













神經網絡成“病毒軟件”新宿主!國科大最新研究:嵌入惡意軟件后,性能下降不足1%
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
近日,中國科學院大學(國科大)團隊研究發現,神經網絡將成為“病毒軟件”肆意傳播的下一個陣地。
他們在arXiv提交的一篇題為“EvilModel: Hiding Malware Inside of Neural Network Models”的論文表明,惡意軟件可以直接被嵌入到機器學習模型的“人工神經元”中,并且幾乎不會影響模型的性能。

神經網絡成“病毒軟件”新宿主!國科大最新研究:嵌入惡意軟件后,性能下降不足1%
論文地址:https://arxiv.org/pdf/2107.08590v1.pdf
具體而言,由于模型的解釋性差和泛化能力強,通過神經網絡嵌入惡意軟件可以使模型在性能沒有影響或影響很小的情況下秘密傳播,他們發現,使用真實的惡意軟件替換AlexNet模型中50%左右的神經元,模型的準確率仍保持在93.1%以上。
同時,由于神經網絡的結構保持不變,這些大量惡意軟件成功地規避了防病毒引擎的安全掃描。
論文中寫道,經過實驗表明,在1%的準確率損失范圍內,一個178MB的AlexNet模型可以嵌入36.9MB的惡意軟件,并且VirusTotal中的反病毒引擎沒有給出任何可疑提示。作者表示,隨著人工智能的廣泛應用,神經網絡將成為惡意軟件傳播的載體。
1
“中毒”的神經網絡,有哪些特點?
在本篇論文中,作者以黑客的身份講述了如何將大量惡意軟件嵌入機器學習模型,而不被發現的方法。
僵尸網絡,勒索軟件,APT等惡意軟件是計算機安全的主要威脅。在維護過程中,攻擊者需要向受感染者發送命令和狀態,并規避一些敏感數據。同時,攻擊者還需要向其發送自定義的有效負載,以針對特定任務實施攻擊。為了規避檢測和軟件追蹤,以上命令、有效載荷和其他組件的傳遞必須秘密進行。
常用的秘密傳遞的方法包括Hammertoss(APT-29)、Pony以及Glupteba19,這些方法不需要攻擊者部署服務器,從而避免了防御者通過摧毀中心服務器來抵制惡意軟件的行為。還有一些攻擊者將惡意軟件附加到了圖像、文檔、壓縮文件等載體的背面,并確保載體結構不受損壞。不過這些方法都難以逃過反病毒引擎的檢測。
最先進的一種隱藏傳遞消息的方法被稱為隱寫術(steganography),它可以將秘密信息以不同的方式嵌入到普通文件中。在隱寫術中,數據通常會被隱藏在圖像像素最低的有效位(LSB)中。如灰度圖像的像素在0到255之間,當它用二進制表示時,最低有效位對圖像的外觀幾乎沒有影響,因此便于信息的隱藏。但由于信道容量較低,該方法并不適用于嵌入大量惡意軟件。
此前,騰訊研究人員提出了一種在神經網絡模型中隱藏惡意軟件的方法。這種方法類似于使用LSB的圖像隱寫( image steganography)功能——通過將模型中參數的最后幾位修改為惡意代碼,使其在不影響原始模型性能的前提下,將惡意負載秘密地傳遞給目標設備。由于PyTorch、TensorFlow等常用框架的模型參數是32位浮點數,權值較低,該方法并不會對神經網絡的全局判斷造成明顯影響。
與騰訊修改一個參數的LSB不同,中科院大學研究團隊修改了整個神經元來嵌入惡意軟件。
