比用Pytorch框架快200倍!0.76秒后,筆記本上的CNN就搞定了MNIST
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
在MNIST上進行訓練,可以說是計算機視覺里的“Hello World”任務了。
而如果使用PyTorch的標準代碼訓練CNN,一般需要3分鐘左右。
但現在,在一臺筆記本電腦上就能將時間縮短200多倍。
速度直達0.76秒!
那么,到底是如何僅在一次epoch的訓練中就達到99%的準確率的呢?
八步提速200倍
這是一臺裝有GeForce GTX 1660 Ti GPU的筆記本。
我們需要的還有Python3.x和Pytorch 1.8。
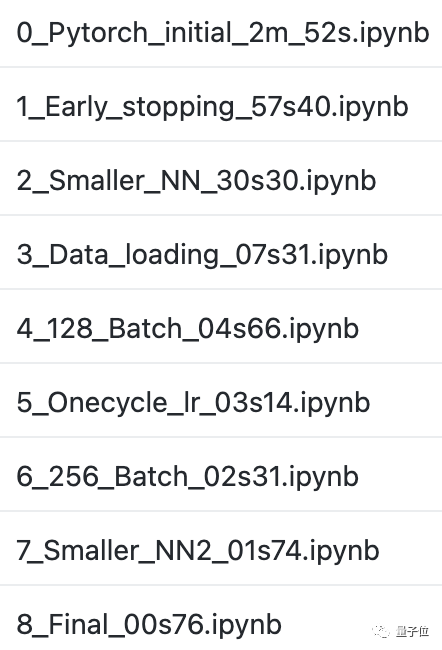
先下載數據集進行訓練,每次運行訓練14個epoch。
這時兩次運行的平均準確率在測試集上為99.185%,平均運行時間為2min 52s ± 38.1ms。
接下來,就是一步一步來減少訓練時間:
一、提前停止訓練
在經歷3到5個epoch,測試準確率達到99%時就提前停止訓練。
這時的訓練時間就減少了1/3左右,達到了57.4s±6.85s。
二、縮小網絡規模,采用正則化的技巧來加快收斂速度
具體的,在第一個conv層之后添加一個2x2的最大采樣層(max pool layer),將全連接層的參數減少4倍以上。
然后再將2個dropout層刪掉一個。
這樣,需要收斂的epoch數就降到了3個以下,訓練時間也減少到30.3s±5.28s。
三、優化數據加載
使用data_loader.save_data(),將整個數據集以之前的處理方式保存到磁盤的一個pytorch數組中。
也就是不再一次一次地從磁盤上讀取數據,而是將整個數據集一次性加載并保存到GPU內存中。
這時,我們只需要一次epoch,就能將平均訓練時間下降到7.31s ± 1.36s。
四、增加Batch Size
將Batch Size從64增加到128,平均訓練時間減少到4.66s ± 583ms。
五、提高學習率
使用Superconvergence來代替指數衰減。
在訓練開始時學習率為0,到中期線性地最高值(4.0),再慢慢地降到0。
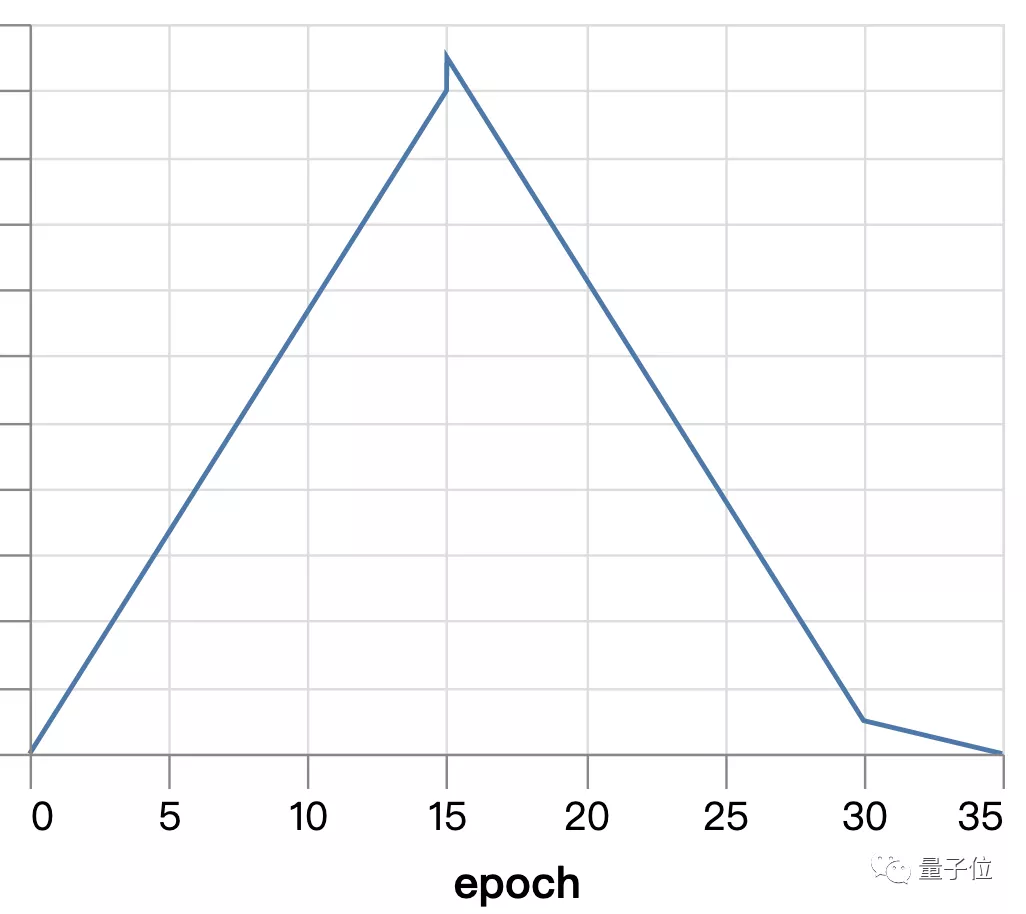
這使得我們的訓練時間下降到3.14s±4.72ms。
六、再次增加Batch Size、縮小縮小網絡規模
重復第二步,將Batch Size增加到256。
重復第四步,去掉剩余的dropout層,并通過減少卷積層的寬度來進行補償。
最終將平均時間降到1.74s±18.3ms。
七、最后的微調
首先,將最大采樣層移到線性整流函數(ReLU)激活之前。
然后,將卷積核大小從3增加到5.
最后進行超參數調整:
使學習率為0.01(默認為0.001),beta1為0.7(默認為0.9),bata2為0.9(默認為0.999)。
到這時,我們的訓練已經減少到一個epoch,在762ms±24.9ms的時間內達到了99.04%的準確率。

“這只是一個Hello World案例”
對于這最后的結果,有人覺得司空見慣:
優化數據加載時間,縮小模型尺寸,使用ADAM而不是SGD等等,都是常識性的事情。
我想沒有人會真的費心去加速運行MNIST,因為這是機器學習中的“Hello World”,重點只是像你展示最小的關鍵值,讓你熟悉這個框架——事實上3分鐘也并不長吧。

而也有網友覺得,大多數人的工作都不在像是MNIST這樣的超級集群上。因此他表示:
我所希望的是工作更多地集中在真正最小化訓練時間方面。

GitHub:
https://github.com/tuomaso/train_mnist_fast