如何使用 JavaScript 解析 URL?
如果你從事 Web 前端開發(fā)有一段時間了,相信一定會遇到需要使用 JavaScript 解析 URL 地址信息的時候。本文就介紹一下如何使用 JavaScript 解析 URL。
在《認(rèn)識 URI 與 URL》一文中具體介紹了 URI 的格式,要使用 JavaScript 解析 URL 信息,必須先了解 URL 格式是怎樣的,讓我們先來回顧一下吧。
URL 格式
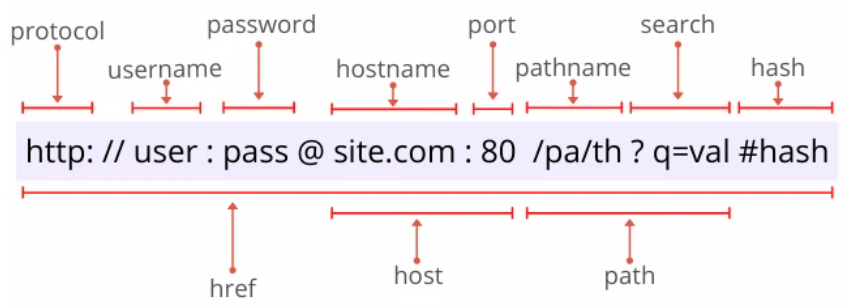
完整的 URL 信息包括以下幾點:
- 協(xié)議(protocol):采用的協(xié)議方案;
- 登錄信息(username & password):(可選項)指定用戶名和密碼,用來從服務(wù)器獲取資源時的認(rèn)證信息;
- 服務(wù)器地址(hostname):待訪問的服務(wù)器地址。可以是域名形式也可以是 IP 地址;
- 服務(wù)器端口號(port):;指定服務(wù)器連接網(wǎng)路的端口號;
- 帶層次的文件路徑(pathname):指定服務(wù)器上的文件路徑來定位特指的資源;
- 查詢字符串(search):(可選項)查詢字符串參數(shù);
- 片段標(biāo)識符(hash):(可選項)用來標(biāo)記已獲取資源中的子資源;
解析 URL
在回顧了 URL 都包括哪些信息后,現(xiàn)在就先按照前文的 URL 格式人工解析一下 URL 的信息。以本文地址地址為例:
- http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/
按照 URL 的格式規(guī)范,本文的 URL 地址解析后的信息應(yīng)該如下:
- protocol: http;
- hostname: www.yaohaixiao.com;
- pathname: /blog/how-to-parse-url-with-javascript/;
可以看到,本文地址的 URL 解析后的信息并沒有前文提到的完整 URL 信息中那么多。這是因為 URL 信息中有幾項信息是可選項信息,本文的示例 URL 地址中都是沒有值的。
在通過人工分析的方式分析了一遍,現(xiàn)在就要開始使用 JavaScript 編程解析 URL 信息了。當(dāng)然,解析 URL 信息的方法很多,本文主要介紹兩種解析方法:正則表達(dá)式解析 和 URL 構(gòu)造函數(shù)解析。
正則表達(dá)式解析
使用 JavaScript 中的正則表達(dá)解析 URL 信息應(yīng)該最常見的方法了,當(dāng)然這需要具備一定的 JavaScript 正則表達(dá)式相關(guān)的知識。而使用正則表達(dá)式分析 URL 地址其實也并不復(fù)雜。
按照前文圖片中的 URL 信息的結(jié)構(gòu),使用括號“()”分組表達(dá)符對 URL 中對應(yīng)的信息進(jìn)行分組,正則表達(dá)式的偽代碼大致如下:
- /^((protocol):)?\/\/((username):(password)@)?(hostname)(:(port))?(pathname)(\\?(search))?(#(hash))?/
可以看到,正則表達(dá)式也分了 7 組:
- protocol – 協(xié)議分組:((protocol):)?,最外層的 ()? 中,? 表示數(shù)量為 0 或 1 個,即表示協(xié)議名稱是可選的;
- auth – 授權(quán)信息分組:((username):(password)@)?,與協(xié)議分組一樣,整個授權(quán)分組也是可選的。其中又包含 username 子分組和 password 子分組;
- hostname – 服務(wù)器地址分組:(hostname),表示 hostname 信息是必選的;
- port – 端口分組:(:(port))?,表示端口號是可選的;
- pathname – 帶層次的文件路徑分組:(pathname),表示文件路徑是必選的;
- search – 查詢字符串分組:(\\?(search))?,表示查詢字符串是可選的;
- hash – 片段標(biāo)識符分組:(#(hash))?,表示片段標(biāo)識符分組也是可選的;
完成了大的分組后,接下來要處理的問題就是相對比較容易了,就是用真實的正則表達(dá)式將使用英文字母的偽代碼內(nèi)容替換掉。對應(yīng)完整的 JavaScript 的正則表達(dá)式代碼如下圖:

可以看到,圖中藍(lán)色文字標(biāo)識的是偽代碼中對應(yīng)的 7 個分組,而灰色文字標(biāo)識的是最終需要獲取的 URL 對應(yīng)的信息。下面就詳細(xì)介紹一下各個分組的正則表達(dá)式的含義。
1. protocol(協(xié)議分組)
- // ((protocol):)?
