Kafka 如何解決消息不丟失?
本文轉載自微信公眾號「微觀技術」,作者微觀技術。轉載本文請聯系微觀技術公眾號。
大家好,我是Tom哥~
Kafka 消息框架,大家一定不陌生,很多人工作中都有接觸。它的核心思路,通過一個高性能的MQ服務來連接生產和消費兩個系統,達到系統間的解耦,有很強的擴展性。
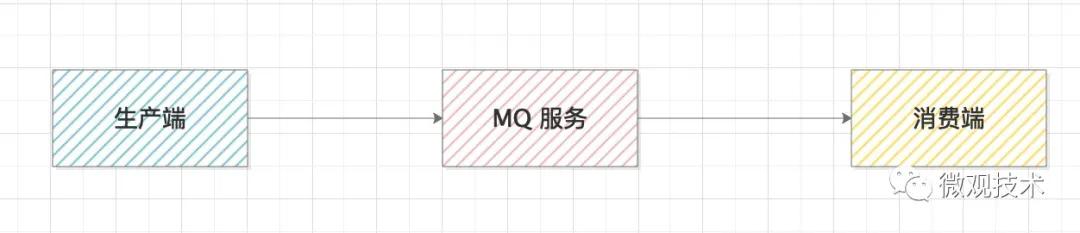
你可能會有疑問,如果中間某一個環節斷掉了,那怎么辦?
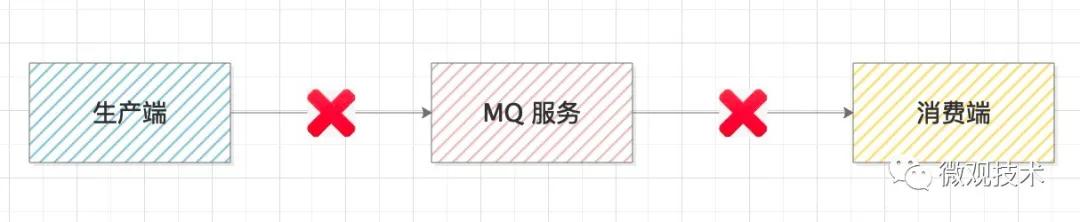
這種情況,我們稱之為消息丟失,會造成系統間的數據不一致。
那如何解決這個問題?需要從生產端、MQ服務端、消費端,三個維度來處理。
1、生產端
生產端的職責就是,確保生產的消息能到達MQ服務端,這里我們需要有一個響應來判斷本次的操作是否成功。
- Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)
比如,上面的代碼就是通過一個Callback函數,來判斷消息是否發送成功,如果失敗,我們需要補償處理。
另外,為了提升發送時的靈活性,kafka提供了多種參數,供不同業務自己選擇
1.1 參數 acks
該參數表示有多少個分區副本收到消息,才認為本次發送是成功的。
