AI在這張“問卷”上首次超越人類,微軟登頂SuperGLUE
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
自然語言理解(NLU)迎來新的里程碑。
在最新的NLU測試基準SuperGLUE中,人類首次被AI超越了。
SuperGLUE相比“前輩”GLUE大大提升了問題的難度,提出一年多以來,人類一直處于第一位。
現如今,人類一下子被兩家AI超越。
一個是來自微軟的DeBERTa,一個是來自谷歌的T5+Meena。
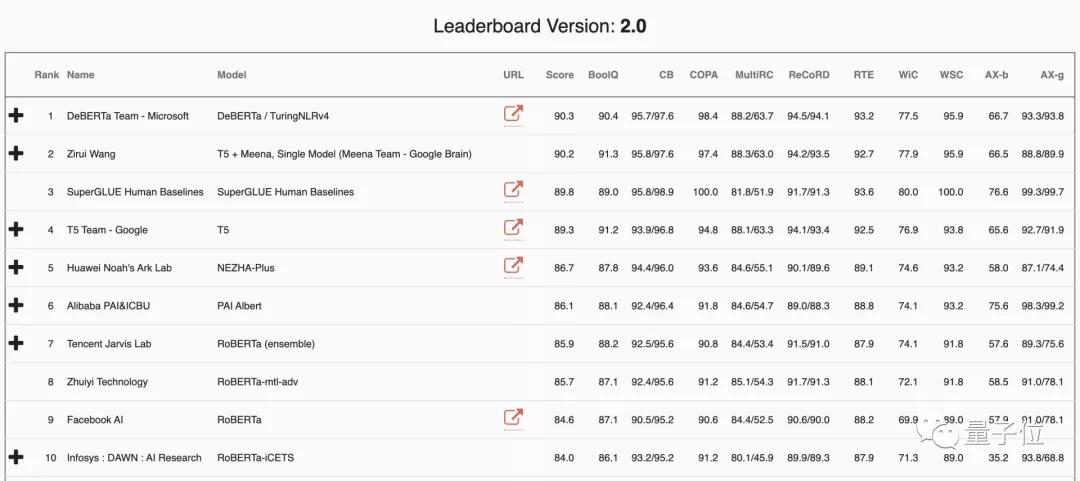
超越人類的兩大NLU模型
對NLP領域的人來說,微軟DeBERTa模型并不陌生,早在去年8月微軟就開源了該模型的代碼,并提供預訓練模型下載。

