參數(shù)量僅為4%,性能媲美GPT-3:開發(fā)者圖解DeepMind的RETRO

從 BERT 到 GPT-2 再到 GPT-3,大模型的規(guī)模是一路看漲,表現(xiàn)也越來越驚艷。增大模型規(guī)模已經(jīng)被證明是一條可行的改進路徑,而且 DeepMind 前段時間的一些研究表明:這條路還沒有走到頭,繼續(xù)增大模型依然有著可觀的收益。
但與此同時,我們也知道,增大模型可能并不是提升性能的唯一路徑,前段時間的幾個研究也證明了這一點。其中比較有代表性的研究要數(shù) DeepMind 的 RETRO Transformer 和 OpenAI 的 WebGPT。這兩項研究表明,如果我們用一種搜索 / 查詢信息的方式來增強模型,小一點的生成語言模型也能達到之前大模型才能達到的性能。
在大模型一統(tǒng)天下的今天,這類研究顯得非常難能可貴。
在這篇文章中,擅長機器學(xué)習(xí)可視化的知名博客作者 Jay Alammar 詳細分析了 DeepMind 的 RETRO(Retrieval-Enhanced TRansfOrmer)模型。該模型與 GPT-3 性能相當(dāng),但參數(shù)量僅為 GPT-3 的 4%。

RETRO 整合了從數(shù)據(jù)庫中檢索到的信息,將其參數(shù)從昂貴的事實和世界知識存儲中解放出來。
在 RETRO 之前,研究社區(qū)也有一些工作采用了類似的方法,因此本文并不是要解釋它的新穎性,而是該模型本身。
將語言信息和世界知識信息分離開來
一般來講,語言模型的任務(wù)就是做填空題,這項任務(wù)有時候需要與事實有關(guān)的信息,比如

但有時候,如果你對某種語言比較熟悉,你也可以直接猜出空白部分要填什么,例如:

這種區(qū)別非常重要,因為大型語言模型將它們所知道的一切都編碼到模型參數(shù)中。雖然這對于語言信息是有意義的,但是對于事實信息和世界知識信息是無效的。加入檢索方法之后,語言模型可以縮小很多。在文本生成過程中,神經(jīng)數(shù)據(jù)庫可以幫助模型檢索它需要的事實信息。
