













GPT-4參數(shù)將達(dá)10兆!此表格預(yù)測全新語言模型參數(shù)將是GPT-3的57倍
對于機器學(xué)習(xí)來說,參數(shù)可以算得上算法的關(guān)鍵:它們是歷史的輸入數(shù)據(jù),經(jīng)過模型訓(xùn)練得來的結(jié)果,是模型的一部分。
一般來說,在NLP領(lǐng)域,參數(shù)數(shù)量和復(fù)雜程度之間具有正相關(guān)性。而OpenAI的GPT-3則是迄今為止最大的語言模型之一,有1750億個參數(shù)。
那么,GPT-4會是什么樣子的?
近日有網(wǎng)友就對GTP-4及其「開源版」GPT-NeoX進(jìn)行了大膽的預(yù)測。
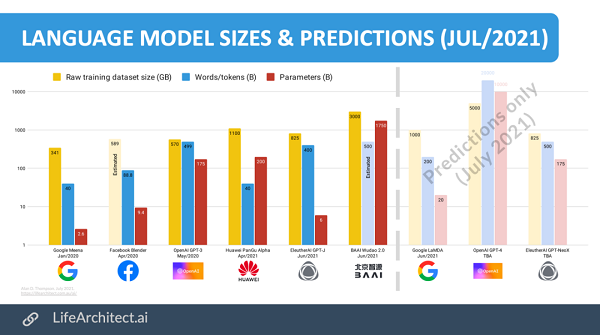
作者認(rèn)為,GPT-4的參數(shù)或許可以達(dá)到10T,是現(xiàn)在GPT-3模型的57倍還多,而GPT-NeoX的規(guī)模則可以和GPT-3持平。
等下,如果是這樣,程序員們還能不能在GPT-NeoX上愉快地調(diào)參了?
|
模型 |
發(fā)布時間 |
Tokens |
參數(shù) |
占1.75T的百分比 |
訓(xùn)練文本 |
|
GPT-2 (OpenAI) |
Feb 2019 |
10B |
1.5B |
0.09% |
40GB |
|
GPT-J (EleutherAI) |
Jun 2021 |
400B |
6B |
0.34% |
800GB |
|
GPT-3 (OpenAI) |
May 2020 |
499B |
175B |
10.00% |
570GB |
|
PanGu (Chinese) |
Apr 2021 |
40B |
200B |
11.43% |
1.1TB |
|
HyperCLOVA (Korean) |
May 2021 |
560B |
204B |
11.66% |
1TB? |
|
Wudao 2.0 (Chinese) |
Jun 2021 |
500B? |
1.75T |
100.00% |
2.4TB |
|
LaMDA (Google) |
Jun 2021 |
1T? |
200B? |
11.43% |
1TB? |
|
GPT-4 (OpenAI) |
TBA |
20T? |
10T? |
571.43% |
5TB? |
|
GPT-NeoX (EleutherAI) |
TBA |
500B? |
175B? |
10.00% |
825GB? |
數(shù)據(jù)集分析
目前應(yīng)用最廣的GPT-3的訓(xùn)練語料庫來自于規(guī)模巨大的結(jié)構(gòu)文本。其中所有數(shù)據(jù)集都被索引,分類,過濾和加權(quán),而且還針對重復(fù)的部分也做了大量的刪減。
專門為Openai開發(fā)并由Microsoft Azure托管的世界最強超算之一完成了對GPT-3的訓(xùn)練 。超算系統(tǒng)有超過285,000個CPU核心,超過10,000個 GPU,并且以400Gbps的速度運行。

