













修復配置單元(Hive)查詢的 5 個基本診斷視圖
譯文【51CTO.com快譯】關于現代數據分析員在分布式計算環境中的有效性,引起了人們很久的爭論。分析師習慣 SQL 在短時間內可以查詢到問題的答案。當查詢在幾個小時內沒有返回結果時,RDBMS 用戶通常會無法理解根本原因。
Hive 和 Spark 等查詢引擎對于高級工程師來說是很復雜的,但是有的并不這樣認為。在 Acceldata上,我們可以看到完整的表掃描在多 Tera Byte 表上運行從而獲取行數,這在 Hadoop中至少是不允許操作的。實際上,數據需要轉化為洞察力才能做出業務決策。值得一提的是,大數據的價值需要實時獲取。
Hadoop 管理員/工程師準備闡釋大量的度量指標,并分析性能不佳和從集群中拿走資源的原因,從而導致:
• 失控的資源問題
• 失控的時間問題
• 導致停機的泄漏
在開始糾正步驟之前必須提供以下詳細信息:
• 歷史查詢性能(查詢是重復的前提下)
• 執行視圖——Mappers(映射器)、Reducer(減速器)、連接效率
• 數據視圖 - 哪些表(事實維度)
• 紗線容器的效率
• 執行計劃——(邏輯和物理計劃)
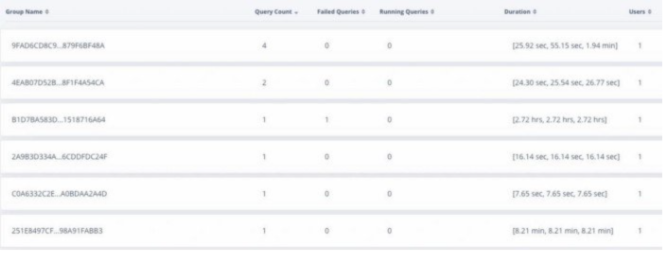
歷史查詢性能: Acceldata APM 對在交互式 BI 隊列上運行的每個 SQL 進行指紋識別。這是通過解析 AST 來完成的,并記住經常使用的查詢的參數進行不斷變化,例如,在每日報告的情況下。在下一次運行 SQL 時,Acceldata 能夠將該查詢的過去性能與最近的運行相關聯。查詢執行參數中的異常(如下所示)在視覺上表示異常:
• 經過的持續時間
• 從 HDFS 讀取數據
• 數據寫入 HDFS
• VCore的使用
• 內存利用率
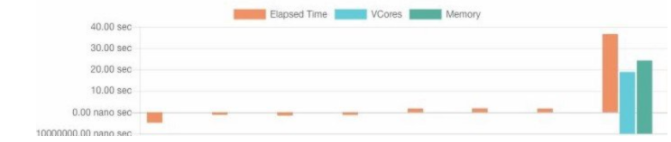
執行視圖: 在某些情況下,當一個Reducers需要花費很長時間時,查詢則需要很長的持續時間,就好像一個“掉隊者”,消耗超過 90% 的持續時間。這種識別有助于整改;然而,如果要實現這一點,不登錄多個服務器,并且沒跨層的橫截面視圖的幫助,是非常具有挑戰性的。Acceldata 結合紗線診斷日志,將Mappers和Reducers的持續時間、順序可視化。

