DLF +DDI 一站式數(shù)據(jù)湖構(gòu)建與分析最佳實(shí)踐
背景
隨著數(shù)據(jù)時(shí)代的不斷發(fā)展,數(shù)據(jù)量爆發(fā)式增長(zhǎng),數(shù)據(jù)形式也變的更加多樣。傳統(tǒng)數(shù)據(jù)倉(cāng)庫(kù)模式的成本高、響應(yīng)慢、格式少等問(wèn)題日益凸顯。于是擁有成本更低、數(shù)據(jù)形式更豐富、分析計(jì)算更靈活的數(shù)據(jù)湖應(yīng)運(yùn)而生。
數(shù)據(jù)湖作為一個(gè)集中化的數(shù)據(jù)存儲(chǔ)倉(cāng)庫(kù),支持的數(shù)據(jù)類型具有多樣性,包括結(jié)構(gòu)化、半結(jié)構(gòu)化以及非結(jié)構(gòu)化的數(shù)據(jù),數(shù)據(jù)來(lái)源上包含數(shù)據(jù)庫(kù)數(shù)據(jù)、binglog 增量數(shù)據(jù)、日志數(shù)據(jù)以及已有數(shù)倉(cāng)上的存量數(shù)據(jù)等。數(shù)據(jù)湖能夠?qū)⑦@些不同來(lái)源、不同格式的數(shù)據(jù)集中存儲(chǔ)管理在高性價(jià)比的存儲(chǔ)如 OSS 等對(duì)象存儲(chǔ)中,并對(duì)外提供統(tǒng)一的數(shù)據(jù)目錄,支持多種計(jì)算分析方式,有效解決了企業(yè)中面臨的數(shù)據(jù)孤島問(wèn)題,同時(shí)大大降低了企業(yè)存儲(chǔ)和使用數(shù)據(jù)的成本。
數(shù)據(jù)湖架構(gòu)及關(guān)鍵技術(shù)
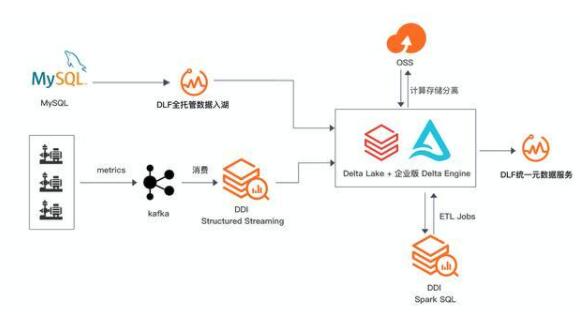
企業(yè)級(jí)數(shù)據(jù)湖架構(gòu)如下:
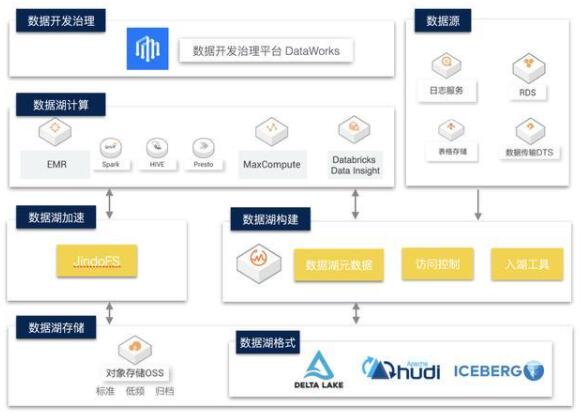
數(shù)據(jù)湖存儲(chǔ)與格式
數(shù)據(jù)湖存儲(chǔ)主要以云上對(duì)象存儲(chǔ)作為主要介質(zhì),其具有低成本、高穩(wěn)定性、高可擴(kuò)展性等優(yōu)點(diǎn)。
數(shù)據(jù)湖上我們可以采用支持 ACID 的數(shù)據(jù)湖存儲(chǔ)格式,如 Delta Lake、Hudi、Iceberg。這些數(shù)據(jù)湖格式有自己的數(shù)據(jù) meta 管理能力,能夠支持 Update、Delete 等操作,以批流一體的方式解決了大數(shù)據(jù)場(chǎng)景下數(shù)據(jù)實(shí)時(shí)更新的問(wèn)題。在當(dāng)前方案中,我們主要介紹Delta Lake的核心能力和應(yīng)用場(chǎng)景。
Delta Lake 的核心能力
Delta Lake 是一個(gè)統(tǒng)一的數(shù)據(jù)管理系統(tǒng),為云上數(shù)據(jù)湖帶來(lái)數(shù)據(jù)可靠性和快速分析。Delta Lake 運(yùn)行在現(xiàn)有數(shù)據(jù)湖之上,并且與 Apache Spark 的 API 完全兼容。使用Delta Lake,您可以加快高質(zhì)量數(shù)據(jù)導(dǎo)入數(shù)據(jù)湖的速度,團(tuán)隊(duì)也可以在云服務(wù)上快速使用這些數(shù)據(jù),安全且可擴(kuò)展。
ACID 事務(wù)性:Delta Lake 在多個(gè)寫操作之間提供 ACID 事務(wù)性。每一次寫操作都是一個(gè)事務(wù)操作,事務(wù)日志(Transaction Log)中記錄的寫操作都有一個(gè)順序序列。事務(wù)日志(Transaction Log)跟蹤了文件級(jí)別的寫操作,并使用了樂(lè)觀鎖進(jìn)行并發(fā)控制,這非常適用于數(shù)據(jù)湖,因?yàn)閲L試修改相同文件的多次寫操作的情況并不經(jīng)常發(fā)生。當(dāng)發(fā)生沖突時(shí),Delta Lake 會(huì)拋出一個(gè)并發(fā)修改異常,拋給供用戶處理并重試其作業(yè)。Delta Lake 還提供了最高級(jí)別的隔離(可序列化隔離),允許工程師不斷地向目錄或表寫入數(shù)據(jù),而使用者不斷地從同一目錄或表讀取數(shù)據(jù),讀取數(shù)據(jù)時(shí)會(huì)看到數(shù)據(jù)的最新快照。
