基于CRDT的數據最終一致性
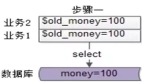
對于分布式系統的架構師來說,CAP 定理所描述的一致性和可用性是一個較大的挑戰。網絡遠程跨機房是不可避免的,數據中心之間的高延遲總是導致數據中心之間在短時間內出現某種斷開。因此,傳統的分布式應用體系結構被設計成要么放棄數據一致性,要么降低可用性。
不幸的是,我們不能犧牲應用可用性。嘗試保持一致性,業界接受了最終一致性模型。在這個模型中,應用依賴于數據庫管理系統來合并數據的所有本地副本,以使它們最終保持一致。除非出現數據沖突,最終一致性模型看起來很好。一些最終一致性模型承諾盡最大努力解決沖突,但不能保證強一致性。
1. 什么是CRDT?
一個新趨勢是,圍繞CRDT構建的模型提供了強最終一致性。那么,什么是CRDT 呢?
CRDT是無沖突復制數據類型的縮寫。CRDT通過預先確定的一套解決沖突規則和語義來實現了最終一致性,它引入一組特殊的基礎數據類型, CRDT是一種特殊的數據類型,可以從所有數據庫副本匯聚數據。常用的 CRDTs包括 G-counters (grow-only counters)、 PN-counters (positive-negative counters)、寄存器、 G-sets (grow-only sets)、2P-sets (two-phase sets)、 or- sets (observed-remove sets)等等。
在背后,CRDT依靠以下數學特性來處理數據:
- 交換律:a ☆ b = b ☆ a
- 結合律:a ☆ ( b ☆ c ) = ( a ☆ b ) ☆ c
- 等冪: a ☆ a = a
G 計數器是一個完美的例子,操作 CRDT合并的業務。這里,a + b = b + a 和 a + (b + c) = (a + b) + c。副本之間只交換更新(增加的內容)。CRDT 通過添加更新來合并更新。例如,g 集合應用冪等({ a,b,c } u { c } = { a,b,c })來合并所有元素。冪等可以避免在元素通過不同路徑傳遞和匯聚時重復添加到數據結構中的元素。
一個典型的多主系統的副本同步方式如下:
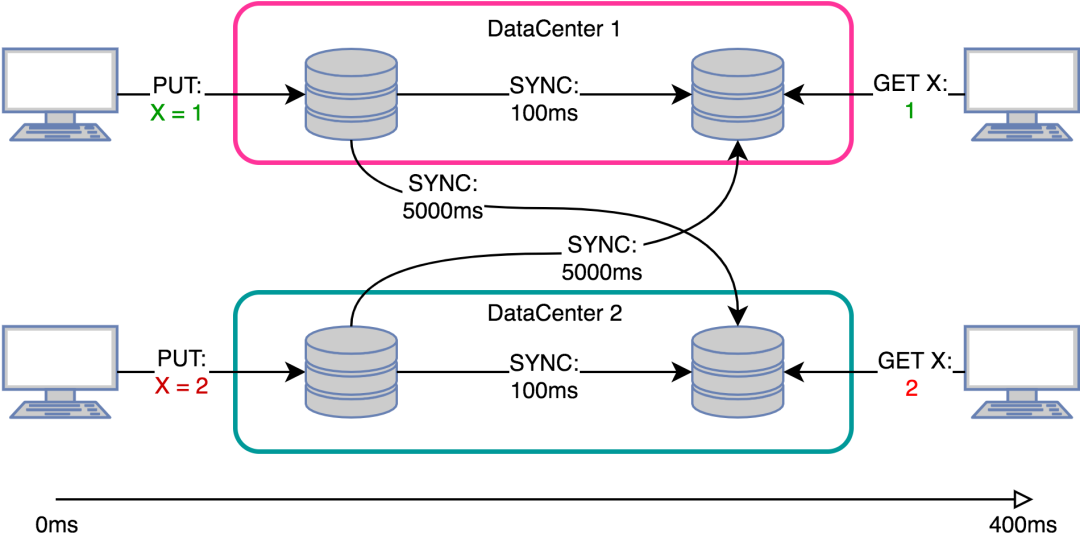
CRDT能夠自己解決合并沖突,更一般的情況是處理在多leader分布式系統中的副本同步。
那么, 有哪些典型的副本同步模式呢?
