













Spark Streaming精進之前必須了解的基本概念
Spark整體介紹
Spark是一個快速的,多用途的計算系統。這是來自官網的自我介紹。一般敢自稱系統的都是有兩把刷子的,況且還是多用途的計算系統。Spark計算系統包含如下功能組件

Spark Core: Spark的核心功能模塊。
Spark SQL: 用于處理結構化數據。
MLlib:用于機器學習。
GraphX:用于圖像處理。
Spark Streaming:用于處理實時數據流。
包含如此多的功能,自稱多功能計算系統也是可以的。這篇文章幫大家梳理一下學習Spark Streaming過程中可能會讓你產生困惑的基本概念。
RDD
Spark Core 是 Spark的核心模塊,這個模塊提供了一個核心概念叫做RDD(resilient distributed dataset)。你可以簡單的把它理解成一個數據片段集合,你要處理的源數據文件可以分解成很多個RDD。Spark為RDD提供了兩種類型的操作,一種是transformations,一種是 action。
transformations:如果一個RDD經過某種操作之后,生成一個新的RDD,那么這個操作就是transaction的。比如,map,flatMap,filter等。 action:對一個RDD進行計算操作,以生成某種結果,比如reduce,count等操作。
注意:所有的transformations都是Lazy的,也就是說只有碰到action操作的時候才會執行前面的transformations操作。
DStream
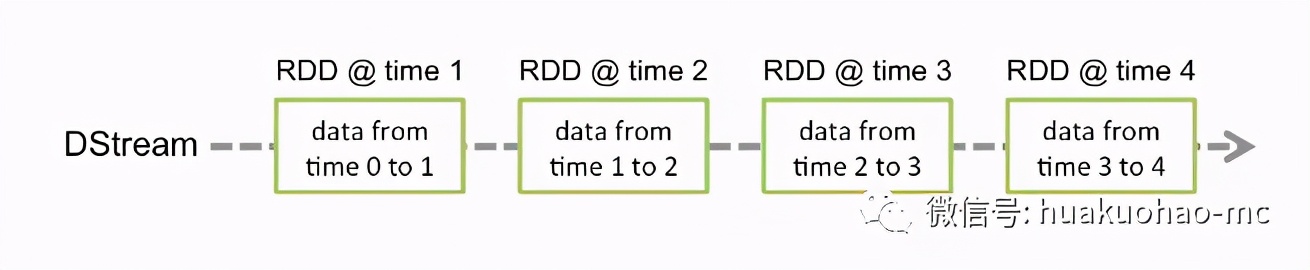