Schema 管理(Schema management):Delta Lake 會(huì)自動(dòng)驗(yàn)證正在寫入的DataFrame 的 Schema 是否與表的 Schema 兼容。若表中存在但 DataFrame 中不存在的列則會(huì)被設(shè)置為 null。如果 DataFrame 中有額外的列不在表中,那么該操作將會(huì)拋出異常。Delta Lake 具有 DDL(數(shù)據(jù)定義語(yǔ)言)顯式添加新列的功能,并且能夠自動(dòng)更新 Schema。
可伸縮的元數(shù)據(jù)(Metadata)處理:Delta Lake 將表或目錄的元數(shù)據(jù)信息存儲(chǔ)在事務(wù)日志(Transaction Log)中,而不是元數(shù)據(jù) Metastore 中。這使得 Delta Lake夠在固定時(shí)間內(nèi)列出大目錄中的文件,并且在讀取數(shù)據(jù)時(shí)效率很高。
數(shù)據(jù)版本控制和時(shí)間旅行(Time Travel):Delta Lake 允許用戶讀取表或目錄的歷史版本快照。當(dāng)文件在寫入過(guò)程中被修改時(shí),Delta Lake 會(huì)創(chuàng)建文件的新的版本并保留舊版本。當(dāng)用戶想要讀取表或目錄的較舊版本時(shí),他們可以向 Apach Spark的 read API 提供時(shí)間戳或版本號(hào),Delta Lake 根據(jù)事務(wù)日志(Transaction Log)中的信息來(lái)構(gòu)建該時(shí)間戳或版本的完整快照。這非常方便用戶來(lái)復(fù)現(xiàn)實(shí)驗(yàn)和報(bào)告,如果需要,還可以將表還原為舊版本。
統(tǒng)一批流一體:除了批處理寫入之外,Delta Lake 還可以作為 Apache Spark 的結(jié)構(gòu)化流的高效流接收器(Streaming Sink)。與 ACID 事務(wù)和可伸縮元數(shù)據(jù)處理相結(jié)合,高效的流接收器(Streaming Sink)支持大量近實(shí)時(shí)的分析用例,而無(wú)需維護(hù)復(fù)雜的流和批處理管道。
記錄更新和刪除:Delta Lake 將支持合并、更新和刪除的 DML(數(shù)據(jù)管理語(yǔ)言)命令。這使得工程師可以輕松地在數(shù)據(jù)湖中插入和刪除記錄,并簡(jiǎn)化他們的變更數(shù)據(jù)捕獲和 GDPR(一般數(shù)據(jù)保護(hù)條例)用例。由于 Delta Lake 在文件級(jí)粒度上進(jìn)行跟蹤和修改數(shù)據(jù),因此它比讀取和覆蓋整個(gè)分區(qū)或表要高效得多。
數(shù)據(jù)湖構(gòu)建與管理
1. 數(shù)據(jù)入湖
企業(yè)的原始數(shù)據(jù)存在于多種數(shù)據(jù)庫(kù)或存儲(chǔ)系統(tǒng),如關(guān)系數(shù)據(jù)庫(kù) MySQL、日志系統(tǒng)SLS、NoSQL 存儲(chǔ) HBase、消息數(shù)據(jù)庫(kù) Kafka 等。其中大部分的在線存儲(chǔ)都面向在線事務(wù)型業(yè)務(wù),并不適合在線分析的場(chǎng)景,所以需要將數(shù)據(jù)以無(wú)侵入的方式同步至成本更低且更適合計(jì)算分析的對(duì)象存儲(chǔ)。
常用的數(shù)據(jù)同步方式有基于 DataX、Sqoop 等數(shù)據(jù)同步工具做批量同步;同時(shí)在對(duì)于實(shí)時(shí)性要求較高的場(chǎng)景下,配合使用 Kafka+spark Streaming / flink 等流式同步鏈路。目前很多云廠商提供了一站式入湖的解決方案,幫助客戶以更快捷更低成本的方式實(shí)現(xiàn)數(shù)據(jù)入湖,如阿里云 DLF 數(shù)據(jù)入湖。
2. 統(tǒng)一元數(shù)據(jù)服務(wù)
對(duì)象存儲(chǔ)本身是沒(méi)有面向大數(shù)據(jù)分析的語(yǔ)義的,需要結(jié)合 Hive Metastore Service 等元數(shù)據(jù)服務(wù)為上層各種分析引擎提供數(shù)據(jù)的 Meta 信息。數(shù)據(jù)湖元數(shù)據(jù)服務(wù)的設(shè)計(jì)目標(biāo)是能夠在大數(shù)據(jù)引擎、存儲(chǔ)多樣性的環(huán)境下,構(gòu)建不同存儲(chǔ)系統(tǒng)、格式和不同計(jì)算引擎統(tǒng)一元數(shù)據(jù)視圖,并具備統(tǒng)一的權(quán)限、元數(shù)據(jù),且需要兼容和擴(kuò)展開(kāi)源大數(shù)據(jù)生態(tài)元數(shù)據(jù)服務(wù),支持自動(dòng)獲取元數(shù)據(jù),并達(dá)到一次管理多次使用的目的,這樣既能夠兼容開(kāi)源生態(tài),也具備極大的易用性。