acks=0,只要發送消息就認為成功,生產端不等待服務器節點的響應
acks=1,表示生產者收到 leader 分區的響應就認為發送成功
acks=-1,只有當 ISR 中的副本全部收到消息時,生產端才會認為是成功的。這種配置是最安全的,但由于同步的節點較多,吞吐量會降低。
1.2 參數 retries
表示生產端的重試次數,如果重試次數用完后,還是失敗,會將消息臨時存儲在本地磁盤,待服務恢復后再重新發送。建議值 retries=3
1.3 參數 retry.backoff.m
消息發送超時或失敗后,間隔的重試時間。一般推薦的設置時間是 300 毫秒。
這里要特別注意一種特殊情況,如果MQ服務沒有正常響應,不一定代表消息發送失敗,也有可能是響應時正好趕上網絡抖動,響應超時。
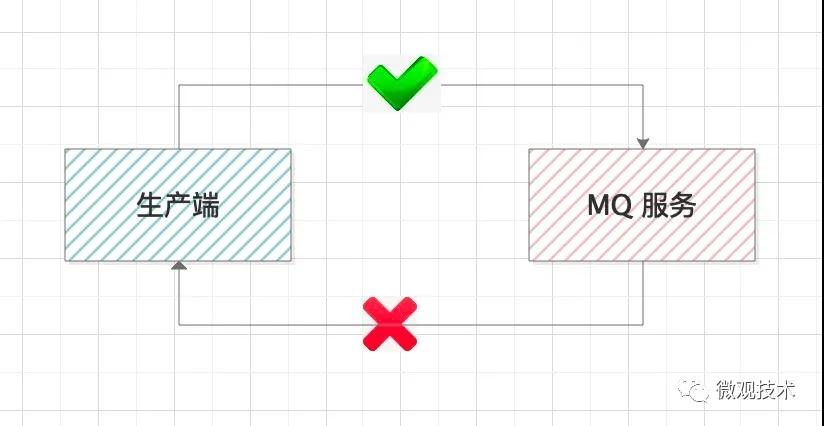
當生產端做完這些,一定能保證消息發送成功了,但可能發送多次,這樣就會導致消息重復,這個我們后面再講解決方案。
2、MQ服務端
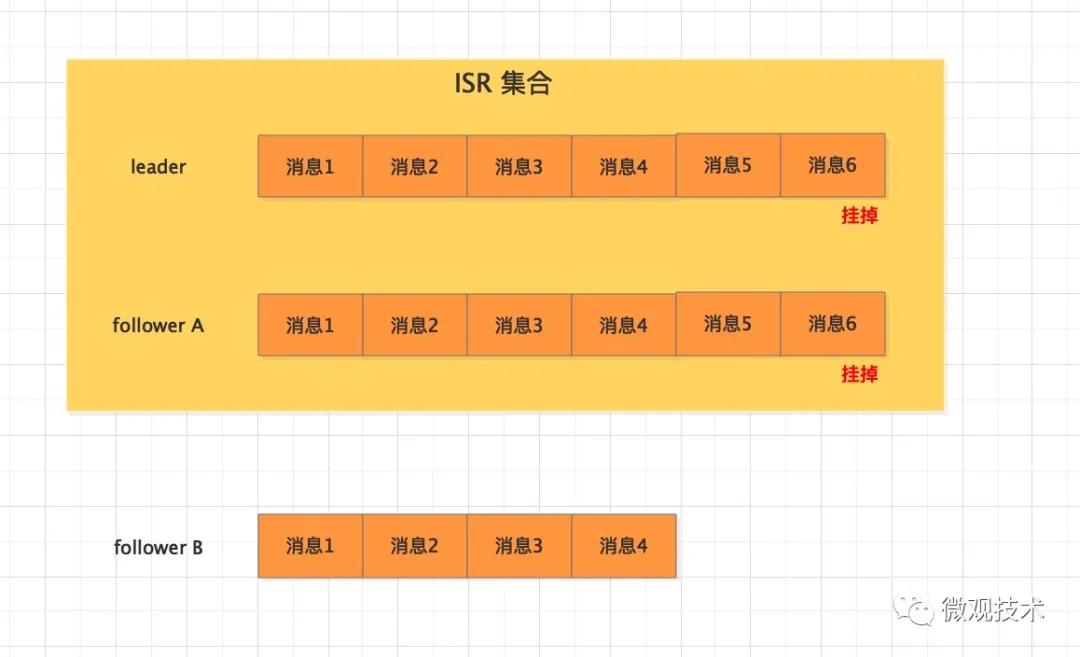
MQ服務端作為消息的存儲介質,也有可能會丟失消息。比如:一個分區突然掛掉,那么怎么保證這個分區的數據不丟失,我們會引入副本概念,通過備份來解決這個問題。
具體可設置哪些參數?
