













《吃透微服務》- 服務追蹤之Sleuth
本文轉載自微信公眾號「小菜良記」,作者蔡不菜丶。轉載本文請聯系小菜良記公眾號。
這么這篇我們繼續我們的主題 《吃透微服務》 ,繼續了解分布式系統中解決鏈路追蹤的方案 --- Sleuth。吃透 當然可以作為一個噱頭,但也可以作為一個目標!
微服務的好壞我們不再爭議,最近看到很多反面宣傳微服務的特性,不知道是否大數據精準投喂~ ps:估計后臺人物畫像已經標簽為一個反微分子了。這當然是一句玩笑話,結束玩笑,我們來為微服務的學習添磚加瓦!
微服務的關鍵在于拆分服務,但是關鍵不在 微 ,而在于合適的大小。當我們跨出拆分服務的那一刻起,我們就得對我們拆分后的服務負責,這個是一個程序員應有的擔當!當服務出現問題的時候,你是否還苦于排查,而無從定位。線上的代碼我們無法 debug,找出問題的時刻往往出現以下對話:
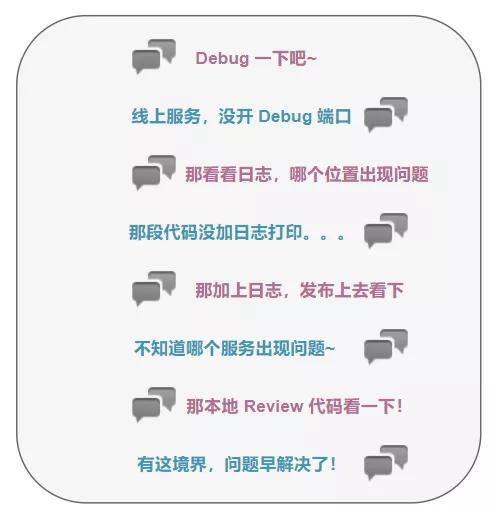
除了無奈的苦笑,只能盲目的摸索,終于有一天程序員小菜不再妥協,力求解決該問題。咱們能不能搞個類似監控的功能,當請求進來的時候,分配一個身份令牌的給它,當它在微服務中游走的時候,每個服務都會留下它的痕跡,當它出現問題的時候,我們只需要檢查游走到哪一個微服務,相當于畫一個行為軌跡,通過行為軌跡追蹤服務的調用問題!沾沾自喜的同時犯嘀咕了,這說起來容易,實現起來好像有點困難~退堂鼓即將敲響,便想到微服務中怎么可能沒有人想到該問題,于是便游走于微服務組件之中,力求找到解決問題的實現。終于,Sleuth 出現了。
Sleuth
一、認識 Sleuth
前面做了那么多的鋪墊,就是想引出 Sleuth 這玩意。洋洋灑灑說了一堆,那就簡單用一句話描述一下它的作用:在分布式系統中提供追蹤解決方案。它大量借用了 Google Dapper 的設計,難道又是個換殼的玩意?
我們先來了解一下 Sleuth 中的術語和相關概念,只為了讓我們更加專業,更好 吹著牛x談架構
- Trace
由一組 Trace Id 相同的 Span 串聯形成一個樹狀結構。為了實現請求追蹤,當請求到達分布式系統的入口端點時,只需要服務跟蹤框架為該請求創建一個唯一的標識(即 Trace Id),同時在恩不是系統內部流轉的時候,框架是中保持傳遞該唯一值,直到整個請求的返回。那么我們就可以使用該唯一標識將所有的請求串聯起來,形成一條完整的請求鏈路。
- Span
代表了一組基本的工作單元。為了統計各處理單元的延遲,當請求到達各個服務組件的時候,也通過一個唯一標識(SpanId)來標記它的開始,具體過程和結束。通過 SpanId 的開始和結束時間戳,就能統計該 Span 的調用時間,除此之外,我們還可以獲取如事件的名稱,請求信息等元數據
- Annotation
用于記錄一段時間內的事件。內部使用的重要注釋如下:
- cs(Client Send):客戶端發出請求,開始一個請求的事件
- sr(Server Received) :服務端接受到請求開始進行處理。sr - cs = 網絡延遲(服務調用的時間)
- ss(Server Send):服務端處理完畢準備發送到客戶端。ss -sr = 服務器上的請求處理時間
- cr(Client Reveived):客戶端接受到服務端的響應,請求結束。cr - sr = 請求的總時間
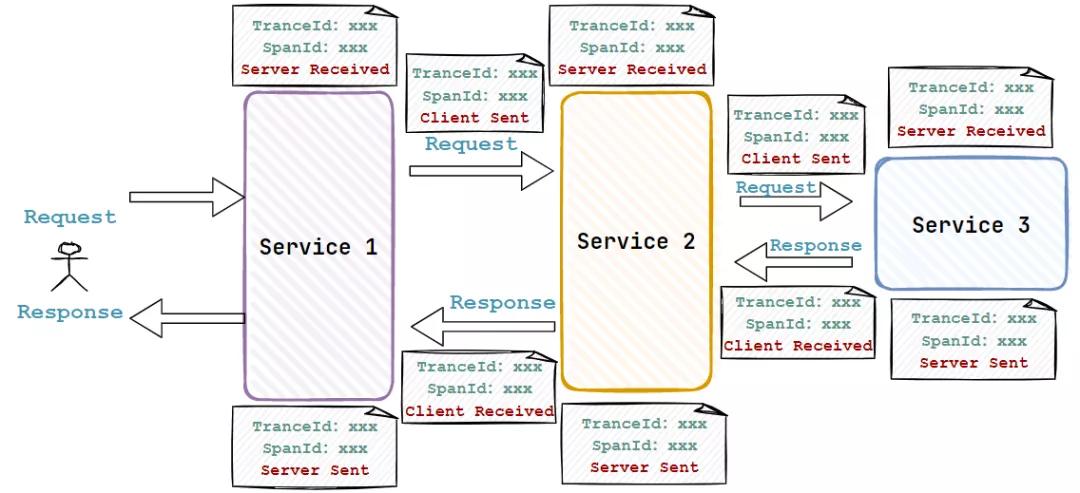
理解完三個概念,我們下面就直接上手認識!
二、掌握 Sleuth
我們老樣子請出我們的微服務項目:
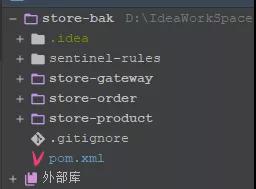
簡簡單單幾個服務做個自我介紹
- store-gateway: 服務網關
- store-order: 訂單服務
- store-product: 產品服務
然后我們需要在父工程中引入 Sleuth 依賴