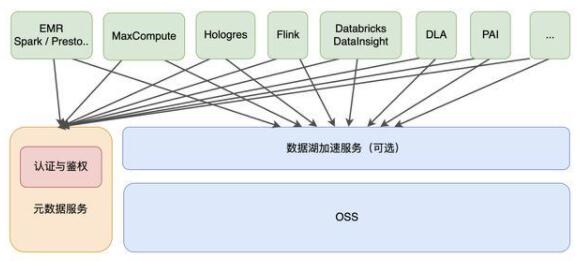
數(shù)據(jù)湖計(jì)算與分析
相比于數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)湖以更開(kāi)放的方式對(duì)接多種不同的計(jì)算引擎,如傳統(tǒng)開(kāi)源大數(shù)據(jù)計(jì)算引擎 Hive、Spark、Presto、Flink 等,同時(shí)也支持云廠商自研的大數(shù)據(jù)引擎,如阿里云 MaxCompute、Hologres 等。在數(shù)據(jù)湖存儲(chǔ)與計(jì)算引擎之間,一般還會(huì)提供數(shù)據(jù)湖加速的服務(wù),以提高計(jì)算分析的性能,同時(shí)減少帶寬的成本和壓力。
Databricks 數(shù)據(jù)洞察-商業(yè)版的 Spark 數(shù)據(jù)計(jì)算與分析引擎
DataBricks 數(shù)據(jù)洞察(DDI)做為阿里云上全托管的 Spark 分析引擎,能夠簡(jiǎn)單快速幫助用戶對(duì)數(shù)據(jù)湖的數(shù)據(jù)進(jìn)行計(jì)算與分析。
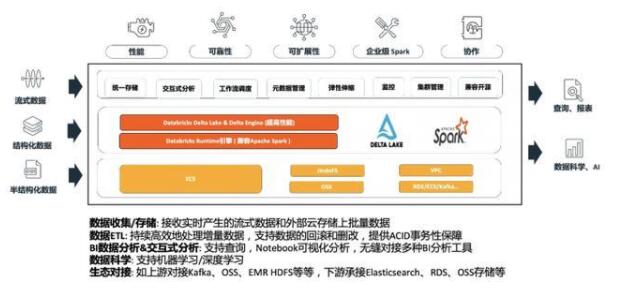
Saas 全托管 Spark:免運(yùn)維,無(wú)需關(guān)注底層資源情況,降低運(yùn)維成本,聚焦分析業(yè)務(wù)
完整 Spark 技術(shù)棧集成:一站式集成 Spark 引擎和 Delta Lake 數(shù)據(jù)湖,100%兼容開(kāi)源 Spark 社區(qū)版;Databricks 做商業(yè)支持,最快體驗(yàn) Spark 最新版本特性
總成本降低:商業(yè)版本 Spark 及 Delta Lake 性能優(yōu)勢(shì)顯著;同時(shí)基于計(jì)算存儲(chǔ)分離架構(gòu),存儲(chǔ)依托阿里云 OSS 對(duì)象存儲(chǔ),借助阿里云 JindoFS 緩存層加速;能夠有效降低集群總體使用成本
高品質(zhì)支持以及 SLA 保障:阿里云和 Databricks 提供覆蓋 Spark 全棧的技術(shù)支持;提供商業(yè)化 SLA 保障與7*24小時(shí) Databricks 專家支持服務(wù)
Databricks 數(shù)據(jù)洞察+ DLF 數(shù)據(jù)湖構(gòu)建與流批一體分析實(shí)踐
企業(yè)構(gòu)建和應(yīng)用數(shù)據(jù)湖一般需要經(jīng)歷數(shù)據(jù)入湖、數(shù)據(jù)湖存儲(chǔ)與管理、數(shù)據(jù)湖探索與分析等幾個(gè)過(guò)程。本文主要介紹基于阿里云數(shù)據(jù)湖構(gòu)建(DLF)+Databricks 數(shù)據(jù)洞察(DDI)構(gòu)建一站式的數(shù)據(jù)入湖,批流一體數(shù)據(jù)分析實(shí)戰(zhàn)。
流處理場(chǎng)景:
實(shí)時(shí)場(chǎng)景維護(hù)更新兩張 Delta 表:
delta_aggregates_func 表:RDS 數(shù)據(jù)實(shí)時(shí)入湖 。
delta_aggregates_metrics 表:工業(yè) metric 數(shù)據(jù)通過(guò) IoT 平臺(tái)采集到云 Kafka ,經(jīng)由 Spark Structured Streaming 實(shí)時(shí)入湖。
批處理場(chǎng)景:
以實(shí)時(shí)場(chǎng)景生成兩張 Delta 作為數(shù)據(jù)源,進(jìn)行數(shù)據(jù)分析執(zhí)行 Spark jobs,通過(guò) Databrick 數(shù)據(jù)洞察作業(yè)調(diào)度定時(shí)執(zhí)行。
前置條件
1. 服務(wù)開(kāi)通
確保 DLF、OSS、Kafka、DDI、RDS、DTS 等云產(chǎn)品服務(wù)已開(kāi)通。注意 DLF、RDS、Kafka、DDI 實(shí)例均需在同一 Region 下。