2.1 參數 replication.factor
表示分區副本的個數,replication.factor >1 當leader 副本掛了,follower副本會被選舉為leader繼續提供服務。
2.2 參數 min.insync.replicas
表示 ISR 最少的副本數量,通常設置 min.insync.replicas >1,這樣才有可用的follower副本執行替換,保證消息不丟失
2.3 參數 unclean.leader.election.enable
是否可以把非 ISR 集合中的副本選舉為 leader 副本。
如果設置為true,而follower副本的同步消息進度落后較多,此時被選舉為leader,會導致消息丟失,慎用。
3、消費端
消費端要做的是把消息完整的消費處理掉。但是這里面有個提交位移的步驟。
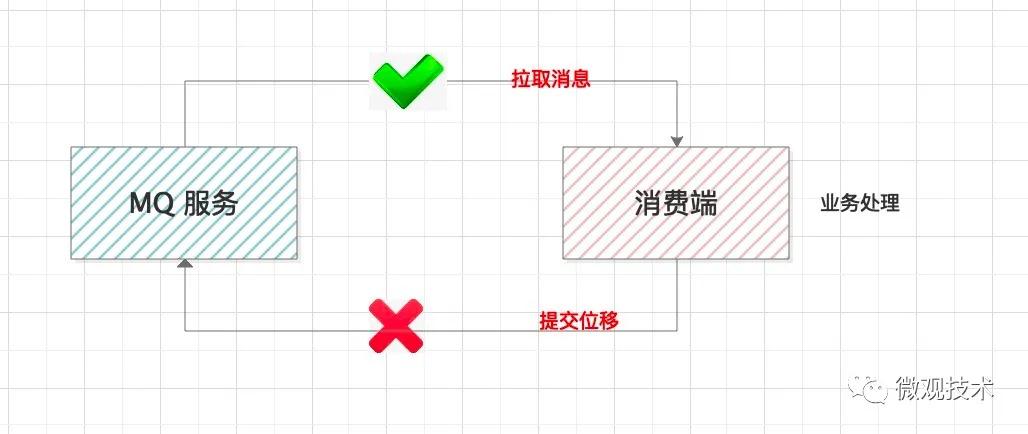
有的同學,考慮到業務處理消耗時間較長,會單獨啟動線程拉取消息存儲到本地內存隊列,然后再搞個線程池并行處理業務邏輯。這樣設計有個風險,本地消息如果沒有處理完,服務器宕機了,會造成消息丟失。
正確的做法:拉取消息 --- 業務處理 ---- 提交消費位移
關于提交位移,kafka提供了集中參數配置
參數 enable.auto.commit
表示消費位移是否自動提交。
如果拉取了消息,業務邏輯還沒處理完,提交了消費位移但是消費端卻掛了,消費端恢復或其他消費端接管該分片再也拉取不到這條消息,會造成消息丟失。所以,我們通常設置 enable.auto.commit=false,手動提交消費位移。
