressor(num_leaves = 10,
learning_rate = 0.02,
feature_fraction = 0.8,
max_depth = 5,
verbose = 0,
num_boost_round = 15000,
nthread = -1
)
lgb_forecaster = make_reduction(lgb_regressor, window_length=30, strategy="recursive")
lgb_forecaster.fit(train)Pmdarima
Pmdarima是Python封裝程序,基于流行的"statsmodels"庫(kù),將ARIMA和SARIMA模型合并在一起。它能自動(dòng)選擇最佳ARIMA模型,功能強(qiáng)大且易于使用,接受一維數(shù)組或pandas Series作為數(shù)據(jù)輸入。
import pmdarima as pm
model = pm.auto_arima(train,
d=None,
seasnotallow=False,
stepwise=True,
suppress_warnings=True,
error_actinotallow="ignore",
max_p=None,
max_order=None,
trace=True) 圖片
圖片
Prophet/NeuralProphet
Prophet是Facebook開發(fā)的時(shí)間序列預(yù)測(cè)庫(kù),具有自動(dòng)檢測(cè)季節(jié)性模式、處理缺失數(shù)據(jù)以及納入假日效應(yīng)的能力。它擁有用戶友好的界面和交互式plotly風(fēng)格的輸出,分析師幾乎不需要人工干預(yù)即可生成預(yù)測(cè)結(jié)果。Prophet因其靈活的趨勢(shì)建模功能和內(nèi)置的不確定性估計(jì)而深受歡迎。該庫(kù)可用于執(zhí)行單變量時(shí)間序列建模,需要使用Pandas數(shù)據(jù)框架,其中列名為['ds', 'y']。
這里加載了一個(gè) Pandas 數(shù)據(jù)框 "bike" 來訓(xùn)練一個(gè) Prophet 模型。
import pandas as pd
from prophet import Prophet
bike.columns = ['ds','y']
m = Prophet()
m.fit(bike)Prophet的圖像很吸引人。
 圖(10):Prophet
圖(10):Prophet
NeuralProphet是基于先知框架的神經(jīng)網(wǎng)絡(luò)架構(gòu),加強(qiáng)了先知的加法模型,允許更靈活、更復(fù)雜地對(duì)時(shí)間序列數(shù)據(jù)進(jìn)行建模。它集成了Prophet的優(yōu)勢(shì),包括自動(dòng)季節(jié)性檢測(cè)和假日效應(yīng)處理,并專注于單變量時(shí)間序列預(yù)測(cè)。以下是一個(gè)使用Pandas數(shù)據(jù)幀來訓(xùn)練NeuralProphet模型的示例。
from neuralprophet import NeuralProphet
df = pd.read_csv(path + '/bike_sharing_daily.csv')
# Create a NeuralProphet model with default parameters
m = NeuralProphet()
# Fit the model
metrics = m.fit(df)它的繪圖能力就像Prophet一樣吸引人。
圖(11): neuralprophet
結(jié)論
本文中,云朵君和大家一起學(xué)習(xí)了五個(gè)Python時(shí)間序列庫(kù),包括Darts和Gluonts庫(kù)的數(shù)據(jù)結(jié)構(gòu),以及如何在這些庫(kù)中轉(zhuǎn)換pandas數(shù)據(jù)框,并將其轉(zhuǎn)換回pandas。此外,還介紹了Sktime、pmdarima和Prophet/NeuralProphet庫(kù)。這些庫(kù)都有各自的優(yōu)勢(shì)和特點(diǎn),選擇使用哪個(gè)取決于對(duì)速度、與其他Python環(huán)境的集成以及模型熟練程度的要求。