GPT-3
Wikipedia DataSet是來自于Wikipedia的英文內(nèi)容。由于其質(zhì)量,寫作風(fēng)格和廣度,它是語言建模的高質(zhì)量文本的標(biāo)準(zhǔn)來源。
WebText數(shù)據(jù)集(以及擴展版本W(wǎng)ebText2)是來自從Reddit出站的大于4500萬個網(wǎng)頁的文本,其中相關(guān)的帖子會有兩個以上的支持率(upvotess)。
由于具有大于4.3億的月活用戶,因此數(shù)據(jù)集中的內(nèi)容可以被認(rèn)為是最 「流行 」網(wǎng)站的觀點。
Books1和Books2是兩個基于互聯(lián)網(wǎng)的書籍?dāng)?shù)據(jù)集。類似的數(shù)據(jù)集包括:
- BookCorpus,是由未發(fā)表的作者撰寫的免費小說書籍的集合,包含了至少10,000本書。
- Library Genesis (Libgen),一個非常大的科學(xué)論文、小說和非小說類書籍的集合。
Common Crawl是一個包含了超過50億份網(wǎng)頁元數(shù)據(jù)和提取文本的開源存檔開放的數(shù)據(jù)平臺:
- 八年來PB級的數(shù)據(jù)(數(shù)以千計的TB,數(shù)以百萬計的GB)。
- 25B個網(wǎng)站。
- 數(shù)以萬億計的鏈接。
- 75%英語,3%中文,2.5%西班牙語,2.5%德語等。
- 排名前10域名的內(nèi)容:Facebook、谷歌、Twitter、Youtube、Instagram、LinkedIn。
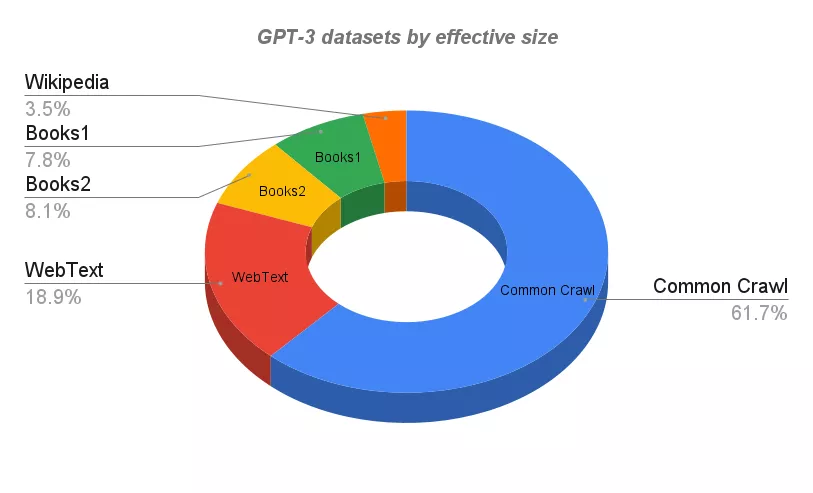
GPT-3使用的數(shù)據(jù)集
GPT-Neo和GPT-J
今年3月,Eleuther AI在GitHub上推出了GPT-Neo開源項目,可以在Colab上進(jìn)行微調(diào)。
雖然GPT-Neo與GPT-3比,參數(shù)量仍然很小(1.3B和2.7B),但開源又免費,仍然得到了「同性好友們」的認(rèn)可。
今年6月Eleuther AI再次推出GPT-J-6B,它可以說是GPT-Neo的增強版本,顧名思義,模型的參數(shù)量增加到了6B。
GPT-J的訓(xùn)練也是基于The Pile數(shù)據(jù)庫——一個825GB的多樣化開源語言建模數(shù)據(jù)集,由22個較小的、高質(zhì)量的數(shù)據(jù)集合組成。
The Pile除了專業(yè)論壇和知識庫,如HackerNews、Github和Stack Exchange,論文預(yù)印本網(wǎng)站ArXiv以外,還包括如Youtube字幕,甚至安然郵件(Enron Emails)語料庫。
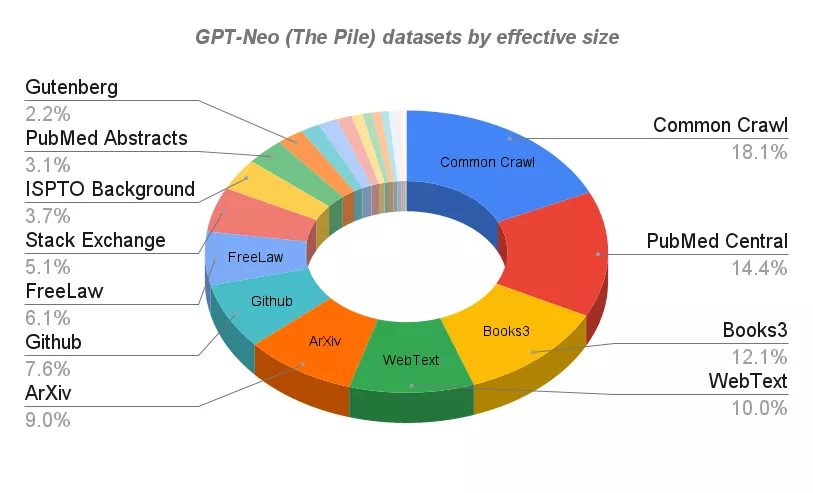
GPT-Neo和GPT-J使用的數(shù)據(jù)集
在zero-shot任務(wù)上,GPT-J性能和67億參數(shù)的GPT-3相當(dāng),也是目前公開可用的Transformer語言模型中,在各種下游zero-shot任務(wù)上表現(xiàn)最好的。
這么看來,確實可以期待一下和GPT-3相同規(guī)模的GPT-NeoX的表現(xiàn)了。
網(wǎng)友評論
GPT-4怎么這么大?
「GPT-3已經(jīng)接近理論上每個token的最大效率了。如果OpenAI模型的工作方式是正確的,更大的模型只是對算力的浪費。」

有網(wǎng)友解答說:「規(guī)模確實可以帶來改善。因為本質(zhì)上是一種關(guān)系隱喻模型,『了解更多的關(guān)系 』意味著能夠?qū)Ω嗟氖虑榛蛞愿?xì)微的方式做出反應(yīng)。當(dāng)然,這也同時是一個營銷的方式。」





