一般而言,隱藏層神經元會影響神經網絡的分類結果,因而其參數往往是固定的,然而研究人員發現,由于隱藏層中存在冗余神經元,一些神經元的變化對神經網絡的性能影響并不大。此外,在模型結構不變的情況下,隱藏的惡意軟件可以規避反病毒引擎的檢測。因此,通過對神經元的修改可以將惡意軟件隱蔽地嵌入并傳遞到目標設備中。

神經網絡成“病毒軟件”新宿主!國科大最新研究:嵌入惡意軟件后,性能下降不足1%
總結來看,基于神經網絡模型的惡意軟件呈現出以下特點:
- 通過神經網絡模型和反匯編,可以隱藏惡意軟件的特征,使其逃避檢測。
- 由于冗余神經元的存在和神經網絡的泛化能力,經修改后的神經網絡模型在不同的任務中仍保持其性能。
- 在特定任務中,神經網絡模型的規模很大,使大量惡意軟件傳播成為可能。
- 不依賴于其他系統漏洞,嵌入惡意軟件的模型可通過供應鏈的更新渠道或其他方式傳遞,不會引起防御者的注意。
基于以上因素, 隨著神經網絡的應用越來越廣泛,這種方法將在未來的惡意軟件傳輸中得到普遍應用。
2
嵌入惡意軟件只需三步
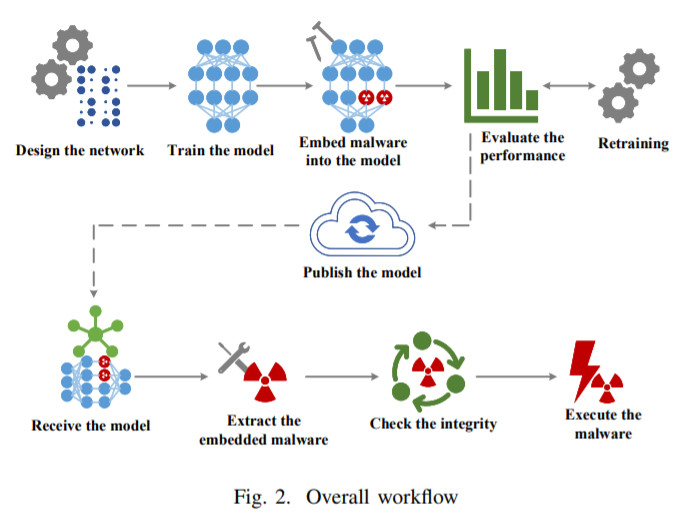
神經網絡成“病毒軟件”新宿主!國科大最新研究:嵌入惡意軟件后,性能下降不足1%
為了防止嵌入惡意軟件的模型性能受到影響,攻擊者通常遵循以下步驟:
1.設計神經網絡。為了確保嵌入更多的惡意軟件,攻擊者通常會引入更多的神經元。
2.選擇合適的現有模型,或者使用數據集對網絡進行訓練,獲得性能更好的模型。
3.選擇合適的層嵌入惡意軟件。嵌入惡意軟件后,攻擊者需要評估模型的性能,如果模型的性能損失超出可接受范圍,需要使用數據集重新訓練模型以獲得更高的性能。
一旦準備好模型,攻擊者就可以使用供應鏈污染(supply chain pollution)等方法將其發布到公共存儲庫或其他地方。
接收者假定是在目標設備上運行的程序,可以下載模型并從模型中提取嵌入的惡意軟件。在更新模型后,通常是先根據預定義規則提取惡意軟件,然后進行安全性檢查,最后再等達到預定義條件后運行惡意軟件。具體過程如下:
替換神經元參數
如上所述,神經元中的參數將會被惡意軟件替換。由于每個參數都是一個浮點數,攻擊者需要將惡意軟件中的字節轉換為32位浮點數,且保持在合理的時間間隔內。
惡意軟件嵌入
為了讓接收者能夠正確提取惡意軟件,攻擊者會采用一套規則將惡意軟件嵌入其中。本文提供了一個嵌入算法:對于要嵌入的惡意軟件,每次讀取3個字節,并將前綴添加到第一個字節,然后將字節轉換為具有big-endian格式的有效浮點數。
如果剩余的樣本少于3個字節,則添加“\x00”進行填充。在嵌入模型之前,這些數字會被轉換成張量。最后在神經網絡模型和指定的層中,通過替換每個神經元的權值和偏差,對神經元的進行修改。其中,每個神經元中的連接權重用來存儲轉換后的惡意軟件字節,偏差用來存儲惡意軟件的長度和哈希值。
惡意軟件提取
接收者的提取過程與嵌入過程相反。接收端需要提取給定層的神經元參數,并將參數轉換成浮點數。這些浮點數再轉換成big-endian字節格式,去掉字節前綴,得到二進制字節流。然后,根據第一個神經元長度記錄的偏差,接收者可以集成惡意軟件。此外,接收者可以通過比較惡意軟件的散列值與偏差記錄中的散列值來驗證提取過程。
在這項工作中,研究人員假定通信信道具有啟動防病毒安全掃描的能力,如果模型不安全可以將其攔截,并且模型性能一旦超過設定的閾值也會向終端用戶發出警報。
3
36.9MB惡意軟件,性能損失不足1%
研究人員采用AlexNet神經網絡架構進行了實驗。如下圖,AlexNet的輸入是一個224x224大小的單通道灰度圖像,輸出是一個大小為10的向量,分別代表10個類。
