首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
在超越人類這件事上,AI 又拿下一分。
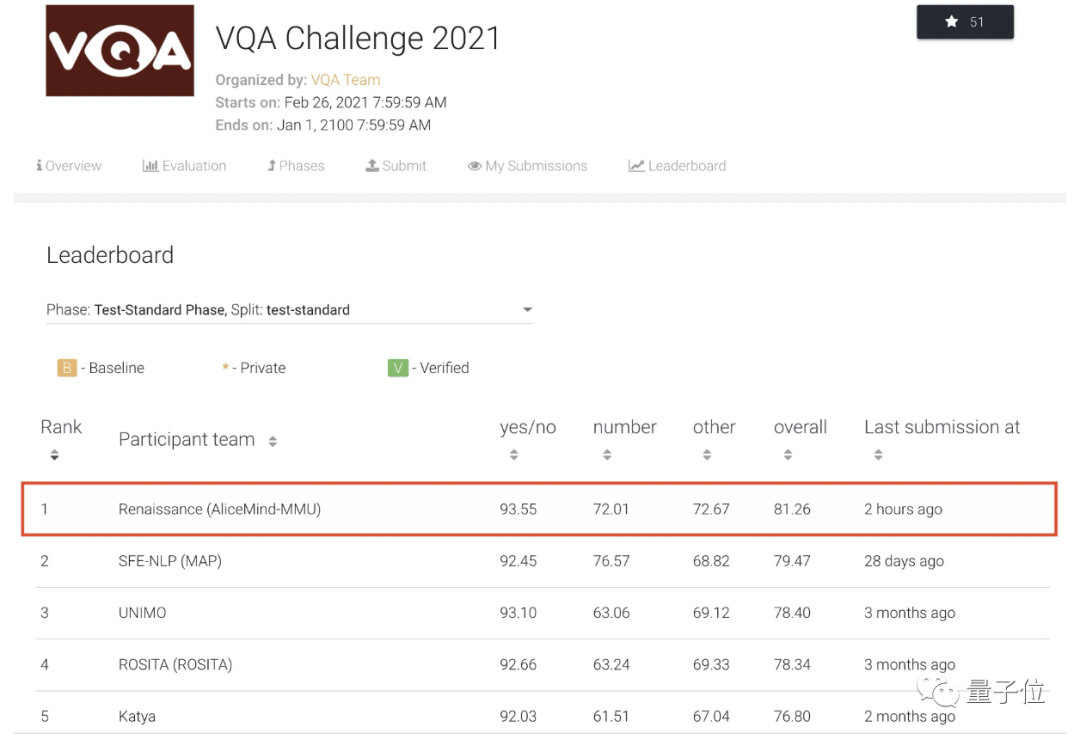
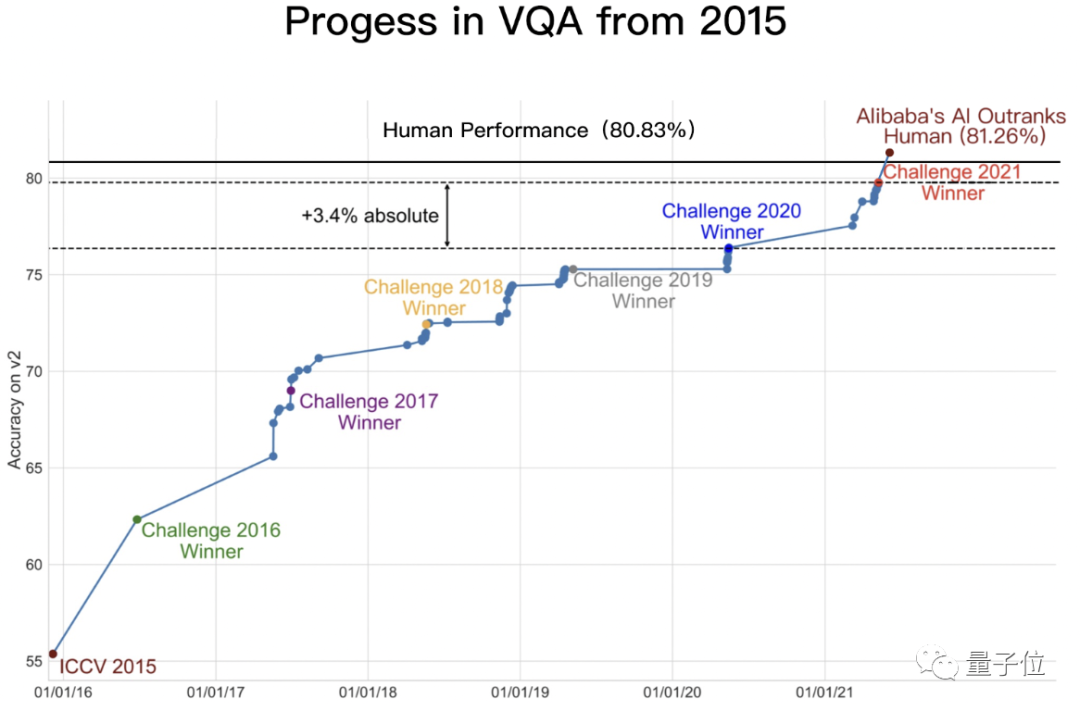
就在最近,國際權(quán)威機(jī)器視覺問答榜單VQA Leaderboard,更新了一項(xiàng)數(shù)據(jù):
AI在“讀圖會意”任務(wù)中,準(zhǔn)確率達(dá)到了81.26%。
 首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">
首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">要知道,我們人類在這個(gè)任務(wù)中的基準(zhǔn)線,也才80.83%。
而解鎖這一成就的,是來自阿里巴巴達(dá)摩院團(tuán)隊(duì)的AliceMind-MMU。
而此舉也就意味著,AI 于2015年、2018年分別在視覺識別和文本理解超越人類之后,在多模態(tài)技術(shù)方面也取得了突破!
