













淺談數據治理中的智能數據目錄
在數字化轉型的戰略實施中,很多企業都在搭建自己的業務、數據及人工智能的中臺。在同這些企業合作和交流中,越來越體會到數據目錄是中臺建設的核心和基礎。為了更好地提供數據服務,發揮數據價值,用戶需要先理解數據和信任數據。 企業擁有什么樣的數據,這些數據在哪里,這些數據之間的關系及沿襲,數據是好是壞,這些都是數據目錄需要回答的問題。
企業的數據環境具有復雜和多樣性,數據分散在成百上千的本地和云端系統之中,其中包括傳統的事務性數據庫、大數據平臺或者數據湖、基于云的市場營銷等系統,還有不斷涌現的新數據源和應用。人工智能和機器學習可使數據目錄 “智能化”,使其具備自動發現,自動數據分類,自動分析和關聯的能力,不斷滿足企業數據管理在處理規模、效率、創新和洞察力等方面的需求。
IBM很早就認識到將機器學習應用到數據管理的重要性,在IBM的Cloud Pak for Data中,機器學習無處不在,遍布數據集成、自動化數據管理、多云數據整合、數據準備、建議和數據洞察,其中Watson Knowledge Catalog致力于改進企業中數據管理者和數據使用者之間的數據流的通信、集成和自動化,被評為機器學習數據目錄領導者。
1. 自動數據發現,快速構建數據目錄
應對企業復雜和多樣的數據環境,智能的數據目錄可以自動快速地發現數據并進行識別,包括數據的輪廓,數據的業務含義,數據的分類,數據的質量,數據集之間的關系,是否有隱私或者敏感的數據,能快速地創建數據目錄,高效地提供數據準備。
2. 關聯數據資產,完整知識圖譜
企業的各種信息,不是孤立的個體,之間存在各種的關系,例如業務分類同業務術語,業務術語同技術資產,業務規則同技術規則及數據資產,數據分類同數據資產,數據資產同數據管家等的關系。對于需要理解數據的用戶,希望從任一個關注點出發,獲取到與其相關的業務上、技術上、管理上等維度的關聯的資產信息。
智能的數據目錄,先將企業中存在于系統、流程和集體知識中的各類信息集合在一起,分析并關聯,將企業的各類數據資產以關系圖的形式展開,對于每個用戶,可以從中截取自己關注的片段,并可以隨信息的拓展而繼續探索和發現新的知識,從而更好地理解數據,豐富自己的數據知識體系。