- List<String> messages = consumer.poll();
- processMsg(messages);
- consumer.commitOffset();
這個方案,會產生另外一個問題,我們來看下這個圖:
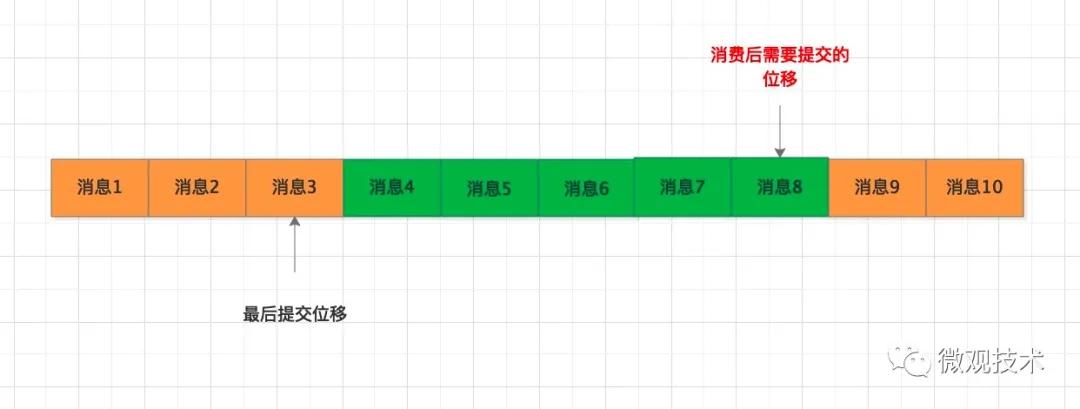
拉取了消息4~消息8,業務處理后,在提交消費位移時,不湊巧系統宕機了,最后的提交位移并沒有保存到MQ 服務端,下次拉取消息時,依然是從消息4開始拉取,但是這部分消息已經處理過了,這樣便會導致重復消費。
如何解決重復消費,避免引發數據不一致
首先,要解決MQ 服務端的重復消息。kafka 在 0.11.0 版本后,每條消息都有唯一的message id, MQ服務采用空間換時間方式,自動對重復消息過濾處理,保證接口的冪等性。
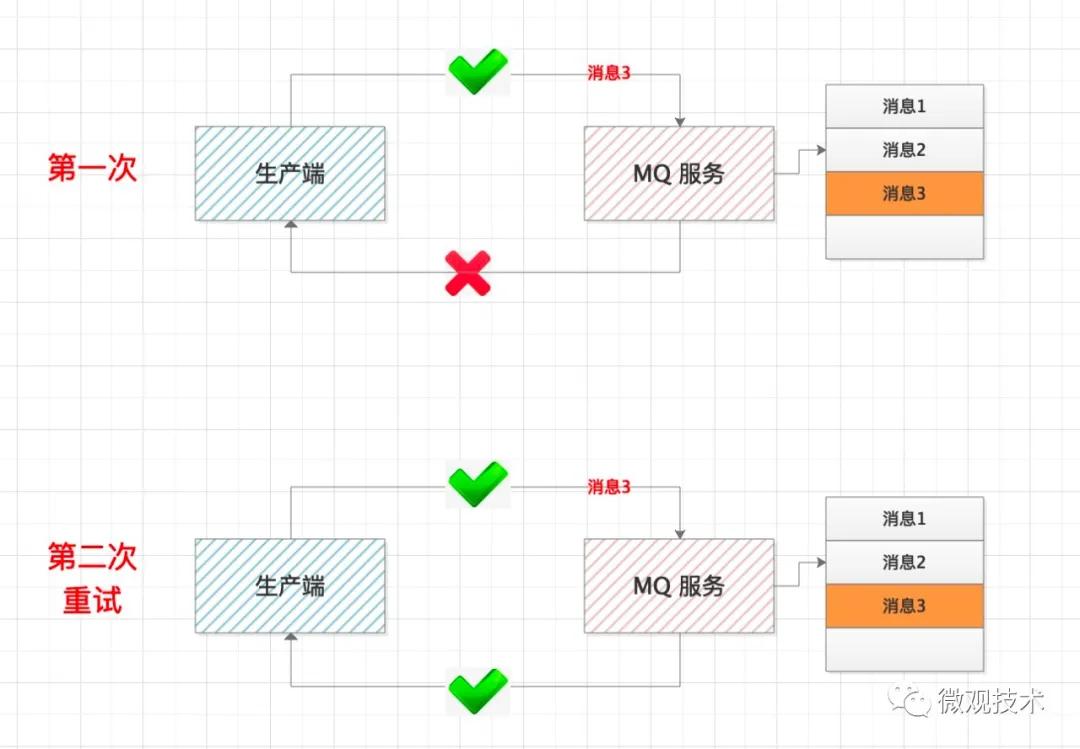
但這個不能根本上解決消息重復問題,即使MQ服務中存儲的消息沒有重復,但消費端是采用拉取方式,如果重復拉取,也會導致重復消費,如何解決這種場景問題?
方案一:只拉取一次(消費者拉取消息后,先提交 offset 后再處理消息),但是如果系統宕機,業務處理沒有正常結束,后面再也拉取不到這些消息,會導致數據不一致,該方案很少采用。
方案二:允許拉取重復消息,但是消費端自己做冪等性控制。保證只成功消費一次。
關于冪等技術方案很多,我們可以采用數據表或Redis緩存存儲處理標識,每次拉取到消息,處理前先校驗處理狀態,再決定是處理還是丟棄消息。