2. 副本同步模式
2.1 基于狀態的同步
基于狀態的同步, 也稱為被動同步,形式為聚合復制數據類型(Convergent Replicated Data Type,CvRDT), 用于 NFS、 AFS、 Coda 等文件系統,以及 Riak、 Dynamo 等 KV存儲。
在這種情況下,副本通過發送對象的完整狀態來傳播更改,必須定義 merge ()函數,以將傳入的更改與當前狀態合并。

基于狀態的同步必須滿足以下要求,以確保復制的一致性:
- 數據類型(或復制上的狀態)形成一個具有最小上界的偏序集
- Merge ()函數產生一個最小上界
- 副本構成一個連通圖
例子:
數據類型: 自然數集是N,極小元到正負無窮大,則Merge (x,y) = max (x,y)
這樣的要求給出了一個用于交換的冪等merge()函數,它也是給定數據類型上的一個單調遞增函數。
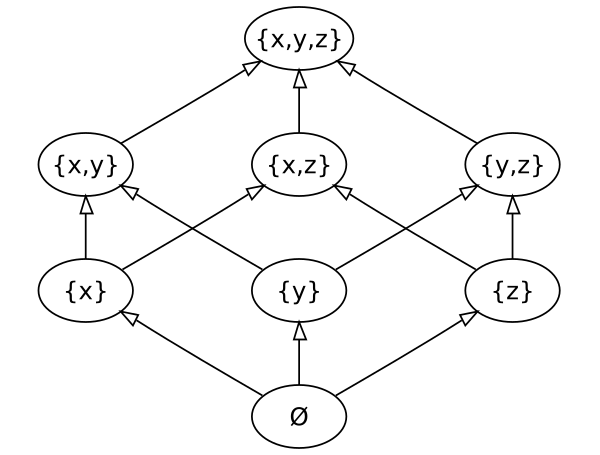
這保證了所有的副本最終都會聚合收斂,并且讓我們不用擔心傳輸協議ーー可以丟失傳播更新,也可以多次發送它們,甚至可以按任何順序發送它們。
2.2 基于操作的同步
基于操作的同步,也稱為主動同步,形式為交換復制數據類型(Commutative Replicated Data Type ,CmRDT),用于 Bayou, Rover, IceCube, Telex這樣的系統。
在這種情況下,副本通過向所有副本發送操作來傳播更改。當對副本進行更改時:
執行 generate ()方法,該方法返回一個要在其他副本上調用的 effector ()函數。換句話說,effector ()是一個用于修改其他副本狀態的閉包。
將effector ()應用于本地狀態
向所有其他副本傳播effector ()
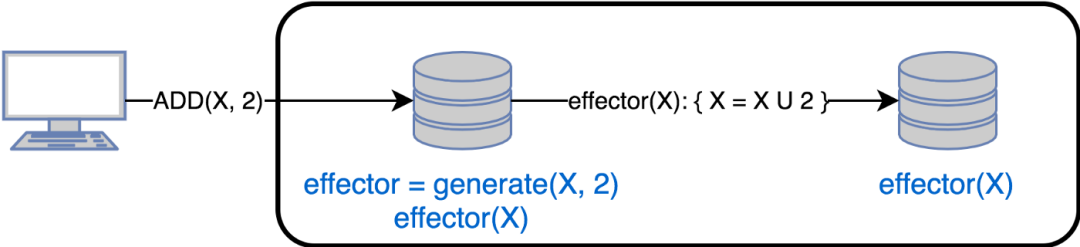
基于操作的同步必須滿足以下要求,以確保復制的一致性:
- 可靠的傳輸協議
- 如果effector()以因果順序交付,那么并發 effector ()就必須轉換為OR
- 如果effector()在沒有遵守因果順序的情況下交付,那么所有effector()都必須轉換
- 如果能夠多次傳遞,則 effector ()必須是冪等的.
- 在現實中,一般會依賴于可靠的發布-訂閱系統(例如,Kafka)作為交付的一部分。
2.3 基于增量的同步
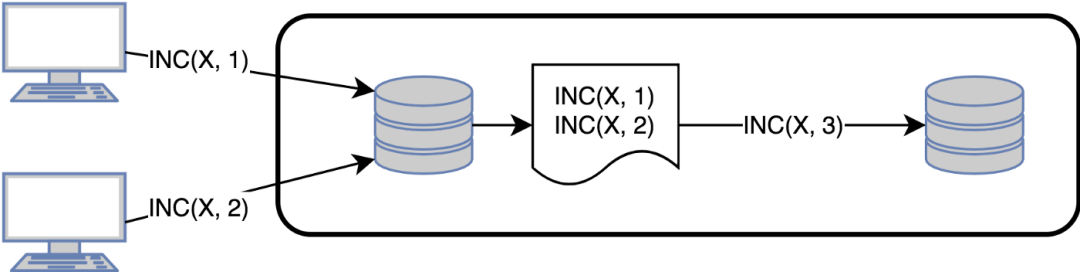
考慮到基于狀態/操作的同步,如果一個更改只影響對象的一部分,那么傳輸整個對象的狀態是沒有意義的。此外,如果更新修改了相同的狀態(如計數器) ,我們可以周期性地只發送一個聚合狀態。
增量同步結合了狀態和操作這兩種方法,并傳播所謂的 Delta 變異,這些變異相應地將狀態更新到最后的同步日期。所以,需要發送一個完整的狀態進行第一次同步,然而,一些實現實際上考慮了遠程副本的狀態以降低所需的數據量。
如果允許延遲,那么基于操作的日志壓縮可能是下一個優化:
2.4 基于純操作的同步
在基于操作的同步中有一個延遲,以創建一個effector()。在某些系統中,這樣的延遲是不可接受的,必須立即傳播更新,需要更復雜的組織協議以及更多的元數據空間。
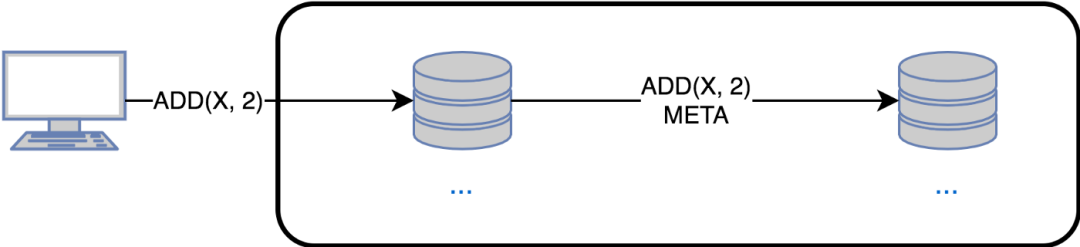
典型用法:
- 如果在系統中必須立即傳播更新,基于狀態的同步是一個糟糕的選擇,因為它會增加整個狀態的成本。然而,在這種特殊情況下,基于增量的同步是更好的選擇,與基于狀態更新的差別不會太大。