以下是紗線診斷數據,顯示紗線應用程序從開始到結束的執行階段。這提供了一個清晰的概念,假如 Yarn 應用程序被搶占,那么內存和 VCore 的分配是什么,在這些應用程序中可以處理作業的容器的數量是多少。同時還提供了診斷消息,允許用戶在作業失敗的情況下識別異常,而無需離開UI。
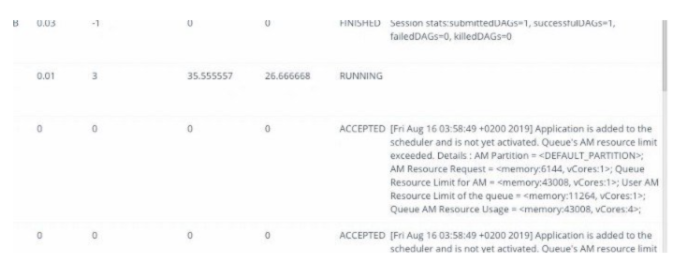
SQL 和數據視圖
Acceldata Query 360 的提供了 SQL、被查詢的表和正在運行的連接的視圖。除此之外,還有關于過濾條件的詳細信息、過濾謂詞是否準確,以及特定連接是否對查詢產生了不利影響,這是 SQL 診斷最重要的方面之一。
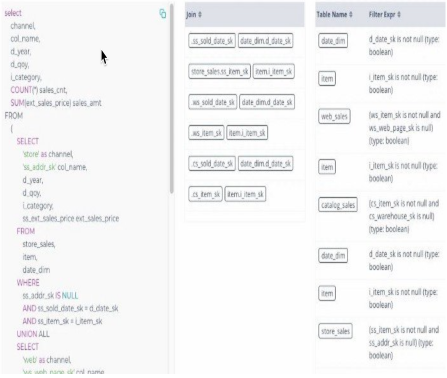
查詢計劃
對任何查詢的最終診斷都需要知曉查詢計劃。Acceldata 支持所有類型的 Hive和Map Reduce-Tez、MapReduce和LLAP的查詢計劃。這為管理員和數據工程師提供了一種簡單的方法來了解——TableScans ,操作行為是有意的還是偶然的,廣播連接在哪里發生,CBO 是否已啟動,是否為特定查詢設置了 PPD ,以及可以完成哪些連接優化。
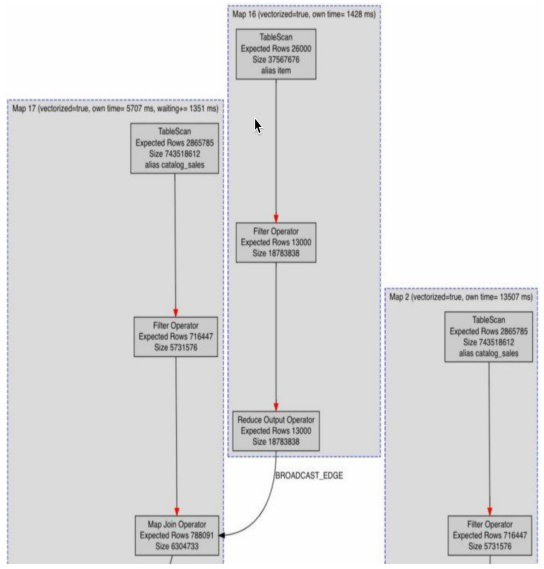
表
Hive 表的布局對查詢性能的影響是顯著的。在沒有數據壓縮或準確分區的情況下,很可能會對表進行端到端掃描,或者稱為 TableScan,因此Mappers器將花費更長的時間來完成,盡管有過濾謂詞。

但是,為了對分區策略做出明確的決定,需要了解表和列的使用組合。分析員運行的不是一個查詢,而是幾個查詢的組合,以確定哪個是理想的分區鍵,以及表是否可以靜態分區或動態分區。視圖如下所示:
結論
Hive 和 Spark 用戶和管理員很難獲得一個表示查詢/作業執行橫截面的視圖。在分布式計算領域,可見性仍然是一個挑戰,尤其是在 Hive 和 Spark 工作負載上。Acceldata 支持 360 度視圖以進行決策。通過以上部分,我們可以清楚地看到 管理員/工程師擁有所有可用于識別和糾正的信息:
• 相同查詢的當前運行和過去運行的歷史比較
• 執行查詢的時間
• 有問題的表及其連接
• Mapper 和 reducer 性能異常
• 物理文件系統上的數據布局,用于分區策略
• 查詢計劃可快速輕松地做出決策
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】












