自動檢索、修復Python代碼bug,微軟推出DeepDebug
還在為不斷的 debug 代碼煩惱嗎?
本地化 Bug 并修復程序是軟件開發過程中的重要任務。在本篇論文中,來自微軟 Cloud+AI 部門的研究者介紹了 DeepDebug,一種使用大型預訓練模型 transformer 進行自動 debug 的方法。
首先,研究者基于 20 萬個庫中的函數訓練了反向翻譯模型。接下來,他們將注意力轉向可以對其執行測試的 1 萬個庫,并在這些已經通過測試的庫中創建所有函數的 buggy 版本。這些豐富的調試信息,例如棧追蹤和打印語句,可以用于微調已在原始源代碼上預訓練的模型。最后,研究者通過將上下文窗口擴展到 buggy 函數本身外,并按優先級順序添加一個由該函數的父類、導入、簽名、文檔字符串、方法主體組成的框架,從而增強了所有模型。
在 QuixBugs 基準上,研究者將 bug 的修補總數增加了 50%以上,同時將誤報率從 35%降至 5%,并將超時(timeout)從 6 小時減少到 1 分鐘。根據微軟自己的可執行測試基準,此模型在不使用跟蹤的情況下首次修復了 68%的 bug;而在添加跟蹤之后,第一次嘗試即可修復 75%的錯誤。為評估可執行的測試,作者接下來還將開源框架和驗證集。