AI比你更會看圖
這個(gè)AI有多會看圖?
來看下面幾個(gè)例子就知道了。
當(dāng)你問AI:“這些玩具用來做什么的?”
它就會根據(jù)小熊穿的禮服,回答道:
婚禮。
 首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">
首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">給AI再提一個(gè)問題:“男人的橄欖球帽代表哪只球隊(duì)?”
它會根據(jù)帽子中的“B”字母回答:
波士頓球隊(duì)。
 首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">
首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">加大挑戰(zhàn)難度再來一個(gè)。
“圖中玩具人的IP出自哪部電影?”
這時(shí)候,AI 就會根據(jù)圖中的玩具,還有戰(zhàn)斗場景等信息,做一個(gè)推理。
不過最后還是精準(zhǔn)的給出了答案:
星球大戰(zhàn)。
 首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">
首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">再例如下面這些例子中,AI都會捕捉圖片中的細(xì)節(jié)信息,來精準(zhǔn)回答提出的問題。
 首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">
首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">嗯,可以說是細(xì)致入微了。
怎么做到的?
可能上面的這些案例,對于人類來說并不是很困難。
但對于AI來說,可不是件容易的事情。
一個(gè)核心難點(diǎn)就是:
需要在單模態(tài)精準(zhǔn)理解的基礎(chǔ)上,整合多模態(tài)的信息進(jìn)行聯(lián)合推理認(rèn)知,最終實(shí)現(xiàn)跨模態(tài)理解。
怎么破?
阿里達(dá)摩院的做法是,對AI視覺-文本推理體系進(jìn)行了系統(tǒng)性的設(shè)計(jì),融合了大量的創(chuàng)新算法。
 首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">
