MQ的數據一致性,如何保證?
前言
上個月,我們有個電商系統出了個靈異事件:用戶支付成功了,但訂單狀態死活不改成“已發貨”。
折騰了半天才定位到問題:訂單服務的MQ消息,像人間蒸發一樣消失了。
這個Bug讓我明白:(MQ)消息隊列的數據一致性設計,絕對能排進分布式系統三大噩夢之一!
今天這篇文章跟大家一起聊聊,MQ如何保證數據一致性?希望對你會有所幫助。
1.數據一致性問題的原因
這些年在Kafka、RabbitMQ、RocketMQ踩過的坑,總結成四類致命原因:
- 生產者悲劇:消息成功進Broker,卻沒寫入磁盤就斷電。
- 消費者悲劇:消息消費成功,但業務執行失敗。
- 輪盤賭局:網絡抖動導致消息重復投遞。
- 數據孤島:數據庫和消息狀態割裂(下完單沒發券)
這些情況,都會導致MQ產生數據不一致的問題。
那么,如何解決這些問題呢?
2.消息不丟的方案
我們首先需要解決消息丟失的問題。
2.1 事務消息的兩階段提交
以RocketMQ的事務消息為例,工作原理就像雙11的預售定金偽代碼如下:
// 發送事務消息核心代碼
TransactionMQProducer producer = new TransactionMQProducer("group");
producer.setTransactionListener(new TransactionListener() {
// 執行本地事務(比如扣庫存)
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
return doBiz() ? LocalTransactionState.COMMIT : LocalTransactionState.ROLLBACK;
}
// Broker回調檢查本地事務狀態
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
return checkDB(msg.getTransactionId()) ? COMMIT : ROLLBACK;
}
});真實場景中,別忘了在checkLocalTransaction里做好妥協查詢(查流水表或分布式事務日志)。
去年在物流系統救火,就遇到過事務超時的坑——本地事務成功了,但因網絡問題沒收到Commit,導致Broker不斷回查。
2.2 持久化配置
RabbitMQ的坑都在配置表里:
配置項 | 例子 | 作用 |
隊列持久化 | durable=true | 隊列元數據不丟 |
消息持久化 | deliveryMode=2 | 消息存入磁盤 |
Lazy Queue | x-queue-mode=lazy | 消息直接寫盤不讀取進內存 |
Confirm機制 | publisher-confirm-type | 生產者確認消息投遞成功 |
RabbitMQ本地存儲+備份交換機雙重保護代碼如下:
channel.queueDeclare("order_queue", true, false, false,
new HashMap<String, Object>(){{
put("x-dead-letter-exchange", "dlx_exchange"); // 死信交換機
}});去年雙十一訂單系統就靠這個組合拳硬剛流量峰值:主隊列消息積壓觸發閾值時,自動轉移消息到備份隊列給應急服務處理。
2.3 副本配置
消息隊列 | 保命絕招 |
Kafka | acks=all + 副本數≥3 |
RocketMQ | 同步刷盤 + 主從同步策略 |
Pulsar | BookKeeper多副本存儲 |
上周幫一個金融系統遷移到Kafka,為了數據安全啟用了最高配置。
server.properties配置如下:
acks=all
min.insync.replicas=2
unclean.leader.election.enable=false結果發現吞吐量只剩原來的三分之一,但客戶說“錢比速度重要”——這一行哪有銀彈,全是取舍。
不同的業務場景,情況不一樣。
3.應對重復消費的方案
接下來,需要解決消息的重復消費問題。
3.1 唯一ID
訂單系統的架構課代表代碼:
// 雪花算法生成全局唯一ID
Snowflake snowflake = new Snowflake(datacenterId, machineId);
String bizId = "ORDER_" + snowflake.nextId();
// 查重邏輯(Redis原子操作)
String key = "msg:" + bizId;
if(redis.setnx(key, "1")) {
redis.expire(key, 72 * 3600);
processMsg();
}先使用雪花算法生成全局唯一ID,然后使用Redis的setnx命令加分布式鎖,來保證請求的唯一性。
某次促銷活動因Redis集群抖動,導致重復扣款。
后來改用:本地布隆過濾器+分布式Redis 雙校驗,總算解決這個世紀難題。
3.2 冪等設計
針對不同業務場景的三種對策:
場景 | 代碼示例 | 關鍵點 |
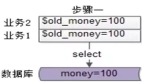
強一致性 | SELECT FOR UPDATE先查后更新 | 數據庫行鎖 |
最終一致性 | 版本號控制(類似CAS) | 樂觀鎖重試3次 |
補償型事務 | 設計反向操作(如退款、庫存回滾) | 操作日志必須落庫 |
去年重構用戶積分系統時,就靠著這個三板斧把錯誤率從0.1%降到了0.001%:
積分變更冪等示例如下:
public void addPoints(String userId, String orderId, Long points) {
if (pointLogDao.exists(orderId)) return;
User user = userDao.selectForUpdate(userId); // 悲觀鎖
user.setPoints(user.getPoints() + points);
userDao.update(user);
pointLogDao.insert(new PointLog(orderId)); // 冪等日志
}這里使用了數據庫行鎖實現的冪等性。
3.3 死信隊列
RabbitMQ的終極保命配置如下:
// 消費者設置手動ACK
channel.basicConsume(queue, false, deliverCallback, cancelCallback);
// 達到重試上限后進入死信隊列
public void process(Message msg) {
try {
doBiz();
channel.basicAck(deliveryTag);
} catch(Exception e) {
if(retryCount < 3) {
channel.basicNack(deliveryTag, false, true);
} else {
channel.basicNack(deliveryTag, false, false); // 進入DLX
}
}
}消費者端手動ACK消息。
在消費者端消費消息時,如果消費失敗次數,達到重試上限后進入死信隊列。
這個方案救了社交系統的推送服務——通過DLX收集全部異常消息,凌晨用補償Job重跑。
4.系統架構設計
接下來,從系統架構設計的角度,聊聊MQ要如何保證數據一致性?
4.1 生產者端
對于實效性要求不太高的業務場景,可以使用:本地事務表+定時任務掃描的補償方案。
流程圖如下:
 圖片
圖片
4.2 消費者端
消費者端為了防止消息風暴,要設置合理的并發消費線程數。
流程圖如下:
 圖片
圖片
4.3 終極方案
對于實時性要求比較高的業務場景,可以使用 事務消息+本地事件表 的黃金組合.
流程圖如下:
 圖片
圖片
5.血淚經驗十條
- 消息必加唯一業務ID(別用MQ自帶的ID)
- 消費邏輯一定要冪等(重復消費是必然事件)
- 數據庫事務和消息發送必須二選一(或者用事務消息)
- 消費者線程數不要超過分區數*2(Kafka的教訓)
- 死信隊列必須加監控報警(別等客服找你)
- 測試環境一定要模擬網絡抖動(chaos engineering)
- 消息體要兼容版本號(血的教訓警告)
- 不要用消息隊列做業務主流程(它只配當輔助)
- 消費者offset定時存庫(防止重平衡丟消息)
- 業務指標和MQ監控要聯動(比如訂單量和消息量的波動要同步)
總結
(MQ)消息隊列像金融系統的SWIFT結算網絡,看似簡單實則處處殺機。
真正的高手不僅要會調參,更要設計出能兼容可靠性與性能的架構。
記住,分布式系統的數據一致性不是銀彈,而是通過層層防御達成的動態平衡。
就像當年我在做資金結算系統時,老板說的那句震耳發聵的話:“寧可慢十秒,不可錯一分”。