論文鏈接:https://arxiv.org/pdf/2105.09352.pdf
引言
自動程序修復中的主要范例是「生成和驗證」方法。研究者遵循該方法,假設存在可以識別 bug 存在的一組測試函數,然后本地化 bug 并考慮候選的修補程序,直到找到滿足測試的補丁程序為止。
在整個實驗過程中,研究者使用了錯誤已被本地化為單個 buggy 方法的合成 bug,將其與其他上下文(例如函數文件中的上下文以及暴露 buggy 函數的棧追蹤)作為輸入,并將該輸入提供給嘗試生成修復好的函數的序列到序列 transformer。
研究者在部署方案中還嘗試使用了棧追蹤來本地化 bug。目前,研究者基于來自開發人員自己的代碼行的棧追蹤來應用一種簡單的啟發法,因為最近調用的行是最可疑的。在未來,作者還有興趣使用可以對給定棧追蹤的方法進行重新排序的編碼器 transformer 來改進啟發法。
如下圖所示,利用了經過廣泛預訓練的 transformer,研究者使用了用于微調 PyMT5 的相同的 DeepDev-py 序列到序列模型。他們首先使用 commit 數據來訓練基線 bug 修補程序模型和 bug 創建模型。Bug 創建(bug-creator)模型向 DeepDebug(反向翻譯)提供的數據量是原來的 20 倍。最后,研究者針對具有可執行測試并產生追蹤的函數中的神經錯誤微調了此模型,從而獲得其最終的 DeepDebug(追蹤)。
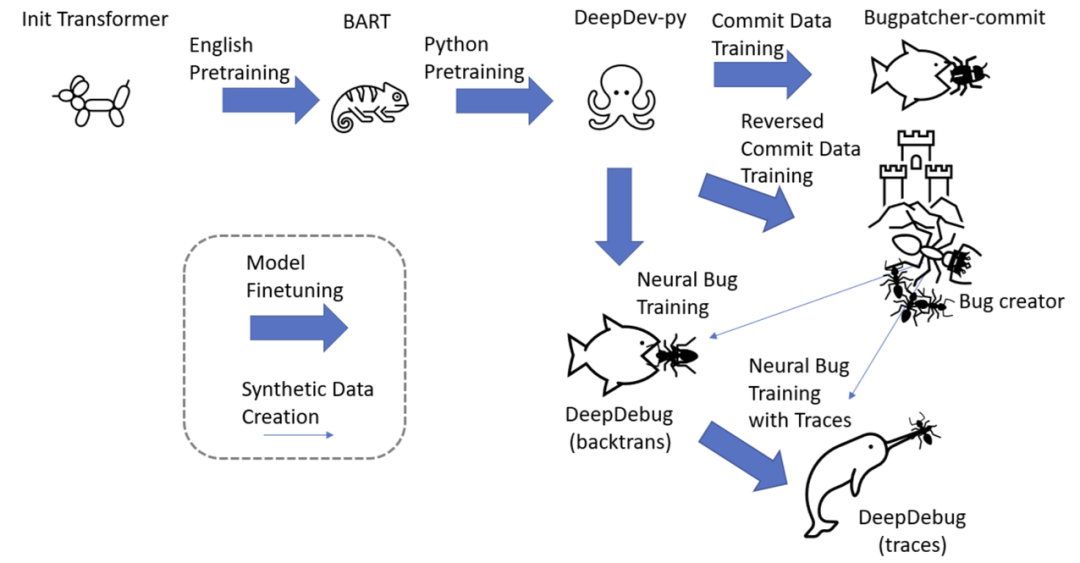
訓練 pipeline。
模型
研究者重復使用了具有 12 個編碼器層和 12 個解碼器層的 4.06 億參數的序列到序列 transformer。在實驗棧追蹤時,他們為代碼框架分配了 1024 個 token,為追蹤分配多達 896 個 token,并且為了適應這個規模更大的上下文,還需要擴展 transformer 的位置嵌入矩陣。為此,研究者受 reformer 的啟發使用了軸向嵌入,復制了已有 1024 個位置嵌入中的前 896 個,生成一個隨機的軸向向量,并將該向量添加到所有 896 個重復嵌入中。在初步實驗中,此方法的性能優于隨機初始化的嵌入。
數據
研究者使用四個不同的訓練數據集:
- 用于預訓練的原始 python 代碼;
- 用于訓練神經 bug 創建和 bug 修補程序的 commit 數據;
- 從原始代碼中提取的方法,其中插入了神經 bug 以訓練更強大的 bug 修補程序;
- 通過可執行測試的方法。
對于最后一個數據集,研究者還獲得了每個測試執行的行列表,并通過再次插入合成 bug 并重新運行通過測試來獲得另一個 bug 補丁程序數據集,使得他們可以在棧追蹤、錯誤消息、打印語句上對 bug 補丁程序進行微調。研究者還實驗了為 bug 修補程序模型提供焦點 buggy 方法或整個文件的「骨架」(skeleton),以優先考慮數據(例如函數簽名)的優先級。
預訓練
在 DeepDev transformer 平臺上,研究者重用了 FaceBook 的 BART 模型熱啟動的 4.06 億參數的 DeepDev Python transformer,然后使用 Spanmasking objective 對其進行了預訓練。預訓練數據由 20 萬個五星公共 Python 庫組成,在 DGX-2 盒子上進行了為期三周的預訓練。DeepDev 的 token 生成器附加了空白 token,例如四空間和八空間 token,提高了吞吐量和有效上下文長度。為了最大程度地減少泄漏的風險,研究者始終將驗證和測試庫限制在同一范圍內,尤其是 CodeSearchNet 中使用的庫。
commit 的數據
研究者遍歷了 10 萬個被過濾為至少 10 星 Python 庫的 commit 歷史記錄,并進一步過濾所有消息中包含「修復」一詞的 commit,大約占所有 commit 的五分之一。基于對示例的檢查,研究者發現了這個簡單過濾器的精確度似乎與使用「補丁 bug」或「修復錯誤」之類語句的限制性過濾器差不多。但是,數據仍然非常嘈雜。
commit 的數據使研究者做到了以下兩點:首先,允許他們訓練一個偏向于建設性的、bug 修復的編輯模型,讓研究人員可以直接在 bug 修復中評估這種模型,或者在過濾更進一層的 bug 數據上對其進行微調。其次,研究者可以反轉輸入和輸出,并訓練偏向于破壞性的、引發 bug 的編輯模型。研究人員可以使用此模型來創建神經 bug,以大幅度增強訓練數據。這種反向翻譯方法已經在 NLP 中被證明是有用的。
合成 bug
由于研究者對通過合成 bug 進行數據擴充感興趣,所以使用了 GitHub 上的大量無 bug 代碼。與僅使用從 bug 修復提交中提取的函數相比,這樣做有可能使目標方法的數據集擴展二十倍。此外,研究者通過為每種方法創建多個 buggy 版本來任意地擴大規模。在本篇論文中,他們將規模限制為來自 1 萬個庫中的 130 萬個函數(與提交數據幾乎相等),并通過反向翻譯擴展到了 1800 萬個 bug 修復。
研究者觀察到了模型注入了以下幾類錯誤:
- 將點訪問器替換為方括號訪問器;
- 將截斷鏈接的函數調用;
- 刪除返回行;
- 將返回值封裝在元組和字典等對象中然后忘記封裝對象;
- 將 IndexError 等精確錯誤替換為 ValueError 等不同的錯誤;
- 誤命名變量諸如 self.result 而不是 self._result;
- 錯誤地按引用復制而不是按值復制。研究者幾乎應用了以前文獻中已報道的所有啟發式 bug。
「啟發式 bug」一詞被用來指代使用簡單規則手動創建的合成 bug,例如在函數調用中刪除一行或交換兩個參數、替換二進制運算符(使用!= 代替 ==)、使用錯誤變量、忘記『self.』訪問器或者刪除代碼。

「神經 bug」一詞被用來指代使用神經編輯模型創建的合成 bug,例如訓練來還原 bug 修復提交的 bug。使用神經 bug 進行數據增強具有許多吸引人的功能。靈活的神經模型幾乎可以任意生成從開發人員實際犯錯的分布中得出的編輯。例如,神經編輯模型可以將 get_key 與 get_value 交換,而簡單的啟發法可能會進行隨機交換,比如從 get_key 切換到 reverse_list。而且,這種方法幾乎與語言無關,因為研究者可以重用框架來進行挖掘提交,并且只需要一個解析器就可以提取類和方法,以及組成代碼框架所需的部分。
上表所示是在測試集用于訓練兩個 transformer 的交叉熵損失,一個用于提交數據,另一個用于反向提交。在有和沒有代碼框架的情況下,在向前和向后編輯中對這兩個模型進行評估。由于編輯任務相對容易,因此交叉熵損失比通常報告的生成 Python 代碼的效果提升五倍。此外,反向編輯的損失比正向編輯的損失低三分之一。正向模型在正向編輯時比反向模型好 6%,反向模型在反向編輯時反過來又好 6%。與僅使用聚焦方法相比,使用框架的兩種模型的性能都高出 2%。