2. RDS 數(shù)據(jù)準(zhǔn)備
RDS 數(shù)據(jù)準(zhǔn)備,在 RDS 中創(chuàng)建數(shù)據(jù)庫(kù) dlfdb。在賬戶中心創(chuàng)建能夠讀取 engine_funcs數(shù)據(jù)庫(kù)的用戶賬號(hào),如 dlf_admin。
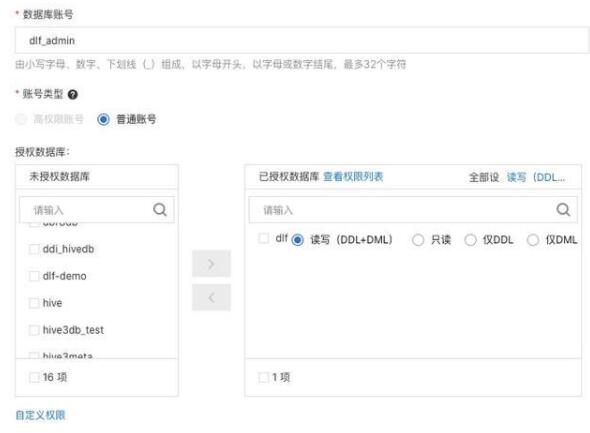
通過(guò) DMS 登錄數(shù)據(jù)庫(kù),運(yùn)行一下語(yǔ)句創(chuàng)建 engine_funcs 表,及插入少量數(shù)據(jù)。
- CREATE TABLE `engine_funcs` ( `emp_no` int(11) NOT NULL, `engine_serial_number` varchar(20) NOT NULL, `engine_serial_name` varchar(20) NOT NULL, `target_engine_serial_number` varchar(20) NOT NULL, `target_engine_serial_name` varchar(20) NOT NULL, `operator` varchar(16) NOT NULL, `create_time` DATETIME NOT NULL, `update_time` DATETIME NOT NULL, PRIMARY KEY (`emp_no`)) ENGINE=InnoDB DEFAULT CHARSET=utf8INSERT INTO `engine_funcs` VALUES (10001,'1107108133','temperature','1107108144','temperature','/', now(), now());INSERT INTO `engine_funcs` VALUES (10002,'1107108155','temperature','1107108133','temperature','/', now(), now());INSERT INTO `engine_funcs` VALUES (10003,'1107108155','runTime','1107108166','speed','/', now(), now());INSERT INTO `engine_funcs` VALUES (10004,'1107108177','pressure','1107108155','electricity','/', now(), now());INSERT INTO `engine_funcs` VALUES (10005,'1107108188','flow' ,'1107108111','runTime','/', now(), now());
RDS數(shù)據(jù)實(shí)時(shí)入湖
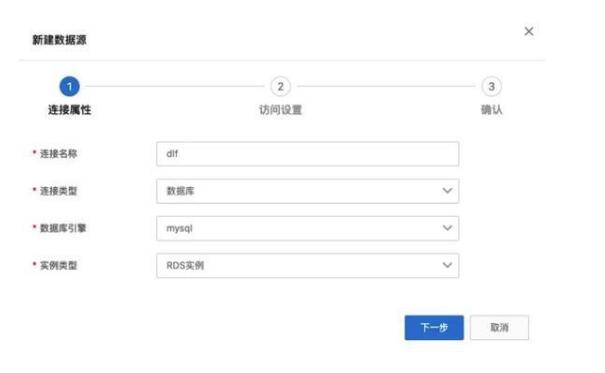
1. 創(chuàng)建數(shù)據(jù)源
進(jìn)入 DLF 控制臺(tái)界面:https://dlf.console.aliyun.com/cn-hangzhou/home,點(diǎn)擊菜單 數(shù)據(jù)入湖 -> 數(shù)據(jù)源管理。
點(diǎn)擊 新建數(shù)據(jù)源。填寫連接名稱,選擇數(shù)據(jù)準(zhǔn)備中的使用的 RDS 實(shí)例,填寫賬號(hào)密碼,點(diǎn)擊“連接測(cè)試”驗(yàn)證網(wǎng)絡(luò)連通性及賬號(hào)可用性。
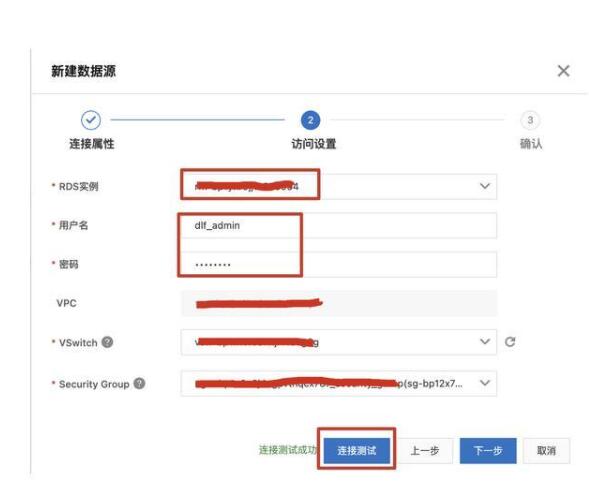
點(diǎn)擊下一步,確定,完成數(shù)據(jù)源創(chuàng)建。
2. 創(chuàng)建元數(shù)據(jù)庫(kù)
在 OSS 中新建 Bucket,databricks-data-source;
點(diǎn)擊左側(cè)菜單“元數(shù)據(jù)管理”->“元數(shù)據(jù)庫(kù)”,點(diǎn)擊“新建元數(shù)據(jù)庫(kù)”。填寫名稱,新建目錄 dlf/,并選擇。
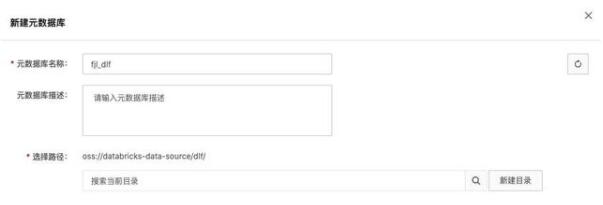
3. 創(chuàng)建入湖任務(wù)
點(diǎn)擊菜單“數(shù)據(jù)入湖”->“入湖任務(wù)管理”,點(diǎn)擊“新建入湖任務(wù)”。