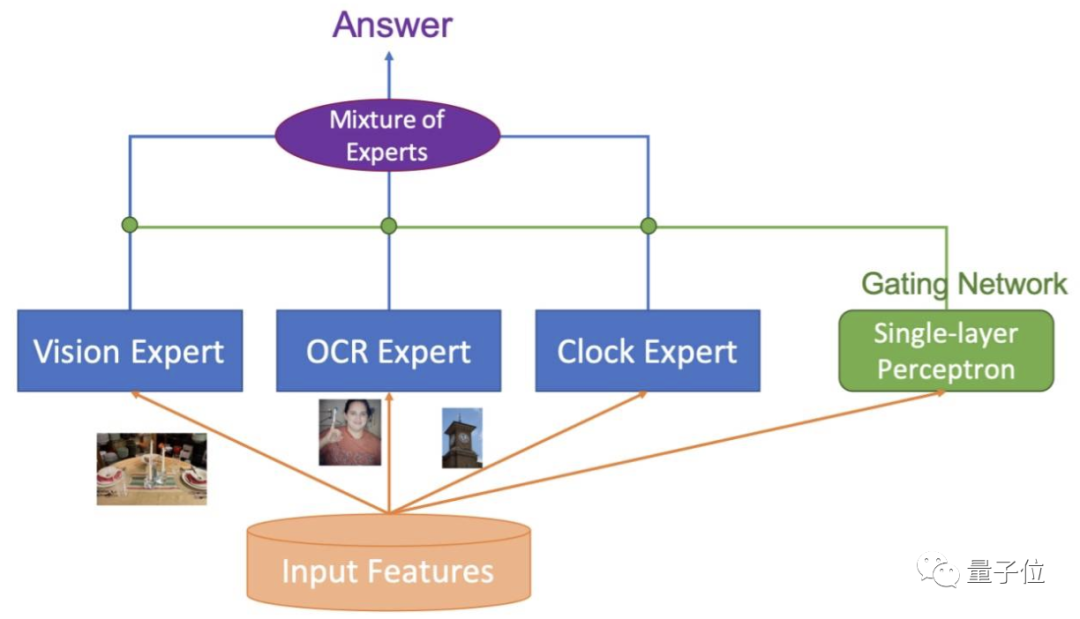
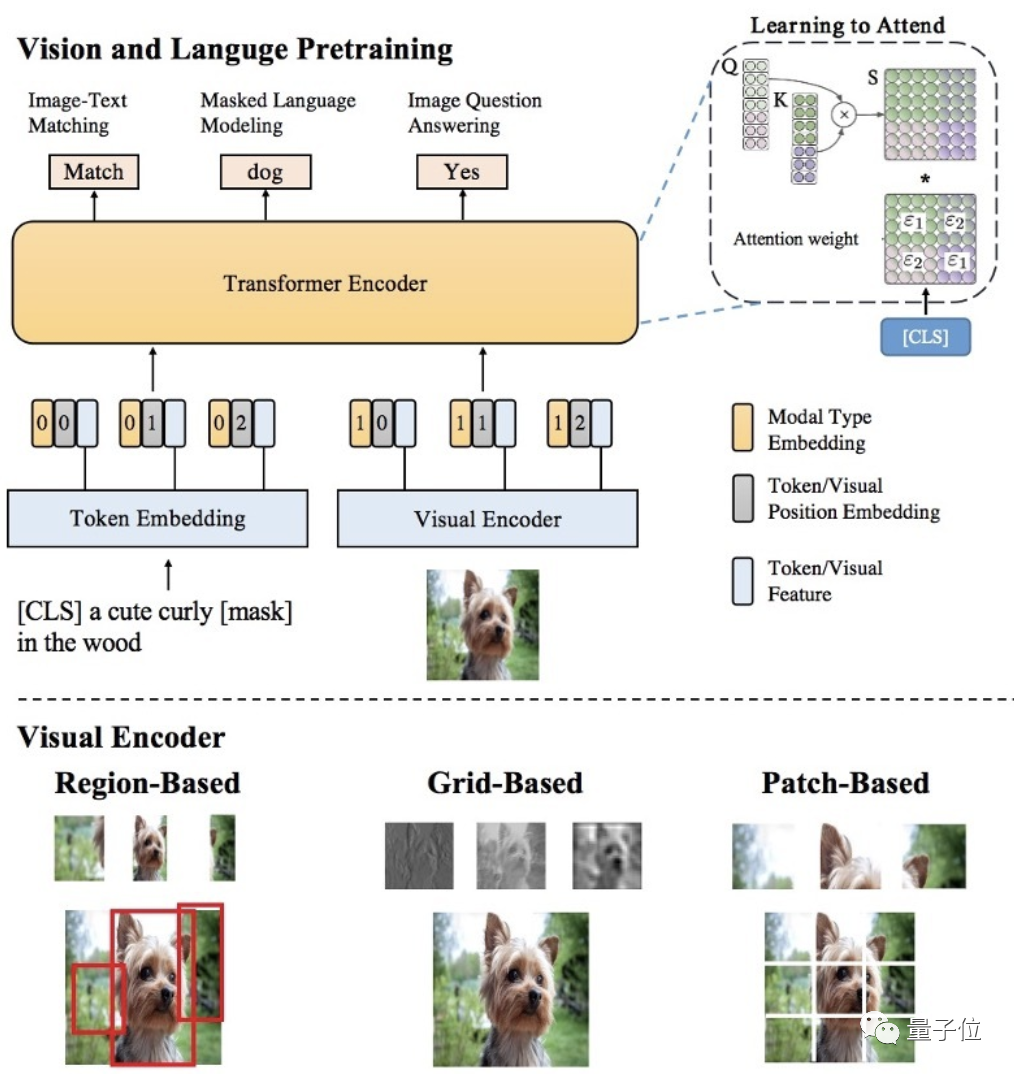
首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">具體來看,大致可以分為四個(gè)內(nèi)容:
- 多樣性的視覺特征表示:從各方面刻畫圖片的局部和全局語義信息,同時(shí)使用Region,Grid,Patch等視覺特征表示,可以更精準(zhǔn)地進(jìn)行單模態(tài)理解;
- 基于海量圖文數(shù)據(jù)和多粒度視覺特征的多模態(tài)預(yù)訓(xùn)練:用于更好地進(jìn)行多模態(tài)信息融合和語義映射,提出了SemVLP、Grid-VLP、E2E-VLP和Fusion-VLP等預(yù)訓(xùn)練模型。
- 自適應(yīng)的跨模態(tài)語義融合和對齊技術(shù):在多模態(tài)預(yù)訓(xùn)練模型中加入Learning to Attend機(jī)制,來進(jìn)行跨模態(tài)信息地高效深度融合。
- Mixture of Experts (MOE)技術(shù):進(jìn)行知識驅(qū)動的多技能AI集成。
 首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">
首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">據(jù)了解,模型中涉及技術(shù)還得到了專業(yè)的認(rèn)可。
例如多模態(tài)預(yù)訓(xùn)練模型E2E-VLP,已經(jīng)被國際頂級會議ACL2021接受。
 首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">
首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">關(guān)于VQA
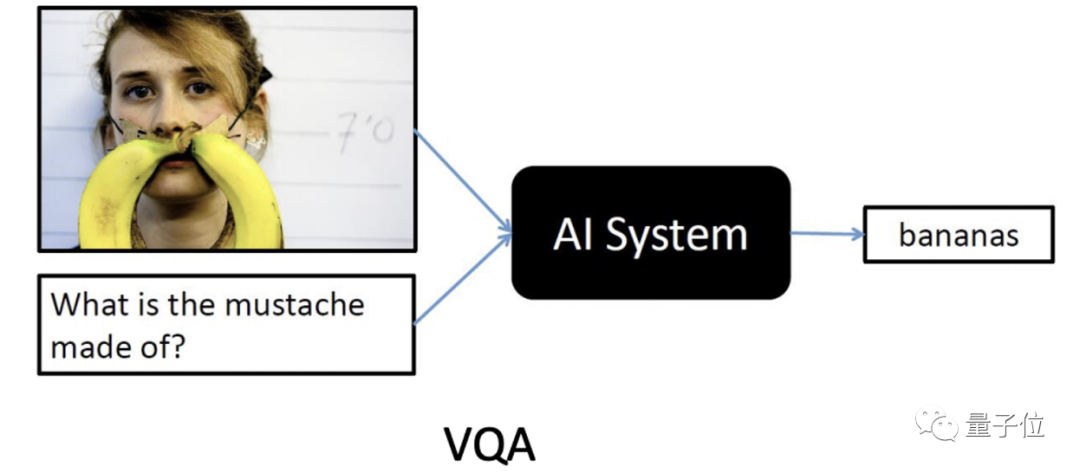
VQA,可以說是AI領(lǐng)域難度最高的挑戰(zhàn)之一。
而對于單一AI模型來說,VQA考卷難度堪稱“變態(tài)”。
在測試中,AI需要根據(jù)給定圖片及自然語言問題,生成正確的自然語言回答。
這意味著單個(gè)AI模型,需要融合復(fù)雜的計(jì)算機(jī)視覺及自然語言技術(shù):