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-sleuth</artifactId>
- </dependency>
直接在父工程的 dependencies 中引入,這樣子每個子服務就可以不同重復引入該依賴
然后開始我們的簡易代碼模式:
store-order服務
OrderController:
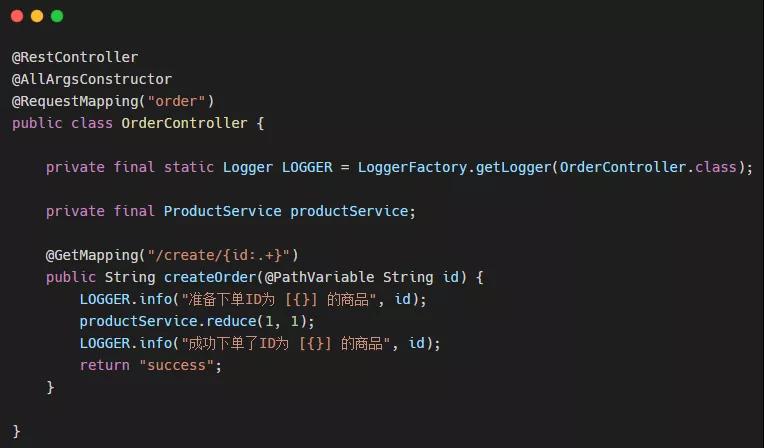
ProductService:
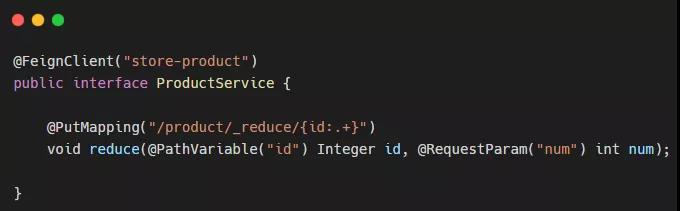
store-product 服務
ProductController:
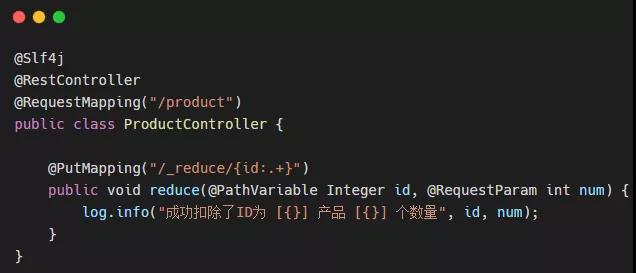
我們在訂單服務 中使用 Feign 遠程調用 產品服務 中的接口,然后啟動服務調用后看控制臺打印:

注意看我圈出來的部分,有沒有發現了些許不同,沒錯!這一串字符中包含的信息有 服務名 / TraceId / SpanId。依次調用有一個全局的 TraceId,將調用鏈路穿起來。通過分析微服務的日志,不難看出請求的具體過程。但是有個弊端,但服務數量增多,或者日志數量增多,從日志文件中撈出某個請求的調用過程,可并非是件易事,那么有沒有一個可以全文檢索和可視化展示的插件幫助我們解決該問題?既然提出問題,小菜自然已經找到解決問題的方法!那就是 ZipKin
三、使用 ZipKin
ZipKin 是 Twitter 開源的一個項目,它也是基于 Google Dapper 實現的,主要作用便是解決我們上面提到的問題:收集服務的定時數據,以解決微服務架構中的延遲問題,包括數據的收集,存儲,查找和展現
我們可以使用它來收集各個服務器上請求鏈路的跟蹤數據,并通過它提供的 REST API 接口來輔助我們查詢跟蹤數據以實現對分布式系統的監控程序,從而及時地發現系統中出現的延遲升高問題并找出系統性能瓶頸的根源!
我們除了面向開發的 API 接口之外, ZipKin 也提供了方便的 UI 組件來幫我們更加直觀的搜索跟蹤信息和分析請求鏈路明細,比如:可以查詢某段時間內各用戶請求的處理時間等。
聽到 UI 組件是不是感到眼前一亮,說明我們可以通過控制臺更好的管理鏈路跟蹤
不僅如此,ZipKin 還提供了可插拔式的數據存儲方式,例如:In-Memory、MySQL、Cassandra以及Elasticsearch。支持方式不算少,總有一種你喜歡的!
我們來看看 ZipKin 的基礎架構圖:
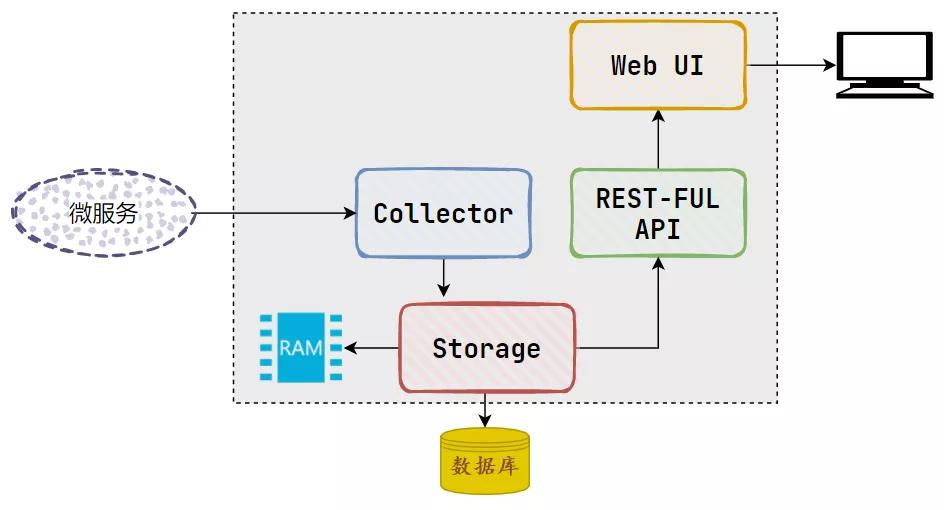
可以看出 ZipKin 結構并不復雜,有四個核心組件構成:
- Collector:收集器組件。主要用于處理外部系統發現過來的跟蹤信息,然后將這些信息轉換為 ZipKin 內部處理的 Span 格式,以便支持后續的存儲、分析、展示等功能
- Storage: 存儲組件。主要用于對處理收集器接收到的跟蹤信息,默認會將這些信息存儲到內存中,我們可以修改存儲策略,將其存儲到我們的其他存儲倉庫中
- RestFul API:API 組件。用于提供外部訪問的接口,比如客戶端的跟蹤信息,或外接系統的訪問信息
- WebUI:UI 組件。基于 API 組件實現的上層應用,通過 UI 組件用戶可以方便而直觀地查詢和分析跟蹤信息
因此 ZiPKin 使用起來有些類似我們上篇說到的 Sentinel ,它分為 服務端 和 客戶端。
客戶端就是指微服務中的應用,在客戶端中配置服務端的 URL 地址,一旦發生服務間的調用的時候,會被配置在微服務中的 Sleuth 的監聽器監聽,并生相應的 Trace 和 Span 信息發送給服務端。
1. ZipKin 服務端
服務端是一個現成的 SpringBoot 服務,我們只需要下載 jar 包 ,便可以直接運行!下載地址