選擇“關(guān)系數(shù)據(jù)庫(kù)實(shí)時(shí)入湖”,按照下圖的信息填寫數(shù)據(jù)源、目標(biāo)數(shù)據(jù)湖、任務(wù)配置等信息。并保存。
配置數(shù)據(jù)源,選擇剛才新建的“dlf”連接,使用表路徑 “dlf/engine_funcs”,選擇新建 dts 訂閱,填寫名稱。
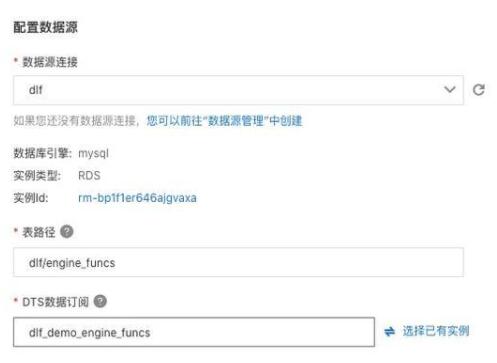
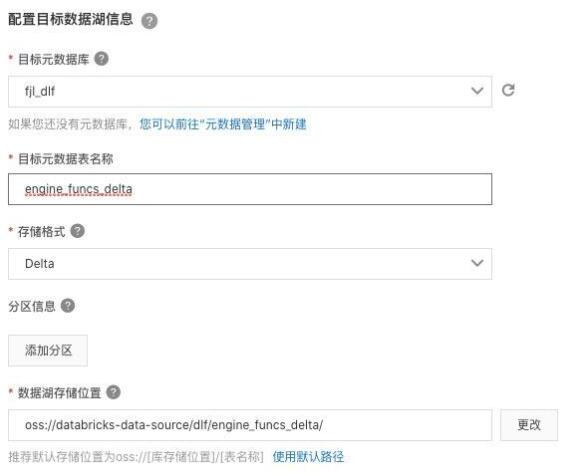

回到任務(wù)管理頁(yè)面,點(diǎn)擊“運(yùn)行”新建的入湖任務(wù)。就會(huì)看到任務(wù)進(jìn)入“初始化中”狀態(tài),隨后會(huì)進(jìn)入“運(yùn)行”狀態(tài)。
點(diǎn)擊“詳情”進(jìn)入任務(wù)詳情頁(yè),可以看到相應(yīng)的數(shù)據(jù)庫(kù)表信息。
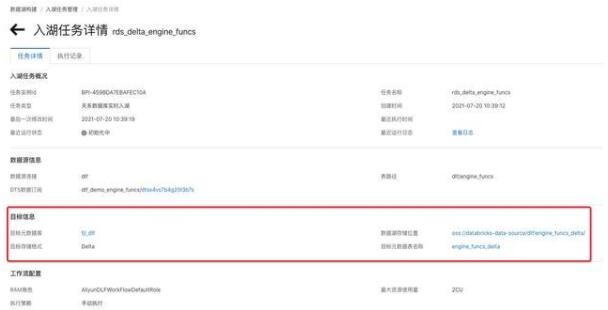
該數(shù)據(jù)入湖任務(wù),屬于全量+增量入湖,大約3至5分鐘后,全量數(shù)據(jù)會(huì)完成導(dǎo)入,隨后自動(dòng)進(jìn)入實(shí)時(shí)監(jiān)聽(tīng)狀態(tài)。如果有數(shù)據(jù)更新,則會(huì)自動(dòng)更新至 Delta Lake 數(shù)據(jù)中。
數(shù)據(jù)湖探索與分析
DLF 數(shù)據(jù)查詢探索
DLF 產(chǎn)品提供了輕量級(jí)的數(shù)據(jù)預(yù)覽和探索功能,點(diǎn)擊菜單“數(shù)據(jù)探索”->“SQL 查詢”進(jìn)入數(shù)據(jù)查詢頁(yè)面。
在元數(shù)據(jù)庫(kù)表中,找到“fjl_dlf”,展開(kāi)后可以看到 engine_funcs_delta 表已經(jīng)自動(dòng)創(chuàng)建完成。雙擊該表名稱,右側(cè) sql 編輯框會(huì)出現(xiàn)查詢?cè)摫淼?sql 語(yǔ)句,點(diǎn)擊“運(yùn)行”,即可獲得數(shù)據(jù)查詢結(jié)果。
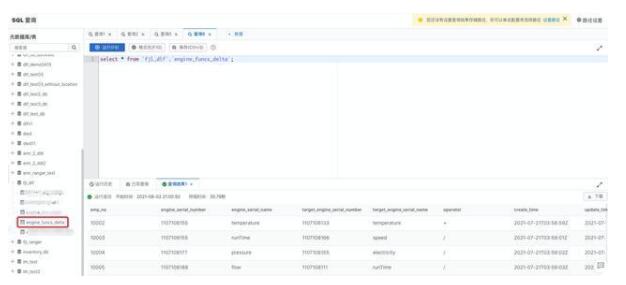
回到 DMS 控制臺(tái),運(yùn)行下方 DELETE 和 INSERT SQL 語(yǔ)句。
- DELETE FROM `engine_funcs` where `emp_no` = 10001;UPDATE `engine_funcs` SET `operator` = '+', `update_time` = NOW() WHERE `emp_no` =10002;INSERT INTO `engine_funcs` VALUES (20001,'1107108199','speed','1107108122','runTime','*', now(), now());
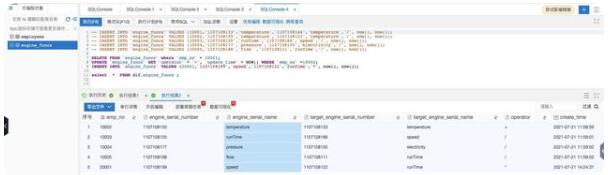
大約1至3分鐘后,在 DLF 數(shù)據(jù)探索再次執(zhí)行剛才的 select 語(yǔ)句,所有的數(shù)據(jù)更新已經(jīng)同步至數(shù)據(jù)湖中。
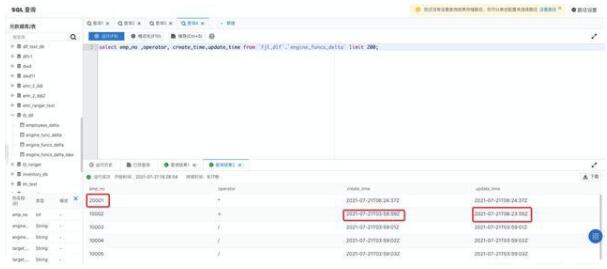
創(chuàng)建 Databricks 數(shù)據(jù)洞察(DDI)集群
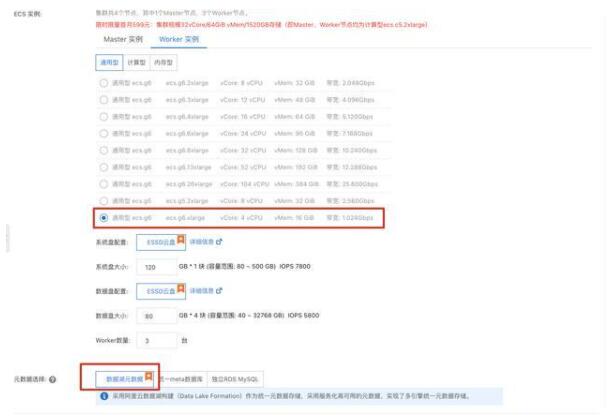
集群創(chuàng)建完成后,點(diǎn)擊“詳情”進(jìn)入詳情頁(yè),添加當(dāng)前訪問(wèn)機(jī)器 ip 白名單。
點(diǎn)擊 Notebook 進(jìn)入交互式分析頁(yè)查詢同步至 Delta Lake 中 engine_funcs_delta 表數(shù)據(jù)。

IoT 平臺(tái)采集到云 Kafka 數(shù)據(jù)實(shí)時(shí)寫入 Delta Lake
1.引入 spark-sql-kafka 三方依賴
- %spark.confspark.jars.packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.1
2.使用 UDF 函數(shù)定義流數(shù)據(jù)寫入 Delta Lake 的 Merge 規(guī)則
發(fā)往 Kafka 的測(cè)試數(shù)據(jù)的格式:
- {"sn": "1107108111","temperature": "12" ,"speed":"1115", "runTime":"160","pressure":"210","electricity":"380","flow":"740","dia":"330"}{"sn": "1107108122","temperature": "13" ,"speed":"1015", "runTime":"150","pressure":"220","electricity":"390","flow":"787","dia":"340"}{"sn": "1107108133","temperature": "14" ,"speed":"1215", "runTime":"140","pressure":"230","electricity":"377","flow":"777","dia":"345"}{"sn": "1107108144","temperature": "15" ,"speed":"1315", "runTime":"145","pressure":"240","electricity":"367","flow":"730","dia":"430"}{"sn": "1107108155","temperature": "16" ,"speed":"1415", "runTime":"155","pressure":"250","electricity":"383","flow":"750","dia":"345"}{"sn": "1107108166","temperature": "10" ,"speed":"1515", "runTime":"145","pressure":"260","electricity":"350","flow":"734","dia":"365"}{"sn": "1107108177","temperature": "12" ,"speed":"1115", "runTime":"160","pressure":"210","electricity":"377","flow":"733","dia":"330"}{"sn": "1107108188","temperature": "13" ,"speed":"1015", "runTime":"150","pressure":"220","electricity":"381","flow":"737","dia":"340"}{"sn": "1107108199","temperature": "14" ,"speed":"1215", "runTime":"140","pressure":"230","electricity":"378","flow":"747","dia":"345"}
- %sparkimport org.apache.spark.sql._import io.delta.tables._def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) { microBatchOutputDF.createOrReplaceTempView("dataStream") // 對(duì)流數(shù)據(jù)DF執(zhí)行列轉(zhuǎn)行的操作; val df=microBatchOutputDF.sparkSession.sql(s""" select `sn`, stack(7, 'temperature', `temperature`, 'speed', `speed`, 'runTime', `runTime`, 'pressure', `pressure`, 'electricity', `electricity`, 'flow', `flow` , 'dia', `dia`) as (`name`, `value` ) from dataStream """) df.createOrReplaceTempView("updates") // 實(shí)現(xiàn)實(shí)時(shí)更新動(dòng)態(tài)的數(shù)據(jù),結(jié)果merge到表里面 val mergedf=df.sparkSession.sql(s""" MERGE INTO delta_aggregates_metrics t USING updates s ON s.sn = t.sn and s.name=t.name WHEN MATCHED THEN UPDATE SET t.value = s.value, t.update_time=current_timestamp() WHEN NOT MATCHED THEN INSERT (t.sn,t.name,t.value ,t.create_time,t.update_time) values (s.sn,s.name,s.value,current_timestamp(),current_timestamp()) """)}