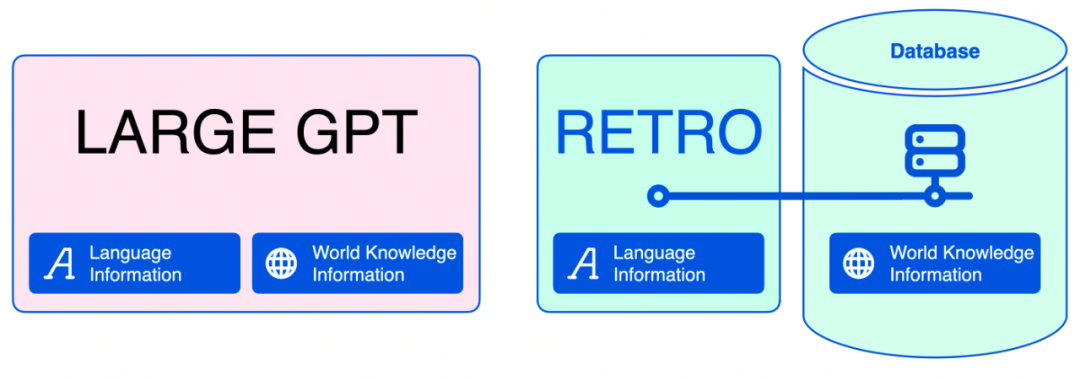
隨著訓(xùn)練數(shù)據(jù)記憶量的減少,我們可以使用較小的語言模型來加速訓(xùn)練。任何人都可以在更小、更便宜的 GPU 上部署這些模型,并根據(jù)需要對它們進行調(diào)整。
從結(jié)構(gòu)上看,RETRO 是一個編碼器 - 解碼器模型,就像原始的 Transformer。然而,它在檢索數(shù)據(jù)庫的幫助下增加了輸入序列。該模型在數(shù)據(jù)庫中找到最可能的序列,并將它們添加到輸入中。RETRO 利用它的魔力生成輸出預(yù)測。
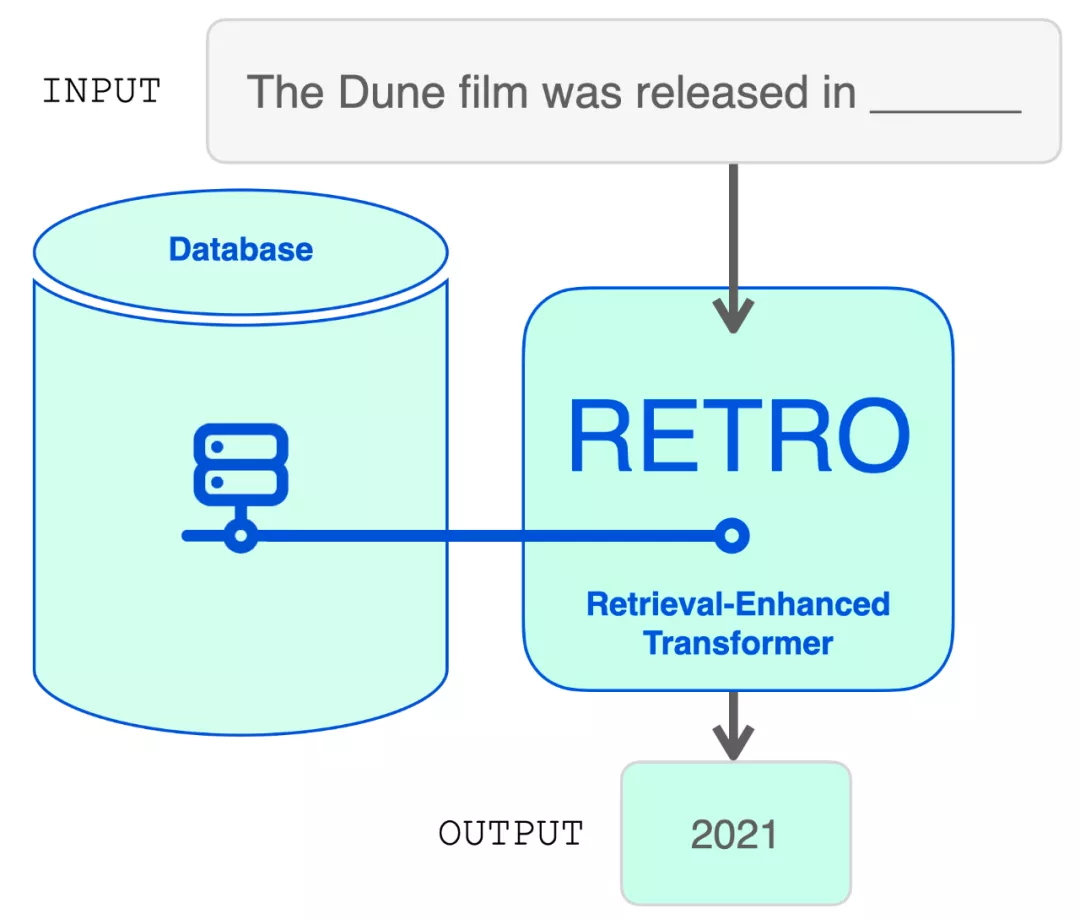
在探索模型架構(gòu)之前,讓我們先深入挖掘一下檢索數(shù)據(jù)庫。
RETRO 的檢索數(shù)據(jù)庫