- 如果你需要在失敗后同步副本,基于狀態/基于 delta 是正確的選擇。如果必須使用基于操作的同步,則必須:
- 回復所有失敗后遺漏的更改
- 獲取其中一個副本的完整副本并應用于所有錯過的操作
3.基于操作的同步只需要將 effector ()傳遞給每個副本一次。通過要求effector ()具有冪等性,可以放松這一要求。實際上,前者比后者更容易實現。
基于操作和基于狀態的同步之間的關系是:基于操作和基于狀態的同步可以在保持 CRDT 要求的前提下相互仿真。
3. 數據一致性模型
一致性模型數據協議是分布式數據庫和應用程序之間的一個協議,它定義了在寫操作和讀操作之間數據的清潔程度。
例如,在一個強一致性模型中,數據庫保證應用程序總是讀取最后一次寫入的數據。使用循序一致性數據庫的時候,數據庫保證你讀取的數據的順序與數據寫入數據庫的順序一致。在最終一致性模型中,分布式數據庫承諾在幕后同步和整合數據庫副本之間的數據。因此,如果將數據寫入一個數據庫副本并從另一個數據庫副本讀取數據,則可能不會讀取數據的最新副本。
關于最終一致性的研究已經有了許多的研究成果。當前的趨勢是從強一致性轉向其他可能的一致性變化,研究什么樣的數據一致性模型最適合特定的系統/場景,并需要重新考慮當前的定義。這就導致了一些矛盾,例如,當一些人考慮一個具有特殊屬性的最終一致性時,同時,其他作者已經為這個特殊情況創建了一個定義。
簡單地,可以從效果來重新定義最終一致性,即如果所有請求都沒問題,那么它最終是一致的。
3.1 數據一致性的分類
強一致性(SC)
所有的寫操作都嚴格按順序執行,對任何副本的讀請求都返回相同的、最后的寫結果,需要實時的共識(及其所有后果) 。為了解決沖突,允許 n/2-1節點關閉。
最終一致性(EC)
在本地進行更新,然后傳播更新。讀取一些副本可能會返回過時的狀態。回滾或以某種方式決定在發生沖突時應該做什么。也就是說,我們還需要共識,不是實時的。
強最終一致性(SEC)
EC + 復制有一個自動解決沖突的方法。因此,我們不要求達成共識,允許關閉 n-1節點。
如果放松 CAP 定理中的 SC 要求,那么 SEC 就解決了那些惱人的問題。
3.2 強一致性
兩階段提交是實現強一致性的常用技術。這里,對于本地數據庫節點上的每個寫操作(添加、更新、刪除) ,數據庫節點將更改傳播到所有數據庫節點,并等待所有節點確認。然后,本地節點向所有節點發送一個提交,并等待另一個確認。應用程序只能在第二次提交之后才能讀取數據。當網絡斷開數據庫之間的連接時,分布式數據庫將不能進行寫操作。
3.3 最終一致性的實現方法
最終一致性模型的主要優點是,即使在分布式數據庫副本之間的網絡連接中斷的情況下,數據庫也可以執行寫操作。一般來說,這個模型避免了兩階段提交產生的往返時間,因此支持的每秒寫操作比其他模型多得多。最終一致性必須解決的一個問題是沖突,即在不同的地方同時寫同一個條目。根據如何避免或解決沖突,最終一致性可以進一步分為以下幾類:
最后寫入的最終一致性(Last writer wins ,LWW)
在這種策略中,分布式數據庫依賴于服務器之間的時間戳同步。數據庫交換每個寫操作的時間戳和數據本身。如果發生沖突,使用最新時間戳的寫操作獲勝。
這種技術的缺點是假設所有系統時鐘都是同步的。實際上,同步所有的系統時鐘是困難和昂貴的。
法定人數的最終一致性(Quorum-based eventual consistency)
此技術類似于兩階段提交。然而,本地數據庫并不等待所有數據庫的確認; 它只是等待大多數數據庫的確認。多數人的確認確定了法定人數。如果發生沖突,建立仲裁的“寫”操作獲勝。