- (([^:/?#]+):)?
([^:/?#]+),匹配協(xié)議名稱(子分組),具體的含義如下:
- [^],表示除了“^”符號后的字符以外的所有字符。 [^:/?#] 就表示除了”:”(冒號)、”/”(反斜杠)、“?”(問號)和“#”(井號)以外的所有字符。也就是是說,協(xié)議名稱可是除了以上符號以外的所有字符都可以。我這個匹配比較寬泛,通常協(xié)議名稱是字母,所以也可以寫作([a-zA-Z])。除非確定邀請非常高的匹配精度,可以適當(dāng)寫寬泛一些;
- []+,中括號后的 + 表示數(shù)量為 1~n 個,所以 ([^:/?#]+) 整個的意思是協(xié)議名稱匹配為除了”:”(冒號)、“?”(問號)和“#”(井號)以外的所有字符字符都可以,并且長度要求是1個以上;
(([^:/?#]+):)?,匹配協(xié)議名稱加“:”格式,例如:http: 。當(dāng)然,在介紹分組偽代碼的時候,介紹過了,()? 括號后的 ? 標(biāo)識整個協(xié)議分組是可選的。而之所以將協(xié)議分組作為可選的,是應(yīng)為實際的應(yīng)用中:
//www.yaohaixiao.com/favicon.ico,這種不帶協(xié)議名稱的 URL 地址也是允許的。
因此,(([^:/?#]+):)? 這段表達(dá)式將匹配 2 組數(shù)據(jù):http: 和 http,前者是大分組 ()? 匹配的信息,后者則是子分組 ([^:/?#]+) 匹配的信息,也是真正希望解析的 URL 協(xié)議信息。不過由于整個協(xié)議分組是可選的,因此協(xié)議分組的兩個分組也可能都匹配不到數(shù)據(jù)。
2. auth(授權(quán)信息分組)
- // ((username):(password)@)?
- (([^/?#]+):(.+)@)?
([^/?#]+),匹配用戶名,由于規(guī)則和匹配協(xié)議名稱一樣,在此就不重復(fù)了。
(.+),匹配密碼。具體含義如下:
- “.”,表示任何字符。因為密碼由于考慮安全因數(shù),一般都希望密碼是包含字符(而且包含大小寫),數(shù)組和特殊字符的組合。所以直接不做任何限制,允許密碼包含任意字符。
- “+”,表示數(shù)量為1個或者多個,即密碼不能為空。
(([^/?#]+):(.+)@)?,匹配完整的授權(quán)信息。匹配的數(shù)據(jù)如:yao:Yao1!@。與授權(quán)信息一樣,最外層的()?表示授權(quán)信息也是可選的。
因此,(([^/?#]+):(.+)@)? 整個會匹配 3 組數(shù)據(jù):完整的用戶授權(quán)分組信息、用戶名以及密碼。由于整個協(xié)議分組是可選的,因此授權(quán)分組的 3 組信息也可能都匹配不到數(shù)據(jù)。
3. hostname(服務(wù)器地址分組)
- // (hostname)
- ([^/?#:]*)
([^/?#:]*),匹配服務(wù)器地址信息。和協(xié)議分組的表達(dá)式一樣,使用了比較寬松的匹配邏輯。
4. port(端口分組)
- // (:(port))?
- (:(\d+))?