3.使用 Spark Structured Streaming 實(shí)時(shí)流寫入 Delta Lake
- %sparkimport org.apache.spark.sql.functions._import org.apache.spark.sql.streaming.Triggerdef getquery(checkpoint_dir:String,servers:String,topic:String ){ var streamingInputDF = spark.readStream .format("kafka") .option("kafka.bootstrap.servers", servers) .option("subscribe", topic) .option("startingOffsets", "latest") .option("minPartitions", "10") .option("failOnDataLoss", "true") .load()var streamingSelectDF = streamingInputDF .select( get_json_object(($"value").cast("string"), "$.sn").alias("sn"), get_json_object(($"value").cast("string"), "$.temperature").alias("temperature"), get_json_object(($"value").cast("string"), "$.speed").alias("speed"), get_json_object(($"value").cast("string"), "$.runTime").alias("runTime"), get_json_object(($"value").cast("string"), "$.electricity").alias("electricity"), get_json_object(($"value").cast("string"), "$.flow").alias("flow"), get_json_object(($"value").cast("string"), "$.dia").alias("dia"), get_json_object(($"value").cast("string"), "$.pressure").alias("pressure") )val query = streamingSelectDF .writeStream .format("delta") .option("checkpointLocation", checkpoint_dir) .trigger(Trigger.ProcessingTime("5 seconds")) // 執(zhí)行流處理時(shí)間間隔 .foreachBatch(upsertToDelta _) //引用upsertToDelta函數(shù) .outputMode("update") .start()}
4. 執(zhí)行程序
- %sparkval my_checkpoint_dir="oss://databricks-data-source/checkpoint/ck"val servers= "***.***.***.***:9092"val topic= "your-topic"getquery(my_checkpoint_dir,servers,topic)
5. 啟動(dòng) Kafka 并向生產(chǎn)里發(fā)送測(cè)試數(shù)據(jù)

查詢數(shù)據(jù)實(shí)時(shí)寫入并更新
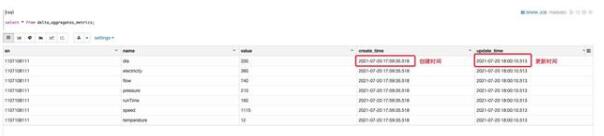
查詢從 MySQL 實(shí)時(shí)同步入湖的 engine_funcs_delta 數(shù)據(jù)
- %sparkval rds_dataV=spark.table("fjl_dlf.engine_funcs_delta")rds_dataV.show()

批處理作業(yè)
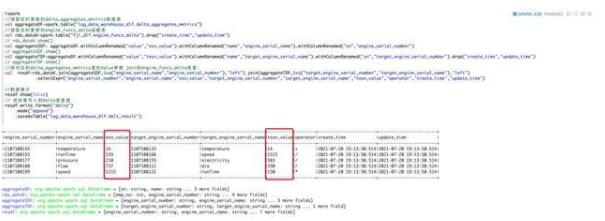
結(jié)合業(yè)務(wù),需要將對(duì)應(yīng)的 delta_aggregates_metrics 里的 Value 參數(shù) join 到engine_funcs_delta 表里