神經網絡成“病毒軟件”新宿主!國科大最新研究:嵌入惡意軟件后,性能下降不足1%
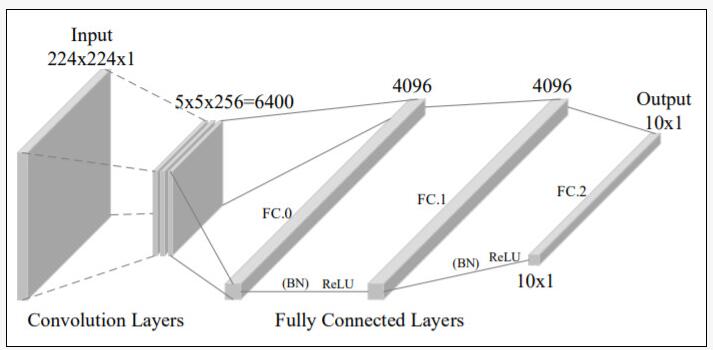
圖注:全連接結構
為了驗證該方法在處理大量惡意軟件時的表現,本次試驗采用了具有全連接架構的模型。如圖,對于AlexNet而言,FC.0是一個具有4096個神經元的隱藏層——從卷積層接收6400個輸入并生成4096個輸出。因此,FC.0層的每個神經元有6400個連接權值,這意味著6400×3/1024=18.75KB的惡意軟件可以嵌入到FC.0層的一個神經元中。
類似地,FC.1是一個有4096個神經元的隱藏層,它接收4096個輸入并產生4096個輸出,因此,4096×3/1024=12KB的惡意軟件可以嵌入到FC.1層神經元中(FC.2是輸出層,接收4096個輸入后生成10個輸出)
研究人員對全連接層上有BN和沒有BN的模型進行了性能比較。BN(Batch normalization,即批處理規范化)是一種加速深層網收斂的有效技術,BN層可應用于全連通層中的仿射變換和激活函數之間。
經過大約100個階段的訓練,實驗表明,在不使用BN的測試集上訓練的模型,其準確率為93.44%,在使用BN的測試集上訓練的模型,其準確率為93.75%。
為了模擬真實場景,實驗使用了公共存儲庫的真實惡意軟件樣本,并將這些樣本上傳到了VirusTotal,為了評估該方法的有效性,作者進行了以下實驗設置,并嘗試回答以下7個問題:
1.攻擊方法行得通么?
實驗方案:使用惡意軟件樣本( sample)1-6分別替換FC.1層中的神經元,并在測試集上評估其性能。測試準確率在93.43%~93.45%之間。然后,從模型中提取惡意軟件,并計算其SHA-1哈希值。哈希值保持不變。結果表明,該方法是可行的。
2.模型中可以嵌入多少惡意軟件?
3.模型的精度損失是多少?
4.BN是否有幫助?
實驗方案:對于問題2~3,作者在AlexNet上用 sample1-6分別替換了FC.1層的5個、10個、...、4095個神經元;用 sample3-8替代FC.0層的有BN和無BN的AlexNet。
神經網絡成“病毒軟件”新宿主!國科大最新研究:嵌入惡意軟件后,性能下降不足1%
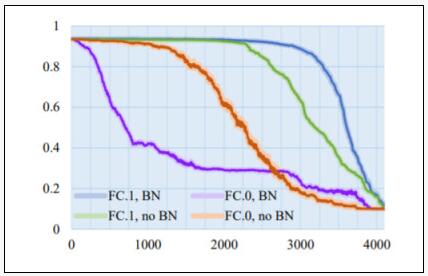
圖注:在不同層上替換不同神經元的準確率統計
FC.0中的每個神經元可以嵌入18.75KB的惡意軟件。由于一個 sample最多可以替換FC.0和FC.1中的5個神經元,作者重復了替換過程,并用相同的樣本替換各層中的神經元,直到替換的神經元數量達到目標。最后,作者得到了6組準確率數據,結果如上圖所示。
神經網絡成“病毒軟件”新宿主!國科大最新研究:嵌入惡意軟件后,性能下降不足1%

表注:更換不同數量神經元的準確率
因此,可以得出結論:當替換較少數量的神經元時,對模型的準確率影響不大。對于帶有BN的AlexNet,當替換FC.1中的1025個神經元時(25%,相當于嵌入了12MB的惡意軟件),準確率仍然可以達到93.63%。當替換2050個神經元(50%)時,準確率為93.11%。當超過2105個神經元被替換時,準確率下降到93%以下。當超過2900個神經元被替換時,準確率下降到90%以下,準確率明顯下降。當所有神經元都被替換時,準確率下降到10%左右(相當于隨機猜測)。
5.哪一層更適合嵌入惡意軟件?