Spark Streaming 是用來處理流式數據的,假設我們規定每隔一秒鐘(通過duration設置)取一次數據,那么這段時間內積贊的數據就稱為一個batch,里面的數據就用DStream表示。從編寫代碼的角度來看,你可以把DStream和RDD同等對待,因為他們的算子操作都是一樣的。但是他們的數據結構還是有著本質不同的,我們可以把DStream簡單的理解成是RDD加上了時間戳。如下圖
DAG
Spark 使用DAG 進行數據建模,DAG 被稱為有向無環圖,有向無環圖的定義是這樣的 "在圖論中,如果一個有向圖從任意頂點出發無法經過若干條邊回到該點,則這個圖是一個有向無環圖(DAG,directed acyclic graph)",我們通過一個簡單的例子來感受一下,Spark是如何使用DAG建模的。
下面的代碼可以完成一段文本內容的各個單詞的數量統計。
- var textFile = sc.textFile(args[1]);
- var result = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b);
- result.saveAsTextFile(args[2]);
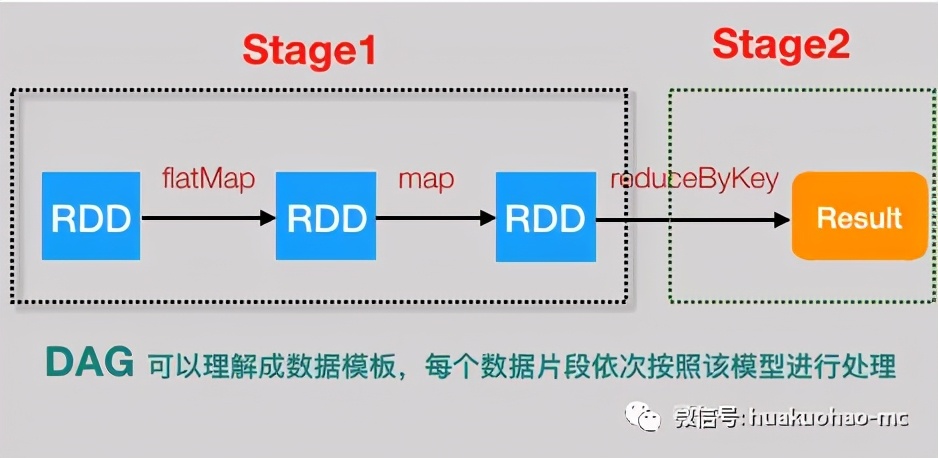
上面這段代碼可以用下面這個圖表示
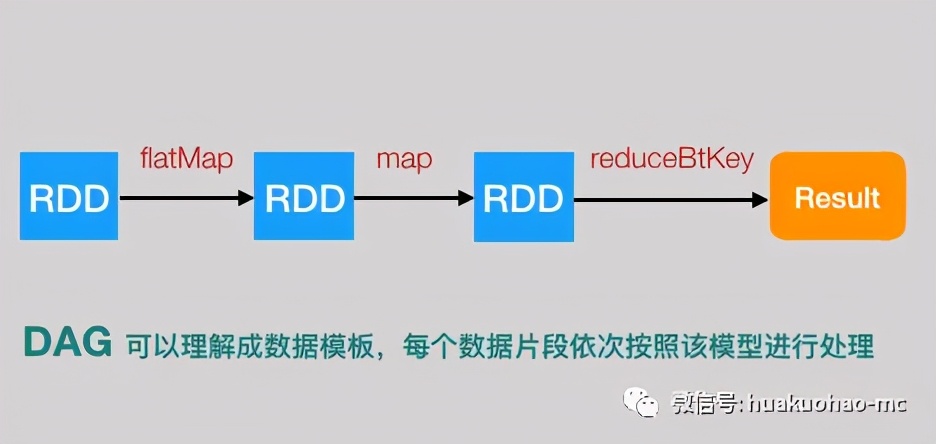
這就是一個簡單的DAG模型,數據按照方向流動,再也回不到原點。Spark Streaming將這個DAG模型,不斷的應用到每一個Batch里面的數據中。大家可以把DAG模型理解成類,它是數據處理的模版,而每個Batch里面的數據就是不同的實例對象。
Job,Stage,Task