- 首先對所有圖像信息進(jìn)行掃描。
- 再結(jié)合對文本問題的理解,利用多模態(tài)技術(shù)學(xué)習(xí)圖文的關(guān)聯(lián)性、精準(zhǔn)定位相關(guān)圖像信息。
- 最后根據(jù)常識及推理回答問題。
 首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">
首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">但解決VQA的挑戰(zhàn),對研發(fā)通用人工智能具有重要意義。
因此,全球計(jì)算機(jī)視覺頂會CVPR從2015年起連續(xù)6年舉辦VQA挑戰(zhàn)賽。
吸引了包括微軟、Facebook、斯坦福大學(xué)、阿里巴巴、百度等眾多頂尖機(jī)構(gòu)參與。
同時(shí),也形成了國際上規(guī)模最大、認(rèn)可度最高的VQA數(shù)據(jù)集,其包含超20萬張真實(shí)照片、110萬道考題。
 首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">
首次超越人類!“讀圖會意”這件事,AI比你眼睛更毒辣 | 達(dá)摩院">據(jù)了解,今年6月,阿里達(dá)摩院在VQA 2021 Challenge的55支提交隊(duì)伍中奪冠,成績領(lǐng)先第二名約1個(gè)百分點(diǎn)、去年冠軍3.4個(gè)百分點(diǎn)。
而僅僅在2個(gè)月后的今天,達(dá)摩院再次以81.26%的準(zhǔn)確率創(chuàng)造VQA Leaderboard全球紀(jì)錄。
達(dá)摩院對此評價(jià)道:
這一結(jié)果意味著,AI在封閉數(shù)據(jù)集內(nèi)的VQA表現(xiàn)已媲美人類。
相關(guān)論文鏈接:
[1]https://aclanthology.org/2021.acl-long.42/
[2]https://aclanthology.org/2021.acl-long.493/
[3]https://openreview.net/forum?id=Wg2PSpLZiH
VQA示例鏈接:
https://nlp.aliyun.com/portal#/multi_modal
達(dá)摩院AliceMind開源鏈接:
https://github.com/alibaba/AliceMind