另一方面,這種技術增加了寫操作的網絡延遲,從而降低了應用程序的可伸縮性。此外,如果本地數據庫與拓撲中的其他數據庫副本隔離,那么它將不能進行寫操作。
合并復制(Merge replication)
在這種關系數據庫中常見的傳統方法中,一個集中的合并代理將所有數據合并。這種方法還提供了一些靈活性,可以實現自己解決沖突的規則。
合并復制速度太慢,無法支持實時使用的應用程序,還存在一個單點故障。由于此方法不支持沖突解決的預設規則,因此常常導致沖突解決的錯誤實現。
無沖突復制數據類型(Conflict-free replicated data type,CRDT)
簡而言之,基于 CRDT的數據庫提供無沖突的最終一致性。基于 CRDT的數據庫是可用的,即使分布式數據庫副本不能交換數據。它們總是將本地延遲交付給讀寫操作。
因此,我們希望為不穩定且經常分區的分布式系統提供一組基礎數據類型。此外,希望這些數據類型為我們解決沖突,這樣就不需要與用戶交互或查詢仲裁節點。
然而,并非所有數據庫用例都受益于CRDT,而且,基于 CRDT數據庫的沖突解決語義是預定義的,不能被重寫。
4. CRDT 分析
4.1 CRDT 之 Counter
一個帶有兩個操作的整數值: inc ()和 dec (),讓我們考慮一些基于操作和狀態同步的實現:
4.1.1 基于操作的計數器
很明顯,我們只需要傳播更新。
例如,Inc () : generator (){ return function (counter){ counter + = 1}}。
4.1.2 基于狀態的計數器
這是一個棘手的問題,因為我們還不清楚如何實現 merge ()函數。
增量計數器,g 計數器:
讓我們使用一個具有副本數量大小的向量(又叫版本向量) ,每個副本在 inc ()操作中增加它的向量元素。Merge ()函數取相應向量項的最大值,即計數器值中所有向量元素的和。

此外,G-Set 也可以使用。
例如,社交媒體中點擊/喜歡 的計數器。
加減計數器
使用兩個 g 計數器,一個用于增量,另一個用于減量。
例如,P2P網絡(Skype)中登錄的用戶數量。
非負數計數器:
不幸的是,到目前為止還沒有一個現實中的應用。
4.2 CRDT之 Register
具有兩個操作的存儲單元:assign()和value()。問題在于assign()操作,它們不進行交換。有兩種方法可以解決這個問題:
4.2.1 LWW-Register
通過在每個操作上生成惟一的 id (時間戳)來引入總順序。
例如,基于狀態的,通過元組(value,id)的更新:

現實中,cassandra 中的列和 NFS中整個文件或其中的一部分都是具體的應用場景。
4.2.2 Multi-Value Register
該方法類似于每個節點的 G-Counter+ store 的集合。Multi-Value Register的值是所有值,merge ()函數對所有向量元素應用 LWW 方法。
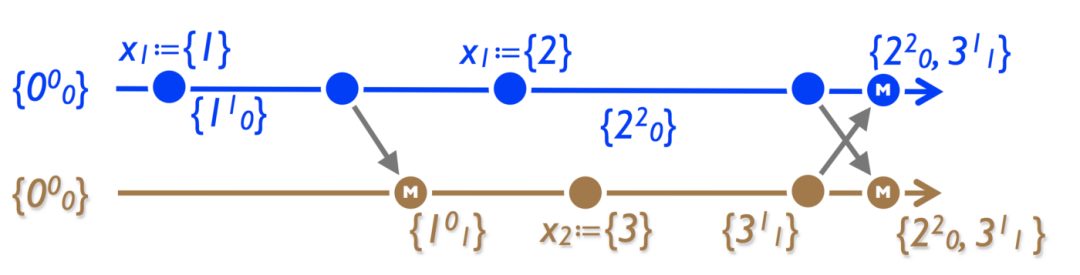
例如,網上商城中的購物籃。
4.3 CRDT之 Set
一個集合有兩個非交換操作: add ()和 rmv () ,它是容器、映射、圖等的基礎類型。
考慮一個原生的集合實現,其中 add ()和 rmv ()在到達時順序執行。首先,在第1和第2個副本上有并發的 add () ,然后 rmv ()在第1個副本上到達。
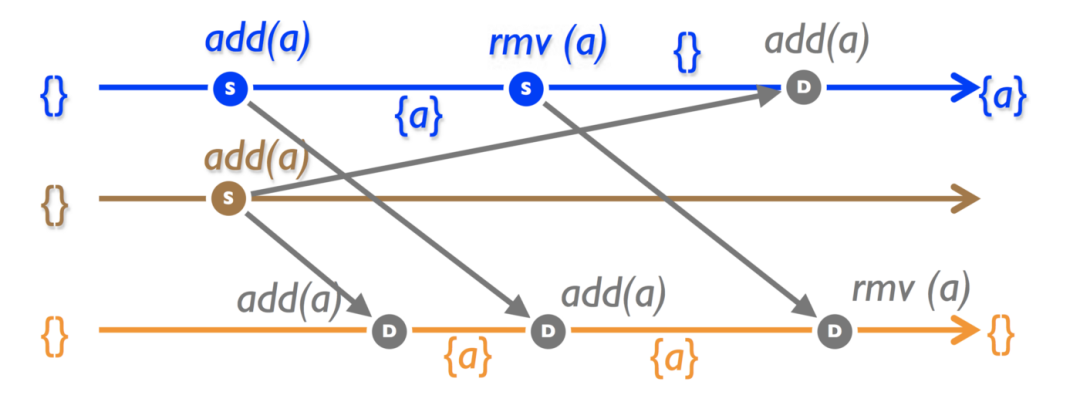
果然,在同步之后副本發生了偏移。
4.3.1 Grow-Only Set