- %spark//讀取實(shí)時(shí)更新的delta_aggregates_metrics數(shù)據(jù)表val aggregateDF=spark.table("log_data_warehouse_dlf.delta_aggregates_metrics")//讀取實(shí)時(shí)更新的engine_funcs_delta函數(shù)表val rds_dataV=spark.table("fjl_dlf.engine_funcs_delta").drop("create_time","update_time")// rds_dataV.show()val aggregateSDF= aggregateDF.withColumnRenamed("value","esn_value").withColumnRenamed("name","engine_serial_name").withColumnRenamed("sn","engine_serial_number")// aggregateSDF.show()val aggregateTDF=aggregateDF.withColumnRenamed("value","tesn_value").withColumnRenamed("name","target_engine_serial_name").withColumnRenamed("sn","target_engine_serial_number").drop("create_time","update_time")// aggregateTDF.show()//將對(duì)應(yīng)的delta_aggregates_metrics里的Value參數(shù) join到engine_funcs_delta表里;val resdf=rds_dataV.join(aggregateSDF,Seq("engine_serial_name","engine_serial_number"),"left").join(aggregateTDF,Seq("target_engine_serial_number","target_engine_serial_name"),"left") .selectExpr("engine_serial_number","engine_serial_name","esn_value","target_engine_serial_number","target_engine_serial_name","tesn_value","operator","create_time","update_time")//數(shù)據(jù)展示resdf.show(false)// 將結(jié)果寫入到Delta表里面resdf.write.format("delta") .mode("append") .saveAsTable("log_data_warehouse_dlf.delta_result")
性能優(yōu)化:OPTIMIZE & Z-Ordering
在流處理場(chǎng)景下會(huì)產(chǎn)生大量的小文件,大量小文件的存在會(huì)嚴(yán)重影響數(shù)據(jù)系統(tǒng)的讀性能。Delta Lake 提供了 OPTIMIZE 命令,可以將小文件進(jìn)行合并壓縮,另外,針對(duì) Ad-Hoc 查詢場(chǎng)景,由于涉及對(duì)單表多個(gè)維度數(shù)據(jù)的查詢,我們借助 Delta Lake 提供的 Z-Ordering 機(jī)制,可以有效提升查詢的性能。從而極大提升讀取表的性能。DeltaLake 本身提供了 Auto Optimize 選項(xiàng),但是會(huì)犧牲少量寫性能,增加數(shù)據(jù)寫入 delta 表的延遲。相反,執(zhí)行 OPTIMIZE 命令并不會(huì)影響寫的性能,因?yàn)?Delta Lake 本身支持 MVCC,支持 OPTIMIZE 的同時(shí)并發(fā)執(zhí)行寫操作。因此,我們采用定期觸發(fā)執(zhí)行 OPTIMIZE 的方案,每小時(shí)通過(guò) OPTIMIZE 做一次合并小文件操作,同時(shí)執(zhí)行 VACCUM 來(lái)清理過(guò)期數(shù)據(jù)文件:
- OPTIMIZE log_data_warehouse_dlf.delta_result ZORDER by engine_serial_number;VACUUM log_data_warehouse_dlf.delta_result RETAIN 1 HOURS;