(\d+),匹配端口號信息。端口號只能是數(shù)字類型的數(shù)據(jù),對端口號長度的要求是至少有一個。對端口號的長途匹配也沒有使用太嚴(yán)苛的長度要求。雖然通常端口號的長度一般是 2 位數(shù)字起,但還是建議遵循之前提到的建議,如果不是有具體的精度要求,表達(dá)式都可以使用寬泛一些的匹配規(guī)則。
(:(\d+))?,匹配完整的端口號分組信息。匹配的格式如:“:80”。
同樣的,整個端口號分組匹配的表達(dá)式也是可以匹配 2 組數(shù)據(jù)::80 和 80。當(dāng)然,端口號分組也是可選的,很大可能配備不到信息。
5. pathname(帶層次的文件路徑分組)
- // (pathname)
- ([^?#]*)
([^?#]*),匹配帶層次的文件路徑信息。具體的含義是:
- [^?#],除了“?”(問號)和“#”(井號)以外的所有字符都可以作為路徑信息。
- []*,表示字符長度可以是任意長度。因為 URL 地址可以是這樣的:http://www.yaohaixiao.com。
雖然沒有使用“()?”的形式表示路徑為可選的,但用于路徑的長度可以為 0,其實路徑也是可選的,也有可能匹配不到數(shù)據(jù)。
6. search(查詢字符串分組)
- // (\\?(search))?
- (\\?([^#]*))?
([^#]*),匹配查詢字符串信息。除了“#”(井號)以外的所有字符都可以作為查詢字符串信息。[]* 表示可選,因為路徑:http://www.yaohxiao.com? 也是允許的。
(\\?([^#]*))?,匹配查詢字符串的分組信息。匹配的格式如:?id=23。當(dāng)然也是可選的。
整個查詢字符串分組的表達(dá)式(\\?([^#]*))? ,也是可以匹配出 2 組數(shù)據(jù)。而因為整個分組是可選的,所以查詢字符串的分組匹配也很可能匹配不到數(shù)據(jù)。
7. hash(片段標(biāo)識符分組)
- // (#(hash))?
- (#(.*))?
(.*),匹配片段標(biāo)識。“.”表示任意字符,“*”表示任意長度。即片段表示可以是任意字符,且長度為任意長度的。
(#(.*))?,匹配判斷標(biāo)識分組。匹配的格式如:#1234。看到()?,就知道片段標(biāo)識符分組是可選的。
整個片段標(biāo)識符分組的表達(dá)式(#(.*))? ,也可以匹配出 2 組數(shù)據(jù)。當(dāng)然,也可能什么也匹配不上。
介紹完所有的分組表達(dá)式,最后來統(tǒng)計一下最多一共可以匹配多少組數(shù)據(jù):2 + 3 + 1 + 2 + 1 + 2 + 2 + 1 = 14。其中,最后一個加1,是匹配的整個 URL 地址。
驗證一下使用正則表達(dá)式對本文 URL 地址的匹配信息:
- const URL = 'http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/'
- const pattern = /^(([^:/?#]+):)?\/\/(([^/?#]+):(.+)@)?([^/?#:]*)(:(\d+))?([^?#]*)(\\?([^#]*))?(#(.*))?/
- const matches = URL.match(pattern)
- console.log(matches)
輸出的結(jié)果為:
- 0: "http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/"
- 1: "http:"
- 2: "http"
- 3: undefined
- 4: undefined
- 5: undefined
- 6: "www.yaohaixiao.com"
- 7: undefined
- 8: undefined
- 9: "/blog/how-to-parse-url-with-javascript/"
- 10: undefined
- 11: undefined
- 12: undefined
- 13: undefined
- groups: undefined
- index: 0
- input: "http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/"
正如之前人工分析的一樣,使用 match() 方法匹配了 14 個結(jié)果。由于示例 URL 地址中很多可選的信息都是沒有的,所以匹配結(jié)果為 undefined。但這個結(jié)果并不是那么一目了然,讓我們看看完整的 parseURL() 方法。
完整的 parseURL() 方法
完整的 parseURL() 方法的如下:
- /**
- * 分析 url 地址,將解析的結(jié)果作為對象返回,返回屬性有:
- * 1. href - 完整 URL 地址
- * 2. protocol - 協(xié)議
- * 3. username - 用戶名
- * 4. password - 密碼
- * 5. host - 域名地址
- * 6. hostname - 域名名稱
- * 7. port - 端口號
- * 8. path - 路徑
- * 9. pathname - 路徑名
- * 10. search - 查詢參數(shù)
- * 11. hash - 哈希值
- * 12. origin
- * 13. searchParams
- * ====================================================
- * @param {String} url - URL地址
- * @param {String} [base] - 基準(zhǔn) URL 地址
- * @returns {Object}
- */
- const parseURLWithRegExp = (url = location.href, base) => {
- const pattern = /^(([^:/?#]+):)?\/\/(([^/?#]+):(.+)@)?([^/?#:]*)(:(\d+))?([^?#]*)(\\?([^#]*))?(#(.*))?/