一個非常簡單的解決方案是根本不允許 rmv ()操作。Add ()操作轉換,merge ()函數只是一個集合。
4.3.2 2P-Set
允許 rmv ()操作,但不能在刪除元素后重新添加元素。一個附加的 g-set可以用來跟蹤刪除的元素(也稱為墓碑集)。
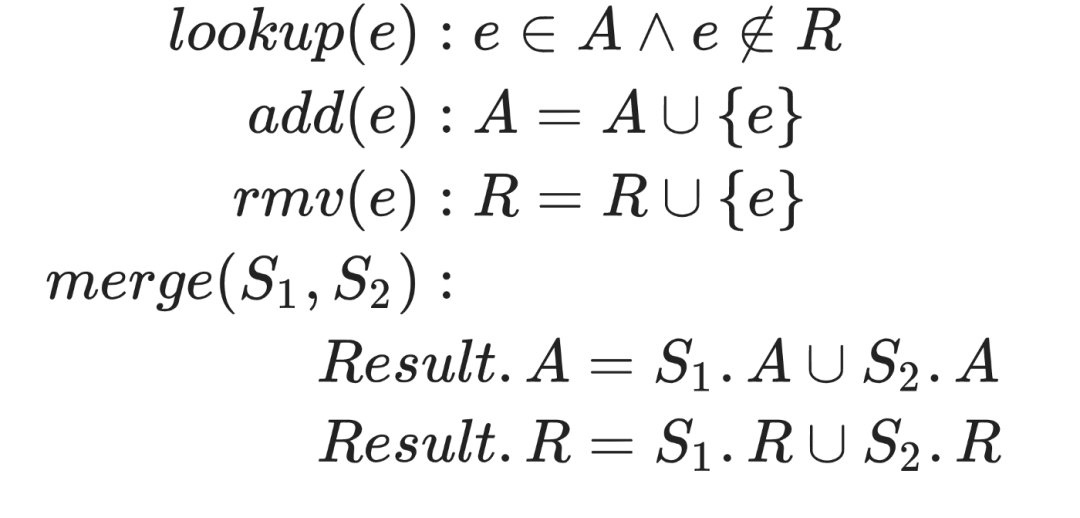
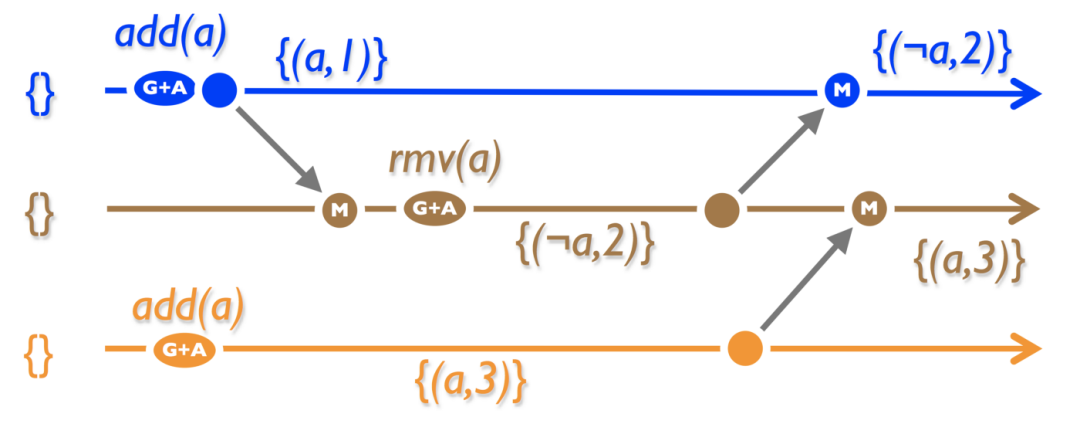
4.3.3 LWW-element Set
思路是在一個集合中引入一個總順序。例如,生成時間戳。我們需要兩個集合: 添加集和刪除集。Add ()將(element,unique _ id ())添加到 add-set,rmv ()將添加到 remove-set。Lookup ()檢查 id 在 add-set 或 rmv-set 中的大小。
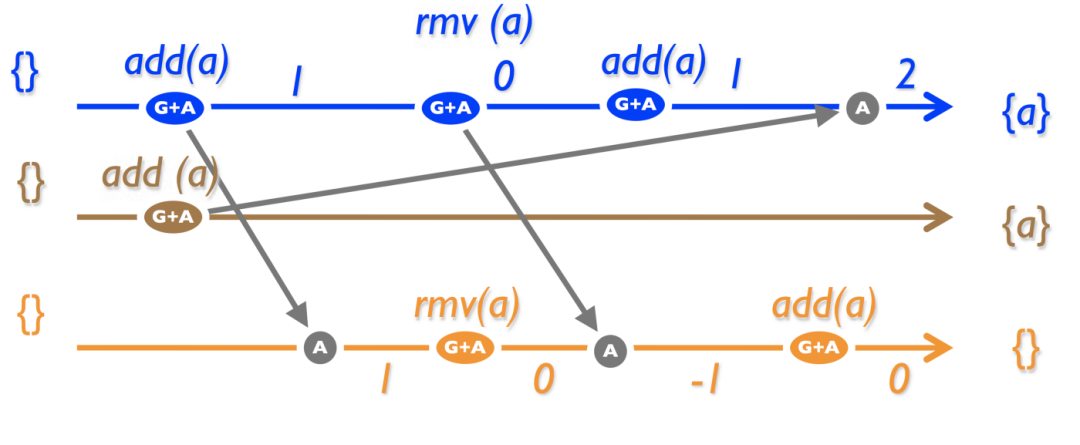
4.3.4 PN-Set
對集合進行排序的另一種方法ーー為每個元素添加一個計數器。在 add ()操作上增加它,在 rmv ()上減少它。當且僅當其計數器為正時,集合中要考慮相應的元素。
4.3.5 Observe-Remove Set, OR-Set, Add-Win Set:
在此數據類型中,add ()優先于 rmv ()。可能實現的一個例子是: 向每個新添加的元素添加唯一的標記(每個元素)。然后 rmv ()將元素的所有可見標記發送給其他副本,副本保留其他標記。
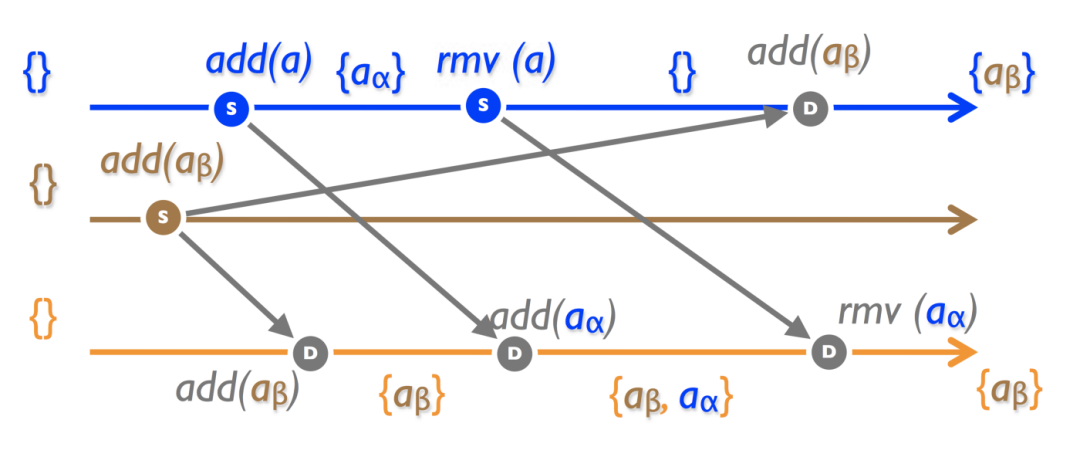
4.3.6 Remove-win Set
同上,但是 rmv ()優先于 add ().
4.4 CRDT之Graph
圖類型基于集合類型。這里有以下問題: 如果有兩個并發 addEdge (u,v)和 removeVertex (u)操作ー我們應該怎么做?有三種可能的策略:
- removeVertex ()具有優先級,所有關聯的邊都將被刪除
- addEdge ()具有優先級,所有移除的頂點將被重新添加
- 延遲 removeVertex ()的執行,直到所有并發 removeVertex ()都執行為止
第一個是最容易實現的,因為可以只使用兩個2p 集,得到的數據類型稱為2p2p 圖.
4.5 CRDT之 Map
對于map,有兩個問題需要解決:
- 如何處理并發 put ()操作? 可以類比計數器,使用 LWW 或 MV 語義嗎?
- 如何處理并發的 put ()/rmv ()操作?我們可以通過類比設置和使用 put-wins 或 rmv-wins 或 last-put-wins 語義么?
Map允許嵌套其他 CRDT 類型。需要注意的是,Map不處理其值的并發更改,必須由嵌套的 CRDT 本身來處理。
4.5.1 Remove-as-recursive-reset map
在此數據類型中,rmv (k)操作“重置”給定 k 下 CRDT 對象的值,例如,對于值為零的計數器。
例如,一個共享的購物車。一個用戶添加更多的面粉,另一個同時做一個檢查(這導致刪除所有元素)。同步之后,有一個“單元”的面粉,這似乎是合理的。
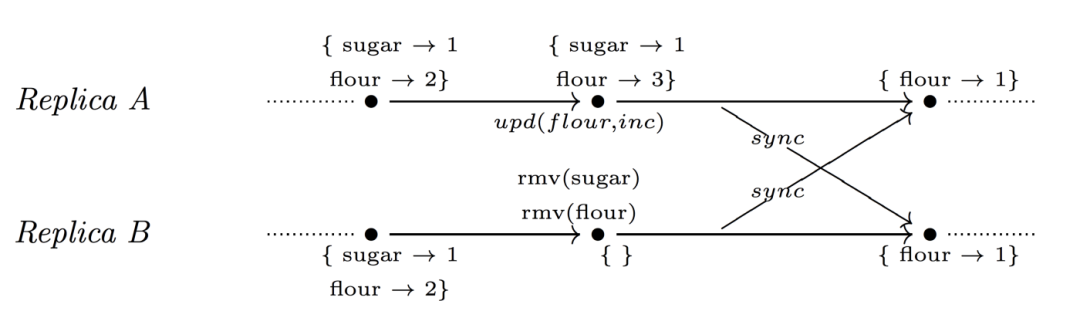
4.5.2 Remove-wins map
在這種情況下,rmv ()優先于 add ()。
例如,玩家張三在一個網絡游戲中有10個硬幣和一個錘子。接下來發生了兩個并發操作: 在副本 a 上她發現了一個釘子,在副本 b 上 Alice 被刪除(刪除所有項目)。