如上圖所示,bug 創建模型將 kwargs.pop 替換為了 kwargs.get、將. startwith(self.name) 替換為了 ==self.name、并刪除了 break。
可執行測試的方法
實際上,有很多機會可以調試可以實際執行的代碼,尤其是在有附帶測試驗證執行正確的情況下。典型的調試會話包括在棧追蹤的幫助下查找可疑的代碼塊、在近似二進制搜索中插入打印語句和斷點、修改并執行代碼片段、在 StackOverflow 中搜索錯誤消息的解釋以及 API 使用示例。相比之下,基線神經模型是機會更少的,在每次寫入一個 token 之前,只能盯著一段代碼幾秒鐘。
而由可執行測試啟用的「生成并驗證」方法可以有多次機會提高性能。例如,在短 Java 方法領域,研究者見證了 top-20 精度是 top-1 精度的三倍。盡管先前的工作已經表明這些編輯可能會過擬合,真正的隨機編輯仍能確保足夠多的嘗試次數以通過測試組。
研究者主要運用的方法有三種:
- 追蹤法:除了使用測試對不正確的編輯進行分類之外,還以三種不同的方式將來自測試的信息整合到訓練中:將錯誤消息附加到 buggy 方法中,另外附加了棧追蹤,并進一步使用測試框架 Pytest 提供了故障處的所有局部變量值;
- 收集通過測試法:為了以訓練規模收集可執行的測試,從用于預訓練的 20 萬個庫開始,過濾到包含測試和 setup.py 或 requirements.txt 文件的 3.5 萬個庫。對于這些庫中的每一個,都在唯一的容器中執行 Pytest,最終從 1 萬個庫中收集通過的測試;
- 合成 bug 測試法:在過濾通過可執行測試的函數并插入神經 bug 之后,重新運行測試以收集 Pytest 追蹤,并濾除仍通過測試并因此實際上不是 buggy 的已編輯函數。
實驗及結果
研究者對訓練反向翻譯數據、添加框架以及添加 Pytest 棧追蹤進行了實驗,并得到了如下結果。
反向翻譯數據
在首個實驗中,研究者比較了通過前向提交數據進行的訓練與通過反向翻譯產生的合成 bug 進行的訓練,并對保留數據上使用交叉熵進行評估。如下表所示,比起前向提交數據,DeepDebug(反向翻譯)的損失降低了 10%。令人驚訝的是,反向翻譯模型實際上在反向提交數據上的表現較差。

總體而言,DeepDebug 比以前的技術要強大得多。QuixBugs 挑戰是帶有小合成 bug 且 Python 和 Java 版本幾乎相同的 40 個經典算法的基準,最初的 QuixBugs 挑戰是讓開發人員在一分鐘的時間內修復盡可能多的 bug。下表報告了模型挑戰 QuixBugs 的結果。

研究者將模型限制為通過隨機采樣生成 100 個補丁,這大約是在一分鐘跨度內可以生成和評估的數量。隨后將現有的 bug 數量提高了 50%以上,同時將誤報率從 35%降低到了 5%。值得注意的是,由于此任務的復雜性較低,因此所有的模型都會生成許多重復的編輯,這表明在采樣上仍有改進空間。鑒于先前模型的超時以及額外信息提供,這些結果更加令人印象深刻。例如,CoCoNuT 被明確告知哪一行包含該 bug,并被允許六個小時來找到補丁;五個非神經工具找到了 122 個補丁程序,用于最長的遞增子序列算法,還進行了數千次的嘗試。
添加框架
在第二個實驗中,研究者比較了僅使用焦點函數作為輸入以及使用整個框架作為輸入的訓練和評估。如下表所示,當對神經 bug 進行評估時,使用框架時,神經 bug 補丁損失減少了 25%。而實際上,當對提交數據使用框架時,神經 bug 補丁的表現更差,因為提交通常會編輯多個函數。

Pytest 棧追蹤
在第三個實驗中,研究者將 Pytest 棧追蹤附加到 buggy 輸入中,使用軸向嵌入來擴展上下文窗口,以適應其他的 token。在計劃進行開源的驗證集中篩選了 100 個庫中的 523 個神經 bug 的基準。他們觀察到了令人印象深刻的表現,與交叉熵結果相反,使用追蹤大大提高了性能。如下表所示,DeepDebug(反向翻譯)的前 10 個修補程序成功率為 90%,而 DeepDebug(追蹤)的前 10 個修補程序成功率為 97%。