實驗方案:作者選擇在AlexNet的所有層嵌入惡意軟件。用sample替換每一層中的神經元,并記錄其準確率。由于不同的層具有不同的參數數量,作者使用百分比來表示替換的數量,如下圖所示。
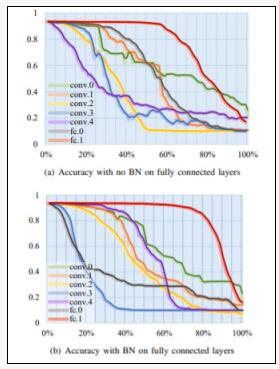
神經網絡成“病毒軟件”新宿主!國科大最新研究:嵌入惡意軟件后,性能下降不足1%
對于有BN和沒有BN的AlexNet,FC.1在所有層都具有出色的性能。可以推斷,對于完全連接的層,更接近輸出層的層更適合嵌入。
6.如何通過再訓練恢復準確率?
實驗方案:作者選擇了性能與平均準確率相近的sample,并對有和沒有BN的模型分別替換了FC.0和FC.1層中的50,100,...,4050個神經元。然后,“凍結”惡意軟件嵌入層,并使用相同的訓練集重新訓練它們1個 epoch。記錄重新訓練前后測試集上的準確率。對每個模型進行再訓練后,提取模型中嵌入的惡意軟件,計算惡意軟件的SHA-1哈希值,并與原始哈希值進行匹配。
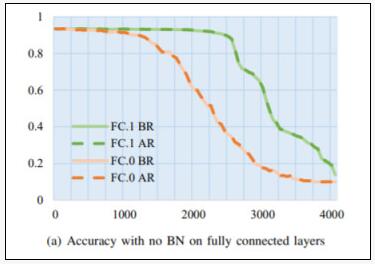
神經網絡成“病毒軟件”新宿主!國科大最新研究:嵌入惡意軟件后,性能下降不足1%
結果如上所示,對于完全連接層中沒有BN的模型,替換神經元參數后的再訓練對模型性能沒有明顯的改善。
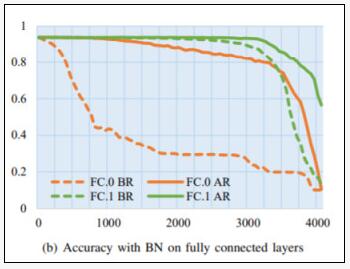
神經網絡成“病毒軟件”新宿主!國科大最新研究:嵌入惡意軟件后,性能下降不足1%
對于帶有BN的模型,再訓練前后的準確率有明顯的變化。
因此,如果攻擊者使用帶有BN和再訓練的模型在FC.1上嵌入惡意軟件,并希望將模型的準確率損失控制在1%以內,那么將有超過3150個神經元可以替換。這將導致3150×12/1024=36.9MB的惡意軟件嵌入。
7.殺毒軟件對植入病毒的模型有效么?
實驗方案與結果:作者將一些嵌入惡意軟件的模型上傳到VirusTotal,結果發現:VirusTotal將這些模型識別為zip文件。58個殺毒引擎參與了檢測工作,沒有發現可疑情況。這意味著該方法可以迷惑傳統殺毒軟件。
4
如何預防惡意軟件攻擊?
作者建議在啟動模型時,對模型進行檢查。由于嵌入的惡意軟件將在目標設備上“工作”,因此可以使用靜態和動態分析、啟發式方法等傳統方法對其進行檢測和分析。由于攻擊者可以發起供應鏈污染(supply chain pollution)等攻擊,因此模型的最初提供者也應該采取措施防止此類攻擊。
5
總結
這篇論文發現了一種神經網絡模型傳遞“病毒”的方法。當神經網絡的參數被惡意替換時,模型的結構可能保持不變,并且“病毒”在神經元中會被反匯編(disassembled )。由于“病毒”的特征不再可用,它可以躲避普通殺毒軟件的檢測。
由于神經網絡模型對變化具有較強的魯棒性,因此當配置良好時,其性能不會有明顯的損失。實驗表明,在對全連通層進行批量歸一化的情況下,178MB-AlexNet模型可以嵌入36.9MB的惡意軟件,而準確率損失小于1%。
由于神經網絡模型對變化具有較強的魯棒性,因此當配置良好時,其性能不會有明顯的損失。實驗表明,在對全連接層進行批量歸一化的情況下,178MB-AlexNet模型可以嵌入36.9MB的惡意軟件,而準確率損失小于1%。在VirusTotal上的實驗也證明了,在神經網絡上嵌入的“病毒”,具有極強的隱蔽性。