4.5.3 Update-wins map
Add ()優先于 rmv () ,更準確地說,add ()取消了以前所有的并發 rmv ()。
例如,玩家李四在一個在線游戲中在副本 a 上被刪除,同時她在副本 b 上做了一些活動。很明顯,rmv ()操作必須被取消。
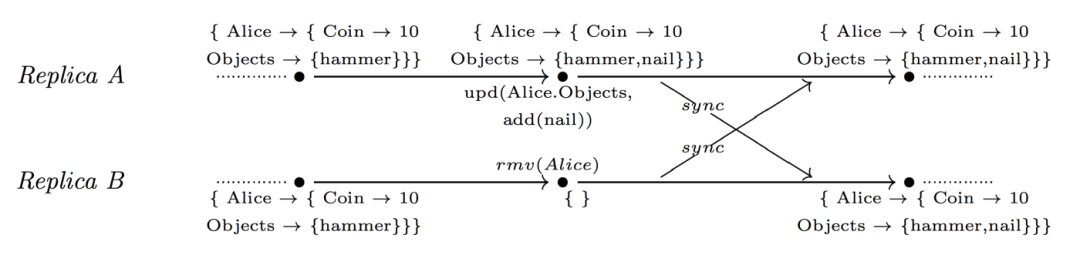
需要注意的是, 假設我們有兩個副本 a 和 b,它們以 k 為單位存儲一組復制品。如果 a 刪除了密鑰 k,b 刪除了集合中的所有元素,那么最終,兩個副本的密鑰 k 下都會有一個空集。
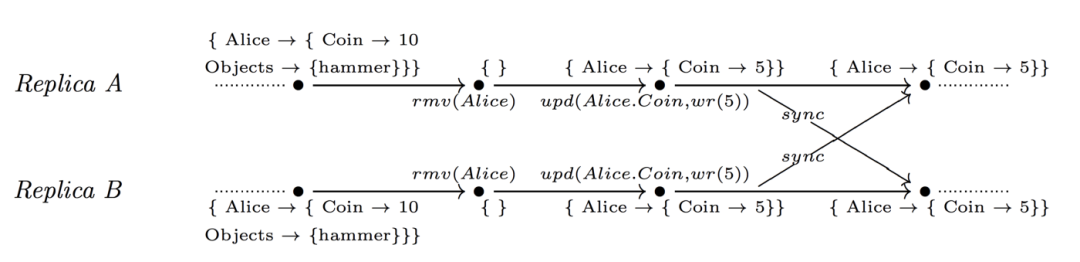
然而,有時不能取消以前所有的 rmv ()操作。考慮下面的例子,如果用這種方法,同步狀態將與初始狀態相同,這是一個不正確的結果。
4.6 CRDT之List
這種類型的問題在于,在本地更新操作之后,不同的副本上的元素索引將會不同。為了解決這個問題,可以使用操作轉換索引的方法,在應用接收到的更新操作時,必須考慮原始索引。
5 構建基于CRDT的應用
將應用程序連接到基于CRDT的數據庫與將應用程序連接到任何其他數據庫沒有什么不同。然而,由于最終一致性的策略,應用程序需要遵循一定的規則來提供一致的用戶體驗,其中的三個關鍵點是:
1. 應用程序無狀態
無狀態應用程序通常是 api 驅動的。對 API 的每次調用都會導致從頭重新構建完整的消息。這可以確保在任何時候獲得一個干凈的數據副本。基于CRDT的數據庫提供的低本地延遲使得重構消息更快更容易 。
2. 選擇適合場景的正確 CRDT
計數器是 crt 中最簡單的。它可以應用于諸如全局投票、跟蹤活動會話、計量等用例。但是,如果要合并分布式對象的狀態,那么還必須考慮其他數據結構。例如,對于允許用戶編輯共享文檔的應用程序,您可能不僅希望保留編輯,還希望保留執行編輯的順序。在這種情況下,將編輯保存在基于 crdt 的列表或隊列數據結構中將是比將編輯保存在寄存器中更好的解決方案。了解由 crt 強制執行的沖突解決語義,以及您的解決方案符合規則也很重要
3. CRDT 不是一個萬能的解決方案 !
為了實現更快的上線應用,建議擁有一致的開發、測試、階段化和生產設置。除此之外,這意味著開發和測試設置必須有一個小型化的模型。檢查基于CRDT的數據庫是可用的 Docker 容器還是可用的虛擬設備。將數據庫副本部署到不同的子網上,這樣就可以模擬已連接和斷開連接的集群設置。
使用分布式多leader數據庫測試應用程序可能聽起來很復雜。但是在大多數情況下,需要測試的是數據一致性和應用程序可用性,這兩種情況分別是: 連接分布式數據庫時,以及數據庫之間存在網絡劃分時。
通常,可以在開發環境中設置一個三節點的測試用分布式數據庫,就可以覆蓋單元測試中的大多數測試場景。以下是測試應用的基本準則:
(1)網絡連接和節點間延遲低的測試用例
測試用例必須更加強調模擬沖突。通常,可以通過多次跨不同節點更新相同的數據來實現這一點,在所有節點上合并暫停并驗證數據的步驟。即使數據庫副本是連續同步的,測試最終一致性數據庫也需要暫停測試并檢查數據。
對于驗證,要驗證兩件事: 所有數據庫副本具有相同的數據,以及每當發生沖突時,沖突解決將按照設計進行。
(2)分區網絡的測試用例
這里,通常執行與前面相同的測試用例,但是分為兩個步驟。在第一步中,使用分區網絡測試應用程序,也就是說,數據庫無法彼此同步的情況。當網絡被拆分時,數據庫不會合并所有數據。因此,測試用例必須假設只讀取數據的本地副本。在第二步中,重新連接所有網絡以測試合并是如何發生的。如果遵循與前一節相同的測試用例,那么最終的數據必須與前一組步驟中的數據相同。