此處的數(shù)據(jù)庫是一個鍵值存儲(key-value store)數(shù)據(jù)庫。其中 key 是標(biāo)準(zhǔn)的 BERT 句子嵌入,value 是由兩部分組成的文本:
- Neighbor,用于計算 key;
- Completion,原文件中文本的延續(xù)。
RETRO 的數(shù)據(jù)庫包含基于 MassiveText 數(shù)據(jù)集的 2 萬億個多語言 token。neighbor chunk 和 completion chunk 的長度最多為 64 個 token。

RETRO 數(shù)據(jù)庫內(nèi)部展示了 RETRO 數(shù)據(jù)庫中鍵值對的示例。
RETRO 將輸入提示分成多個 chunk。為簡單起見,此處重點關(guān)注如何用檢索到的文本擴充一個 chunk。但是,模型會針對輸入提示中的每個 chunk(第一個 chunk 除外)執(zhí)行此過程。
數(shù)據(jù)庫查找
在點擊 RETRO 之前,輸入提示進入 BERT。對輸出的上下文向量進行平均以構(gòu)建句子嵌入向量。然后使用該向量查詢數(shù)據(jù)庫。
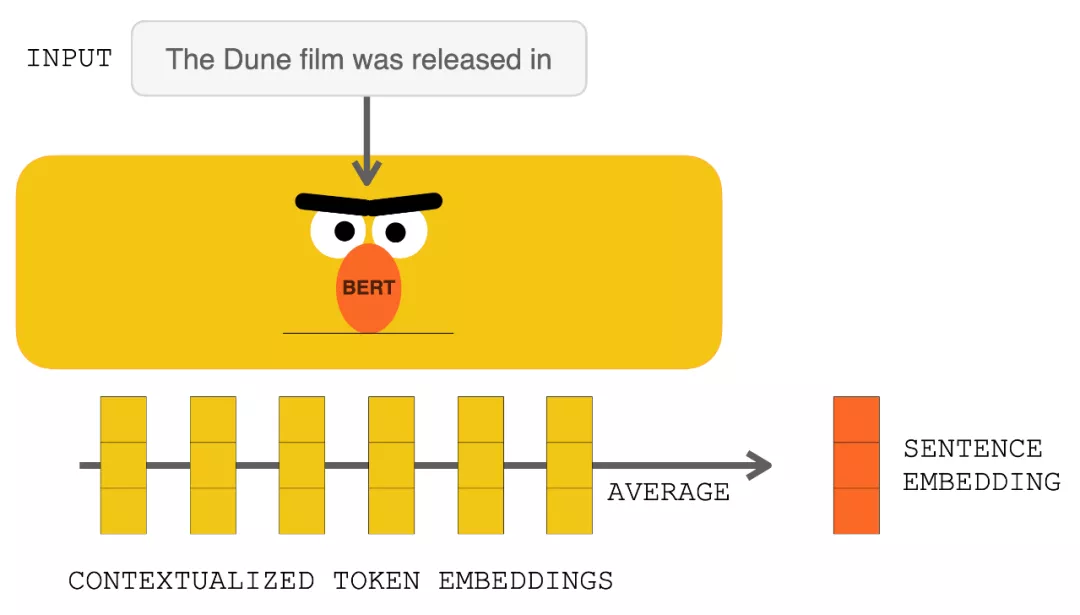
使用 BERT 處理輸入提示會生成上下文化的 token 嵌入 。對它們求平均值會產(chǎn)生一個句子嵌入。
然后將該句子嵌入用于近似最近鄰搜索。檢索兩個最近鄰,它們的文本成為 RETRO 輸入的一部分。
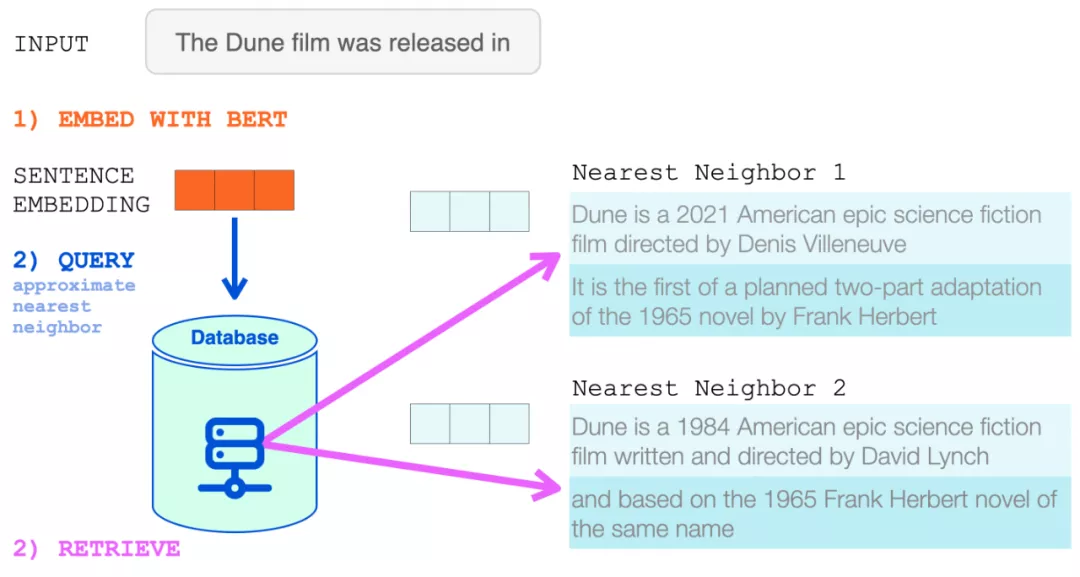
BERT 句子嵌入用于從 RETRO 的神經(jīng)數(shù)據(jù)庫中檢索最近鄰。然后將這些添加到語言模型的輸入中。
現(xiàn)在 RETRO 的輸入是:輸入提示及其來自數(shù)據(jù)庫的兩個最近鄰(及其延續(xù))。
從這里開始,Transformer 和 RETRO 塊將信息合并到它們的處理中。
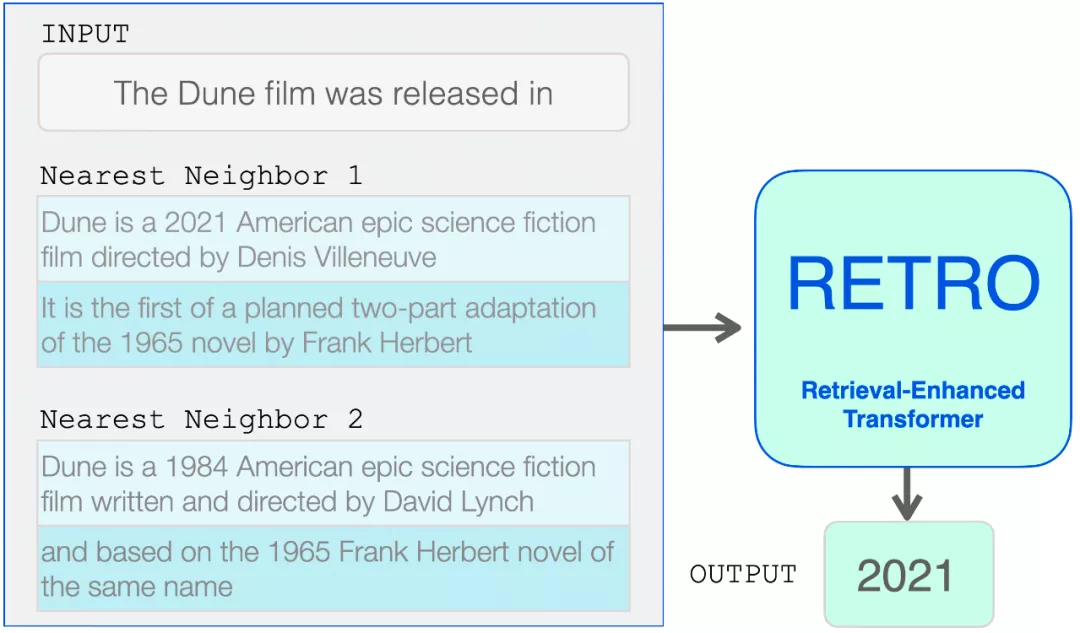