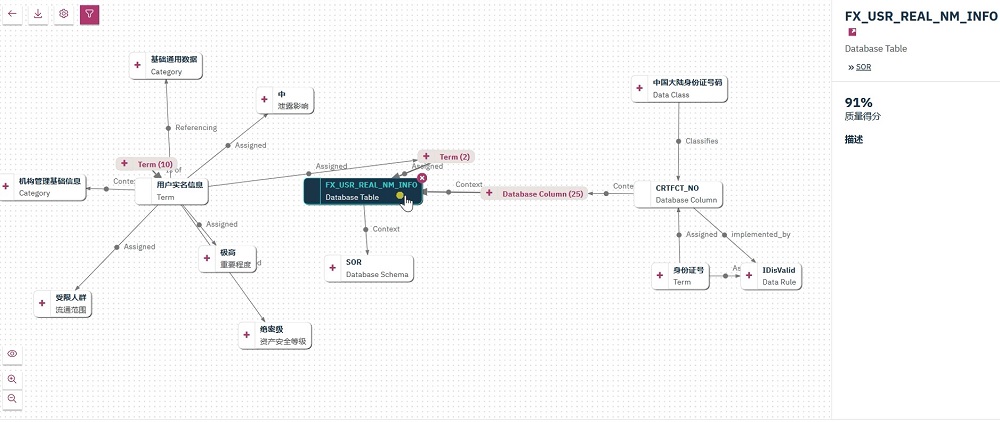
3. 自動數據校驗,提升數據質量
在理解數據后,若要使用數據,需要進一步信任數據。數據質量是數據信任的基石,需提供細粒度的量化的數據質量監管和變化追蹤,除了內置多種數據質量維度,自動進行數據質量打分外,還需要提供根據數據分類、業務特征、重要性等特定屬性自動進行相關的數據規則校驗,而不需要考慮數據的來源,大大提高數據管理的效率和范圍。
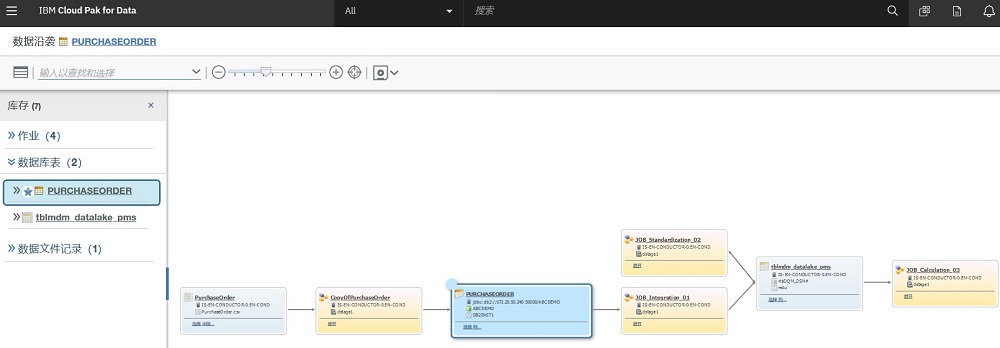
4. 自動分析數據沿襲
用戶需要對其數據細致了解,才能對數據更加自信和篤定,才能支撐分析和數據科學。
智能的數據目錄能支撐從大量數據源中提取粗粒度—系統和系統之間的,數據集和和數據集合之間沿襲;同時支持細粒度—表和表之間,字段和字段之間的沿襲關系。
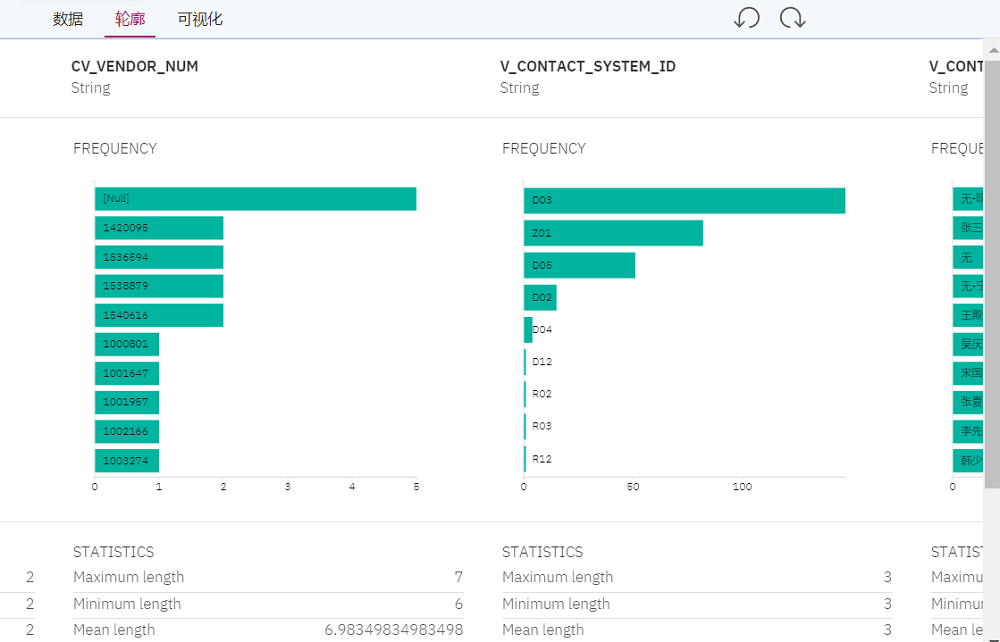
5. 智能搜索
無論是業務用戶或者技術用戶,無論數據處于企業什么位置,或者搜索時候輸入模糊或者近似的信息,用戶都能搜索到相應的結果,及大量相關聯的信息。這些搜索結果會按照信息相關性從高到底給出。用戶還可以在圖形化的搜索對象上進行深入的展開和探查。對于搜索到的數據資產,用戶可以預覽數據,了解數據輪廓,進行數據可視化查看,為后續的數據分析和建模準備數據。
智能的數據目錄,幫助用戶揭示復雜的數據關系,高效創建可信賴的分析基礎平臺,從數據采集、數據治理到數據自助服務,提供端到端的一站式平臺服務。
詳情請訪問IBM官網頁面了解更多內容:https://www.ibm.com/cloud/watson-knowledge-catalog
了解更多IBM相關:http://cloud.51cto.com/act/ibm2021q3/cloud#p3
任何問題請撥打免費咨詢熱線:4006690260 (工作日9:00-17:00)























