模型部署優化的學習路線是什么?
知友問: 我現在只會 Python,每天工作就是寫腳本處理數據、訓練模型,但是沒什么工程能力,我想往模型部署優化、算法落地這個方向發展,請問該怎么學習與規劃?
模型部署優化這個方向其實比較寬泛。 從模型完成訓練,到最終將模型部署到實際硬件上,整個流程中會涉及到很多不 同層面的工作,每一個環節對技術點的要求也不盡相同。
部署的流程大致可以分為 以 下幾個環節:
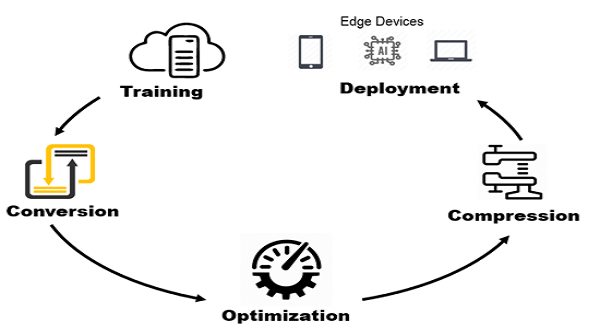
一、模型轉換
從訓練框架得到模型后,根據需求轉換到相應的模型格式。 模型格式的選擇通常是根據公司業務端 SDK 的需求,通常為 caffe 模型或 onnx 模型,以方便模型在不同的框架之間適配。
該環節的工作需要對相應的訓練框架以及 caffe/onnx 等模型格式有所了解。
常用的 Pytorch 和 TensorFlow 等框架都有十分成熟的社區和對應的博客或教程; caffe 和 onnx 模型格式也有很多可參考和學習的公開文檔。
即使沒找到有可參考的文章時,好在二者都是開源的,依然可以通過對源碼和樣例代碼的閱讀來尋找答案。
二、模型優化
此處的模型優化是指與后端無關的通用優化,比如常量折疊 、 算數優化 、 依賴優化 、 函數優化 、 算子融合 以及 模型信息簡化等等。
部分訓練框架會在訓練模型導出時就包含部分上述優化過程,同時如果模型格式進行了轉換操作,不同 IR 表示之間的差異可能會引入一 些冗余或可優化的計算,因此在模型轉換后通常也會進行一部分的模型優化操作。
該環節的工作需要對計算圖的執行流程、各個 op 的計算定義、程序運行性能模型有一定了解,才能知道如果進行模型優化, 如何 保證優化后的模型具有更好的性能。
了解 得 越深入,越可以挖掘到更多的模型潛在性能。
三、模型壓縮
廣義上來講,模型壓縮也屬于模型優化的一部分。模型壓縮本身也包括很多種方法,比如剪枝 、 蒸餾 、 量化等等。 模型壓縮的根本目的是希望獲得一個較小的模型,減少存儲需求的同時降低計算量,從而達到加速的目的。
該環節的工作需要對壓縮算法本身 、 模型涉及到的算法任務及模型結構設計 、 硬件平臺計算流程三個方面都有一定的了解。
當因模型壓縮操作導致模型精度下降時,對模型算法的了解,和該模型在硬件上的計算細節有足夠的了解,才能分析出精度下降的原因,并給出針對性的解決方案。
對于模型壓縮更重要的往往是工程經驗 , 因為在不同的硬件后端上部署相同的模型時, 由于 硬件計算的差異性,對精度的影響往往也不盡相同,這方面只有通過 積累 工程經驗來不斷提升。
Open PPL 也在逐步開源自己的模型壓縮工具鏈,并對上述提到的模型算法、壓縮算法 和 硬件平臺適配等方面的知識進行介紹 。
四、模型部署
模 型部署是整個過程中最復雜的環節。從工程上講,主要的核心任務是模型打包 、 模型加密,并進行 SDK 封裝。
在一個實際的產品中,往往會用到多個模型。
模型打包是指將模型涉及到的前后處理,以及多個模型整合到一起,并加入一些其他描述性文件。 模型打包的格式和模型加密的方法與具體的 SDK 相關。 在該環節中主要涉及到的技能與 SDK 開發更為緊密。
從功能上講,對部署最后的性能影響最大的肯定是 SDK 中包含的后端庫,即實際運行模型的推理庫。 開發一個高性能推理庫所需要的技能點就要更為廣泛 ,并且 專業。
并行計算的編程思想在不同的平臺上是通用的,但不同的硬件架構的有著各自的特點,推理庫的開發思路也不盡相同,這也就要求對開發后端的架構體系有著一定的了解。
具體到不同架構的編程學習,建議參考當前各大廠開源的推理庫來進一步學習 。