檢索到的近鄰被添加到語言模型的輸入中。然而,它們在模型內(nèi)部的處理方式略有不同。
高層次的 RETRO 架構(gòu)
RETRO 的架構(gòu)由一個編碼器堆棧和一個解碼器堆棧組成。
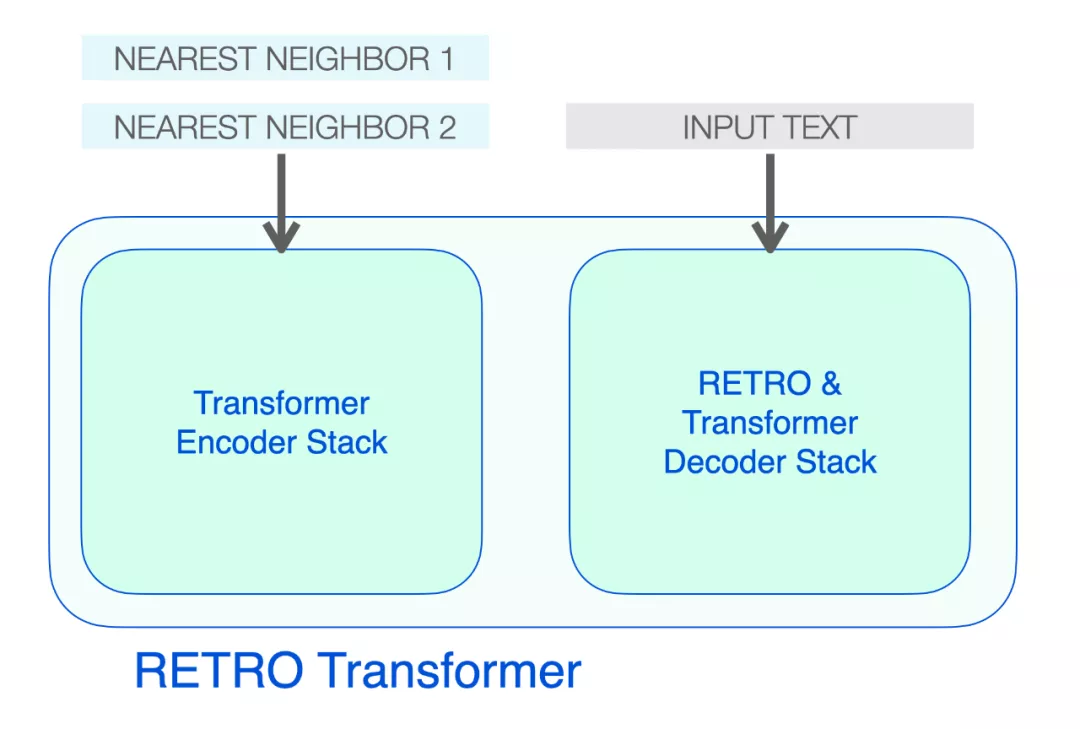
RETRO Transformer 由一個編碼器堆棧(處理近鄰)和一個解碼器堆棧(處理輸入)組成
編碼器由標(biāo)準(zhǔn)的 Transformer 編碼器塊(self-attention + FFNN)組成。Retro 使用由兩個 Transformer 編碼器塊組成的編碼器。
解碼器堆棧包含了兩種解碼器 block:
- 標(biāo)準(zhǔn) Transformer 解碼器塊(ATTN + FFNN)
- RETRO 解碼器塊(ATTN + Chunked cross attention (CCA) + FFNN)
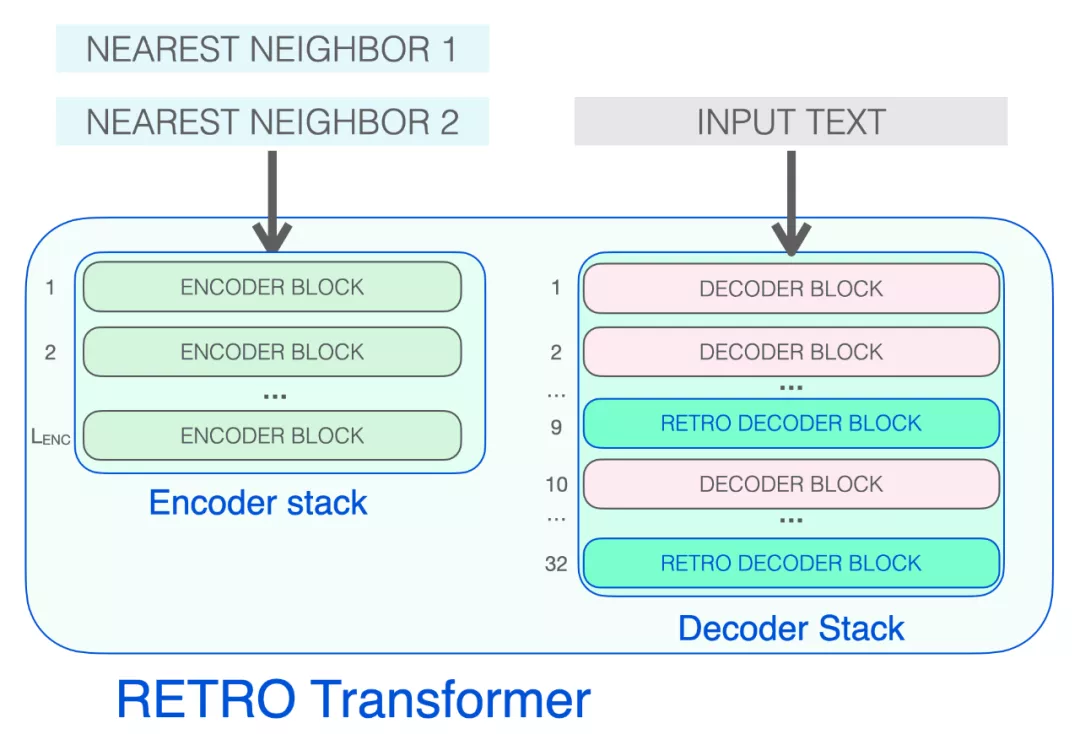