然后我們通過命令行的方式啟動即可:
- java -jar zipkin-server-2.12.9-exec.jar
成功啟動后通過訪問 http://localhost:9411 可以看到以下頁面:
到這步為止,我們服務端就已經成功安裝。然后回到我們的客戶端集成上去
2. ZipKin 客戶端
我們需要在每個服務中引入 ZipKin 的依賴
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-zipkin</artifactId>
- </dependency>
然后在配置文件中進行配置:
- spring:
- zipkin:
- base-url: http://127.0.0.1:9411/ #zipkin 服務端地址
- discoveryClientEnabled: false #讓nacos把它當成一個URL,而不要當做服務名
- sleuth:
- sampler:
- probability: 1.0 #采樣的百分比
然后我們回到項目中,啟動項目通過訪問我們上面已經定義好的接口訪問微服務,之后在 ZipKin 的UI界面進行觀察

可以看到已經出現了我們剛剛訪問微服務的請求鏈路了,點擊其中一條記錄可以查看具體的訪問路線。

通過對請求鏈路進行追蹤,就可以確定服務的哪一個模塊更耗時,進而可以進行優化或者排查 Bug。
3. ZipKin 持久化
在 ZipKin 中默認會將鏈路跟蹤的數據保存到內存中,但是這種方式明顯不適合于生產環境。因此在 ZipKin 中支持將追蹤鏈路的數據持久化到 mysql 數據庫中或 elasticsearch 中。
MySQL
- 首先我們需要配置數據庫信息
- CREATE TABLE IF NOT EXISTS zipkin_spans (
- `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
- `trace_id` BIGINT NOT NULL,
- `id` BIGINT NOT NULL,
- `name` VARCHAR(255) NOT NULL,
- `parent_id` BIGINT,
- `debug` BIT(1),
- `start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
- `duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
- ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
- ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
- ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
- ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
- ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
- ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
- CREATE TABLE IF NOT EXISTS zipkin_annotations (
- `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
- `trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
- `span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
- `a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
- `a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
- `a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
- `a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
- `endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
- `endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
- `endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
- `endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
- ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
- ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
- ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
- ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
- ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
- ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
- ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
- ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
- CREATE TABLE IF NOT EXISTS zipkin_dependencies (
- `day` DATE NOT NULL,
- `parent` VARCHAR(255) NOT NULL,
- `child` VARCHAR(255) NOT NULL,
- `call_count` BIGINT
- ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
- ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);

- 啟動時指定 mysql 信息
- java -DSTORAGE_TYPE=mysql -DMYSQL_HOST=127.0.0.1 -DMYSQL_TCP_PORT=3306 -DMYSQL_DB=zipkin -DMYSQL_USER=root -DMYSQL_PASS=root -jar zipkin-server-2.12.9-exec.jar
ElasticSearch
- 啟動 ES
- 啟動時指定 ES 信息
- java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=elasticsearch --ES-HOST=localhost:9200
END
到這里我們就完成了分布式系統中服務鏈路跟蹤的解決!那為我們解決了問題呢?
- 跨微服務的API調用發生異常,快速定位出問題出在哪里。
- 跨微服務的API調用發生性能瓶頸,迅速定位出性能瓶頸。





