- const getURLSearchParams = (url) => {
- return (url.match(/([^?=&]+)(=([^&]*))/g) || []).reduce((a, v) => {
- return ((a[v.slice(0, v.indexOf('='))] = v.slice(v.indexOf('=') + 1)), a)
- }, {})
- }
- let matches,
- hostname,
- port,
- pathname,
- search,
- searchParams
- // url 是為度路徑時,忽略 base
- if (/^(([^:/?#]+):)/.test(url)) {
- base = ''
- }
- // 設(shè)置了基準(zhǔn) URL
- if (base) {
- // 移除 base 最后的斜杠 ‘/’
- if (/[/]$/.test(base)) {
- base = base.replace(/[/]$/, '')
- }
- // 確保 url 開始有斜杠
- if (!/^[/]/.test(url)) {
- url = '/' + url
- }
- // 保證 URL 地址拼接后是一個正確的格式
- url = base + url
- }
- matches = url.match(pattern)
- hostname = matches[6]
- port = matches[8] || ''
- pathname = matches[11] || '/'
- search = matches[10] || ''
- searchParams = (() => {
- const params = getURLSearchParams(url)
- return {
- get (name) {
- return params[name] || ''
- }
- }
- })()
- return {
- href: url,
- origin: (matches[1] ? matches[1] + '//' : '') + hostname,
- protocol: matches[2] || '',
- username: matches[4] || '',
- password: matches[5] || '',
- hostname,
- port,
- host: hostname + port,
- pathname,
- search,
- path: pathname + search,
- hash: matches[13] || '',
- searchParams
- }
- }
它返回一個對象,將正則表達(dá)式匹配的信息復(fù)制給具體的 URL 名稱的屬性。看看使用 parseURL() 方法解析前面的 URL 地址的結(jié)果吧:
- const URL = 'http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/'
- const result = parseURL(URL)
解析后的結(jié)果:
- {
- hash: undefined,
- host: "www.yaohaixiao.com",
- hostname: "www.yaohaixiao.com",
- href: "http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/",
- orgin: "http://www.yaohaixiao.com",
- password: undefined,
- path: "/blog/how-to-parse-url-with-javascript/undefined",
- pathname: undefined,
- port: undefined,
- protocol: "http",
- search: undefined,
- username: undefined,
- }
現(xiàn)在解析后的結(jié)果是不是一目了然了?當(dāng)然,使用正則表達(dá)式解析 URL 信息肯定不止本文提到的這一種方式,也有比本文中更好,更嚴(yán)謹(jǐn)?shù)钠ヅ湟?guī)則,但本文中使用的匹配方式相對來說應(yīng)該是比較易于容易理解和相對兼容性也比較好的一種處理方式。
URL 構(gòu)造函數(shù)解析
除了前文介紹的使用 JavaScript 中的正則表達(dá)式解析 URL 信息之外,還可以利用新的 URL 構(gòu)造函數(shù)來解析 URL 地址,并且解析起來更加簡單。
URL() 構(gòu)造函數(shù)
URL() 構(gòu)造函數(shù)返回一個新創(chuàng)建的 URL 對象,表示由一組參數(shù)定義的 URL。如果給定的基本 URL 或生成的 URL 不是有效的 URL 鏈接,則會拋出一個 TypeError。
語法如下:
- new URL(url [, base]);
- url:是一個表示絕對或相對 URL 的 DOMString。如果url 是相對 URL,則會將 base 用作基準(zhǔn) URL。如果 url 是絕對URL,則無論參數(shù)base是否存在,都將被忽略;
- base:可選,是一個表示基準(zhǔn) URL 的 DOMString,在 url 是相對 URL 時,它才會起效。如果未指定,則默認(rèn)為 ”;
調(diào)用方法如下:
- // 直接使用絕對 URL 地址方式調(diào)用
- const url = new URL('http://example.com/path/index.html');
- // 使用 path 加 base 地址參數(shù)的方式調(diào)用
- const url = new URL('/path/index.html', 'http://example.com');
URL() 構(gòu)造函數(shù)的接口信息如下:
- interface URL {
- href: USVString;
- protocol: USVString;
- username: USVString;
- password: USVString;
- host: USVString;
- hostname: USVString;
- port: USVString;
- pathname: USVString;
- search: USVString;
- hash: USVString;
- // 只有 orgin 和 searchParams 是只讀,其余的屬性都是可修改的
- readonly origin: USVString;
- readonly searchParams: URLSearchParams;
- toJSON(): USVString;
- }
所以每個使用 URL() 構(gòu)造函數(shù)創(chuàng)建的實例,都會返回完整 URL 信息了。例如:
- const url = new URL('http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/');
返回的數(shù)據(jù)為:
- {
- hash: "",
- host: "www.yaohaixiao.com",
- hostname: "www.yaohaixiao.com",
- href: "http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/",
- origin: "http://www.yaohaixiao.com",
- password: "",
- pathname: "/blog/how-to-parse-url-with-javascript/",
- port: "",
- protocol: "http:",
- search: "",
- searchParams: URLSearchParams {},
- username: ""
- }
可以看到,使用 URL() 構(gòu)造函數(shù)返回的數(shù)據(jù)和前文使用正則表達(dá)式解析的數(shù)據(jù)基本一致,只是這里多了一個 searchParams 對象。
searchParams 對象又是 URLSearchParams 對象的一個實例,用來獲取查詢字符串中的某個參數(shù)的值,用法如下:
- const url = new URL('http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/?id=312');
- url.searchParams.get('id') // -> 123
URL() 構(gòu)造函數(shù)的功能是不是很強(qiáng)大了。不知道 URL() 構(gòu)造函數(shù)瀏覽器支持的情況怎么樣?
URL() 構(gòu)造函數(shù)的瀏覽器兼容情況
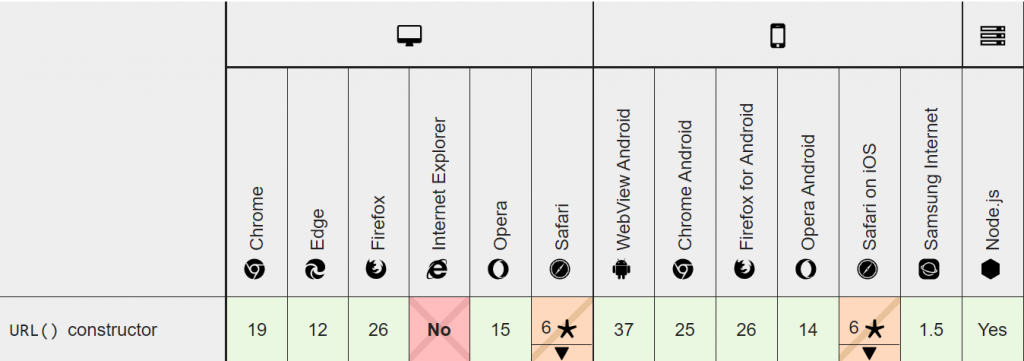
在主流瀏覽器中,除了 IE 瀏覽器,其余的都基本支持了。基本上可以放心使用 URL() 構(gòu)造函數(shù)來解析 URL 信息。
使用 URL() 構(gòu)造函數(shù)來解析 URL 信息的完整代碼如下:
- /**
- * 分析 url 地址,將解析的結(jié)果作為對象返回,返回屬性有:
- * 1. href - 完整 URL 地址
- * 2. protocol - 協(xié)議
- * 3. username - 用戶名
- * 4. password - 密碼
- * 5. host - 域名地址
- * 6. hostname - 域名名稱
- * 7. port - 端口號
- * 8. path - 路徑
- * 9. pathname - 路徑名
- * 10. search - 查詢參數(shù)
- * 11. hash - 哈希值
- * 12. origin
- * 13. searchParams
- * ====================================================
- * @param {String} url - URL地址
- * @param {String} [base] - 基準(zhǔn) URL 地址
- * @returns {Object}
- */
- const parseURLWithURLConstructor = (url= location.href, base) => {
- const results = new URL(url, base)
- const protocol = results.protocol.replace(':', '')
- return {
- href: url,
- origin: results.origin,
- protocol,
- username: results.username,
- password: results.password,
- hostname: results.hostname,
- port: results.port,
- host: results.host,
- pathname: results.pathname,
- search: results.search,
- path: results.pathname + results.search,
- hash: results.hash,
- searchParams: results.searchParams
- }
- }
正則表達(dá)式解析 VS URL 構(gòu)造函數(shù)解析
對兩種解析 URL 信息的方法進(jìn)行比較,很明顯使用 URL() 構(gòu)造函數(shù)解析的方法操作更加簡單,并且提供更多的功能。但與正則表達(dá)式解析方法比較,可能唯一不足的就是在 IE 瀏覽器中無法使用。
其實,只要稍微調(diào)整一下,就可以將兩種方法結(jié)合起來,在支持 URL() 構(gòu)造函數(shù)的瀏覽器中使用構(gòu)造函數(shù),不知支持的時候則使用正則表達(dá)式解析:
- /**
- * 分析 url 地址,將解析的結(jié)果作為對象返回,返回屬性有:
- * 1. href - 完整 URL 地址
- * 2. protocol - 協(xié)議
- * 3. username - 用戶名
- * 4. password - 密碼
- * 5. host - 域名地址
- * 6. hostname - 域名名稱
- * 7. port - 端口號
- * 8. path - 路徑
- * 9. pathname - 路徑名
- * 10. search - 查詢參數(shù)
- * 11. hash - 哈希值
- * 12. origin
- * ====================================================
- * @param {String} url - URL地址
- * @param {String} [base] - 基準(zhǔn) URL 地址
- * @returns {Object}
- */
- const parseURL = (url = location.href, base) => {
- const getURLSearchParams = (url) => {
- return (url.match(/([^?=&]+)(=([^&]*))/g) || []).reduce((a, v) => {
- return ((a[v.slice(0, v.indexOf('='))] = v.slice(v.indexOf('=') + 1)), a)
- }, {})
- }
- const parseURLWithRegExp = (url) => {
- const pattern = /^(([^:/?#]+):)?\/\/(([^/?#]+):(.+)@)?([^/?#:]*)(:(\d+))?([^?#]*)(\\?([^#]*))?(#(.*))?/,
- matches = url.match(pattern),
- hostname = matches[6],
- port = matches[8] || '',
- pathname = matches[11] || '/',
- search = matches[10] || '',
- searchParams = (() => {
- const params = getURLSearchParams(url)
- return {
- get (name) {
- return params[name] || ''
- }
- }
- })()
- return {
- href: url,
- origin: (matches[1] ? matches[1] + '//' : '') + hostname,
- protocol: matches[2] || '',
- username: matches[4] || '',
- password: matches[5] || '',
- hostname,
- port,
- host: hostname + port,
- pathname,
- search,
- path: pathname + search,
- hash: matches[13] || '',
- searchParams
- }
- }
- const parseURLWithURLConstructor = (url) => {
- const results = new URL(url)
- const protocol = results.protocol.replace(':', '')
- return {
- href: url,
- origin: results.origin,
- protocol,
- username: results.username,
- password: results.password,
- hostname: results.hostname,
- port: results.port,
- host: results.host,
- pathname: results.pathname,
- search: results.search,
- path: results.pathname + results.search,
- hash: results.hash,
- searchParams: results.searchParams
- }
- }
- // url 是為度路徑時,忽略 base
- if (/^(([^:/?#]+):)/.test(url)) {
- base = ''
- }
- // 設(shè)置了基準(zhǔn) URL
- if (base) {
- // 移除 base 最后的斜杠 ‘/’
- if (/[/]$/.test(base)) {
- base = base.replace(/[/]$/, '')
- }
- // 確保 url 開始有斜杠
- if (!/^[/]/.test(url)) {
- url = '/' + url
- }
- // 保證 URL 地址拼接后是一個正確的格式
- url = base + url
- }
- if (window.ActiveXObject) {
- return parseURLWithRegExp(url)
- } else {
- return parseURLWithURLConstructor(url)
- }
- }
演示地址:
http://www.yaohaixiao.com/scripts/parseURL/
結(jié)束語
隨著 Web 技術(shù)的不斷發(fā)展,JavaScript 也在不斷地發(fā)展,許多新的 API 接口也不斷的完善,充分的得到各個主流瀏覽器的支持。我們在開發(fā)過程中就必須不斷的關(guān)注新技術(shù)的更新,找到更加靈活便捷的解決方案來解決開發(fā)中的問題。
本文僅僅是拿解析 URL 信息作為示例,展示使用不同解決方案的一個實踐。如果你有什么更好地解析 URL 信息的方式,也歡迎跟我聯(lián)系交流。