構(gòu)成 RETRO 的三種 Transformer 模塊
編碼器堆棧會處理檢索到的近鄰,生成后續(xù)將用于注意力的 KEYS 和 VALUES 矩陣。
解碼器 block 像 GPT 一樣處理輸入文本。它對提示 token 應(yīng)用自注意力(因此只關(guān)注之前的 token),然后通過 FFNN 層。
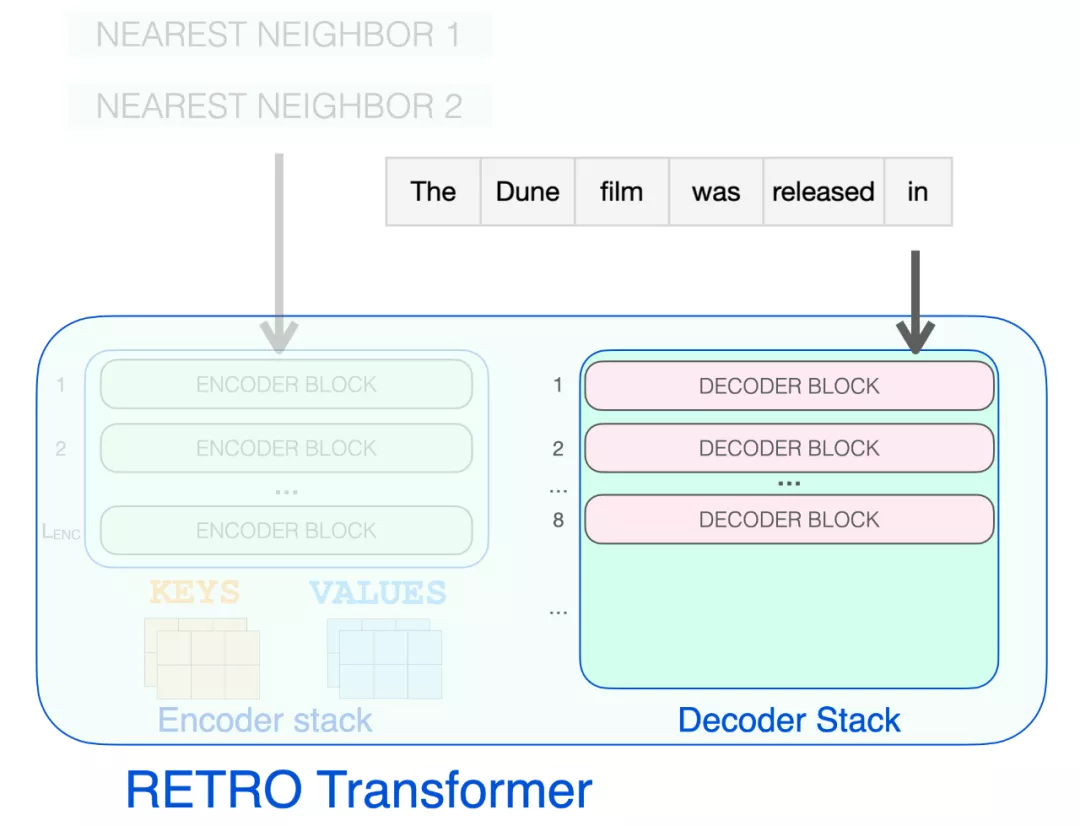
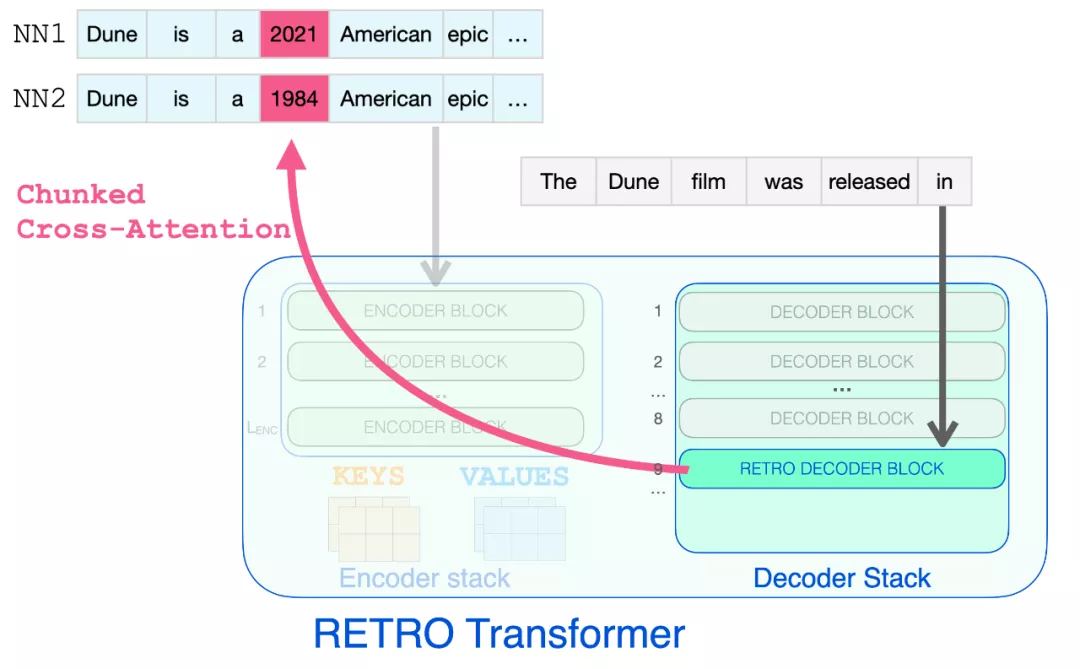
只有到達 RETRO 解碼器時,它才開始合并檢索到的信息。從 9 開始的每個第三個 block 是一個 RETRO block(允許其輸入關(guān)注近鄰)。所以第 9、12、15…32 層是 RETRO block。
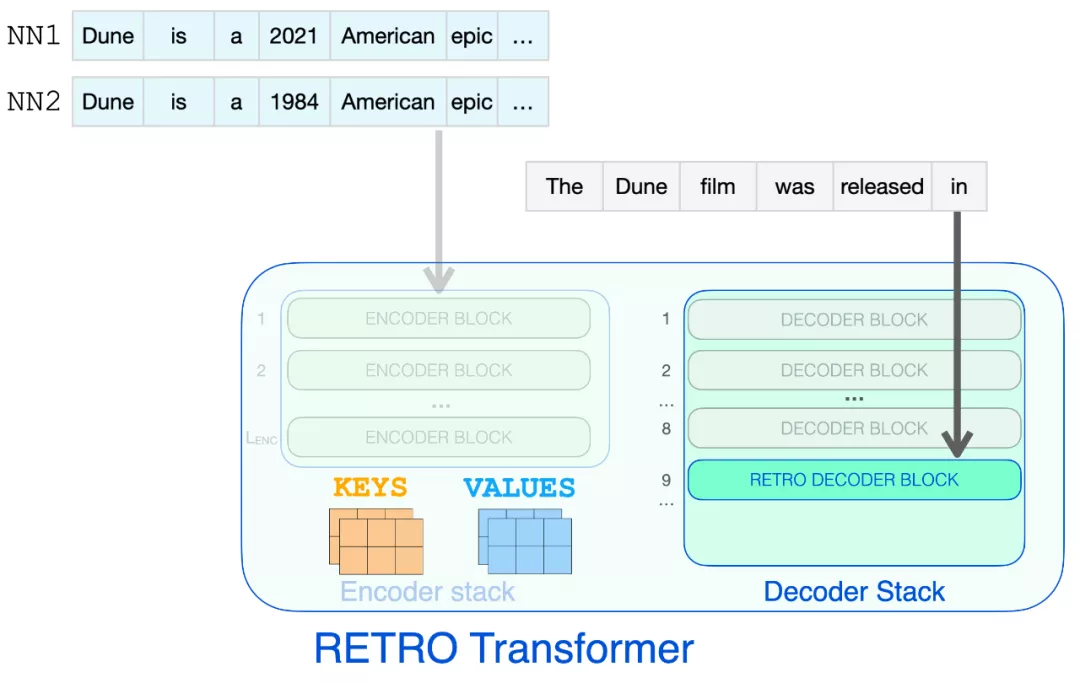
下圖展示了檢索到的信息可以瀏覽完成提示所需的節(jié)點步驟。