Spark應用程序啟動之后,我們會利用Spark提供的監控頁面來查看程序的運行情況。在頁面上會看到Job,Stage,Task等內容展示,如果不理解他們代表什么意思,那么Spark好心好意提供的監控頁面對我們來說就毫無意義。 下面給大家簡單說一下這些概念到底什么意思,以及他們之間的關系。
先來看個圖
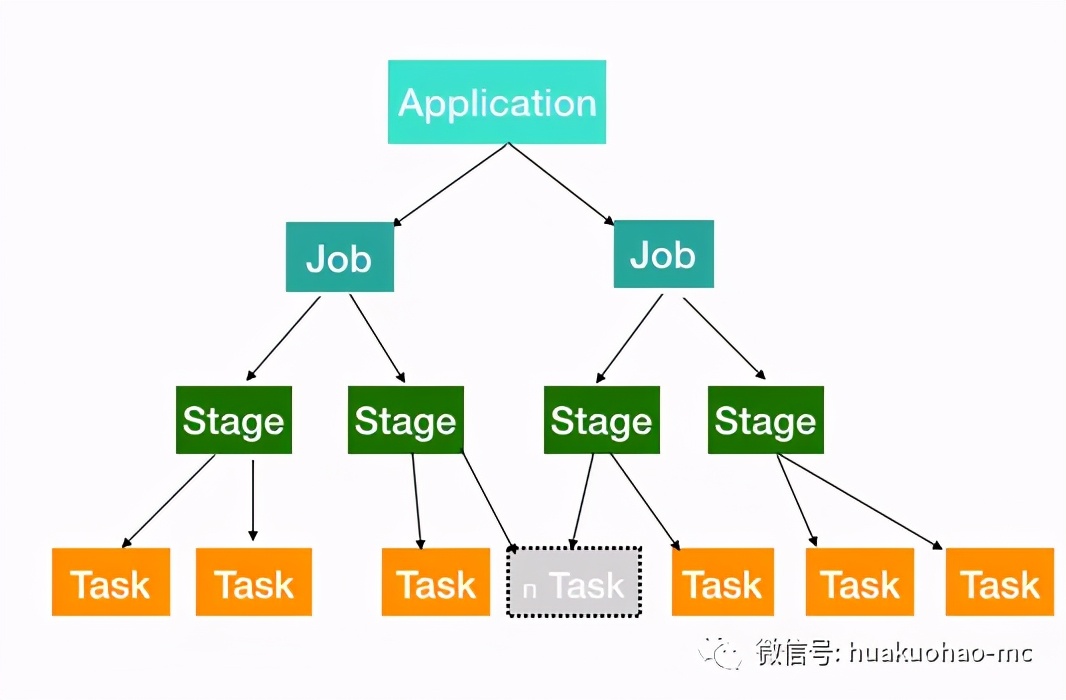
從圖中可以看出,一個Application被分解成多個Job,每個Job又分解成多個Stage,Stage又會分解成多個Task,而Task是任務運行的最小單元,最終會被Executor執行。
Application:簡單的說就是我們寫的應用代碼,啟動起來之后就是一個Application。
Job:由Spark的action算子觸發。也就是每遇到一個action算子就會觸發一個Job任務,這個時候就會執行前面的一系列transformations操作。
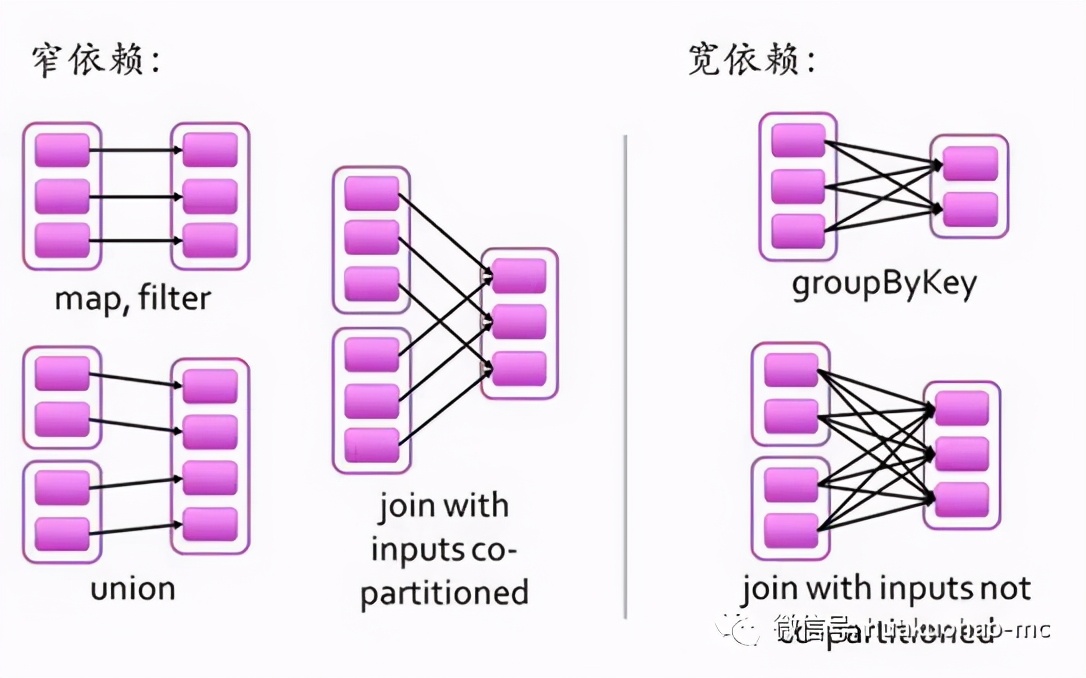
Stage:Job任務會繼續分解成Stage,Stage是根據DAG的寬窄依賴來劃分,也就是RDD之間的依賴關系。從后往前,每遇到一個寬依賴就劃分為一個Stage。
寬依賴(Shuffle/Wide Dependency):父RDD的分區和子RDD的分區是一對多或者多對多的關系。比如groupByKey,reduceByKey,join等操作
窄依賴(Narrow Dependency):父RDD的分區和子RDD的分區的關系是一對一或者多對一的關系,比如map,flatmap,filter等操作。
寬窄依賴的定義可以用如下圖,形象的展示。
拿文章開頭的單詞統計程序為例,Stage劃分情況應該是這樣的。
task:Stage包含很多Task,每個Task會執行Stage中包含的算子。
以上就是Spark精進之路上必須了解的基本概念,希望對各位有幫助。