6. CRDT的應用示例
6.1 CRDT 用例: 投票,喜歡,愛心,表情符號等的計數
計數器有許多應用程序。作為一個分布式的應用程序,它可以收集選票,衡量一篇文章中“贊”的數量,或者跟蹤一條信息的表情符號反應數量。例如,每個地理位置的本地應用程序連接到最近的數據庫集群,更新計數器并用本地延遲讀取計數器。
可以使用 PN-Counter 的CRDT,示意代碼如下:
- void countVote(String pollId){
- // CRDT Command: COUNTER_INCREMENT poll:[pollId]:counter
- }
- long getVoteCount(String pollId){
- // CRDT Command: COUNTER_GET poll:[pollId]:counter
- }
6.2 CRDT 用例: 分布式緩存
分布式緩存的緩存機制與本地緩存中使用的機制相同: 應用程序嘗試從緩存中獲取對象。如果對象不存在,則應用程序從主存儲區檢索并將其保存在緩存中,并設置適當的過期時間。如果將緩存對象存儲在基于CRDT的數據庫中,該數據庫將自動在所有區域中提供緩存。例如,將每個電影的海報緩存到本地環境。
采用register的CRDT,示意代碼如下:
- void cacheString(String objectId, String cacheData, int ttl){
- // CRDT command: REGISTER_SET object:[objectId] [cacheData] ex [ttl]
- }
- String getFromCache(String objectId){
- // CRDT command: REGISTER_GET object:[objectId]
- }
6.3 CRDT 用例: 使用共享會話數據進行協作
CRDT最初是為支持多用戶文檔編輯而開發的。共享會話用于游戲、電子商務、社交網絡、聊天、協作、應急響應和許多其他應用程序。例如,一個簡單的婚禮祝福應用,在這個應用中,新婚夫婦的所有祝福者都將他們的禮物添加到購物車中,該購物車作為共享會話進行管理。
婚禮祝福的應用程序是一個分布式應用,每個實例都連接到本地數據庫。在開始一個會話時,應用的所有者邀請他們來自世界各地的朋友。一旦被邀請者接受邀請,他們就可以訪問會話對象。然后,他們購物并將商品添加到購物車中。
2P-Set 和一個 PN-counter 用于存放購物車中的物品,另外還有一個2P-Set 用于存儲活動會話,示意代碼如下:
- void joinSession(String sharedSessionID, sessionID){
- // CRDT command: SET_ADD sharedSession:[sharedSessionId] [sessionID]
- }
- void addToCart(String sharedSessionId, String productId, int count){
- // CRDT command:
- // ZSET_ADD sharedSession:[sharedSessionId] productId count
- }
- getCartItems(String sharedSessionId){
- // CRDT command:
- // ZSET_RANGE sharedSession:sessionSessionId 0 -1
- }
- 6.4 CRDT 應用: 多
6.4 CRDT 應用: 多區域數據攝取
List或隊列在許多應用程序中使用。例如,訂單處理系統在基于 CRDT的 List 數據結構中維護活動作業。這個解決方案在不同的地點收集任務。每個位置的分布式應用程序連接到最近的數據庫副本。這減少了寫操作的網絡延遲,從而允許應用程序支持大量作業提交。這些作業是從一個集群的 List 數據結構中彈出的。這保證了作業只被處理一次。
基于 CRDT的List,列表數據結構用作 FIFO 隊列的示意代碼如下:
- pushJob(String jobQueueId, String job){
- // CRDT command: LIST_LEFT_PUSH job:[jobQueueId] [job]
- }
- popJob(String jobQueueId){
- // CRDT command: LIST_RIGHT_POP job:[jobQueueId]
- }
小結
CRDT 對于許多用例來說確實是一個很好的工具,通過在這些場景和其他場景中利用基于 crdt 的數據庫,您可以專注于業務邏輯,而不用擔心區域之間的數據同步。最重要的是,基于 crdt 的數據庫可以提供本地的應用延遲,同時承諾即使在數據中心之間出現網絡故障時也可以提供強大的最終一致性。
但是,它可能不是所有用例(例如 ACID 事務)的最佳工具。基于 CRDT的數據庫通常非常適合微服務體系結構,其中每個微服務都有一個專門的數據庫。當然,區塊鏈或許是使用CRDT 的又一主要場景。
【參考資料與關聯閱讀】
- https://www.infoq.com/presentations/CRDT
- Strong Eventual Consistency and Conflict-free Replicated Data Types
- Key-CRDT Stores https://run.unl.pt/bitstream/10362/7802/1/Sousa_2012.pdf
- Conflict-free Replicated Data Types: An Overview https://arxiv.org/pdf/1806.10254.pdf
- A Conflict-Free Replicated JSON Datatype https://arxiv.org/abs/1608.03960
- A comprehensive study of Convergent and Commutative Replicated Data Types https://hal.inria.fr/inria-00555588/document
- Convergent and Commutative Replicated Data Type https://core.ac.uk/download/pdf/55634119.pdf
- Conflict-free replicated data type https://en.wikipedia.org/wiki/Conflict-freereplicateddata_type
- CRDTs: An UPDATE (or just a PUT) https://speakerdeck.com/lenary/crdts-an-update-or-just-a-put
- https://medium.com/@amberovsky/crdt-conflict-free-replicated-data-types-b4bfc8459d26