最近,最近微軟訓練了更大規模的模型,該版本由15億參數的48個Transformer層組成。增大規模帶來的性能提升,使單個DeBERTa模型SuperGLUE上的得分(90.3)首次超過了人類(89.8),居于榜單首位。
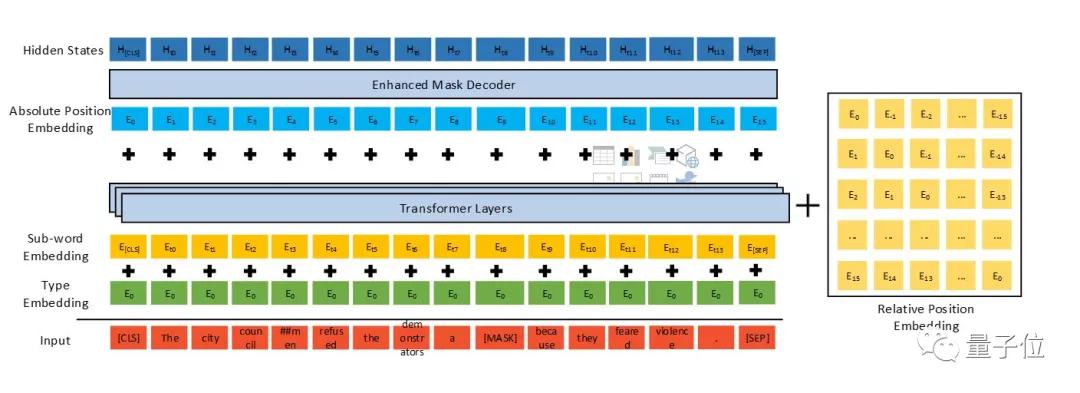
DeBERTa(注意力分離的解碼增強BERT)是一種基于Transformer的神經語言模型,使用自監督學習對大量原始文本語料庫進行預訓練。
和其他預訓練語言模型(PLM)一樣,DeBERTa旨在學習通用語言表示形式,適應各種下游NLU任務。DeBERTa使用三種新技術——分離的注意力機制、增強的掩碼解碼器和一種用于微調的虛擬對抗訓練方法。改進了以前的最新PLM(如BERT、RoBERTa、UniLM)。
這項研究是由微軟研究團隊的4位華人學者完成。
另一超越人類的AI是由CMU博士生王子瑞提交的T5+Meena。這兩項技術均來自谷歌。
其中,Meena是一個26億參數端到端訓練的神經對話模型,它具有一個演進Transformer編碼器塊和13個演進Transformer解碼器塊。
編碼器負責處理對話上下文,幫助Meena理解對話中已經說過的內容。然后,解碼器使用該信息來制定實際響應。
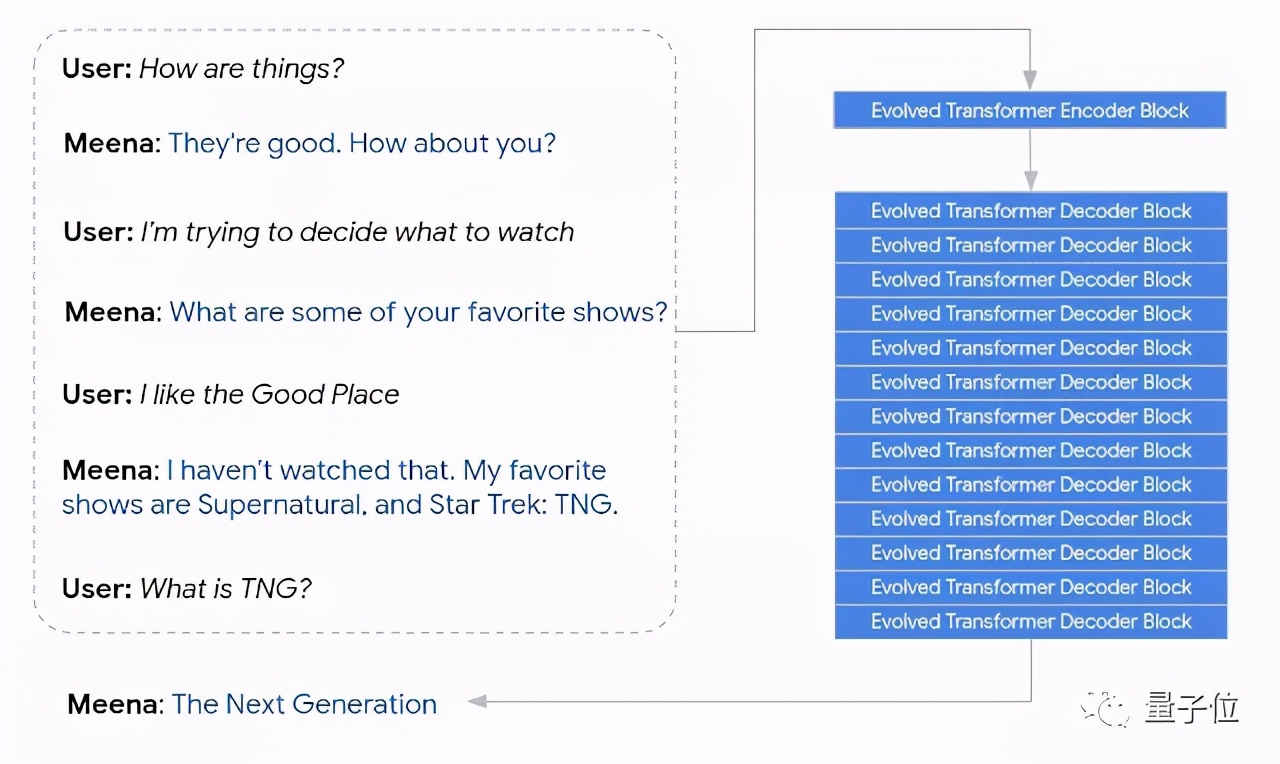
T5是谷歌去年提出的“文本到文本遷移Transformer”,也就是用遷移學習讓不同的NLP任務可以使用相同的模型、損失函數和超參數,一個框架在機器翻譯、文檔摘要、問答和情感分析上都能使用。
T5最大的模型具有110億個參數,早在推出之時就取得了SuperGLUE上的最高水平,至今仍僅次于榜單前二模型和人類。

關于SuperGLUE
SuperGLUE是由Facebook、紐約大學、華盛頓大學和DeepMind四家機構于2019年8月提出的新NLU測試基準,以取代過去的GLUE。

由于之前微軟、谷歌和Facebook的模型連續刷新GLUE基準測試得分,已有不少AI模型超越了人類的表現。因此GLUE已不能順應NLU技術的發展,SuperGLUE應運而生。
我們從最初的GLUE基準測試中吸取的經驗教訓,并推出了SuperGLUE,這是一個采用了GLUE的新基準測試,具有一系列更加困難的語言理解任務、改進的資源和一個新的公共排行榜。
四家機構在SuperGLUE的官方文檔中如是說。
SuperGLUE總共包含10項任務,用于測試系統因果推理、識別因果關系、閱讀短文后回答是非問題等等方面的能力。SuperGLUE還包含Winogender,一種性別偏見檢測工具。
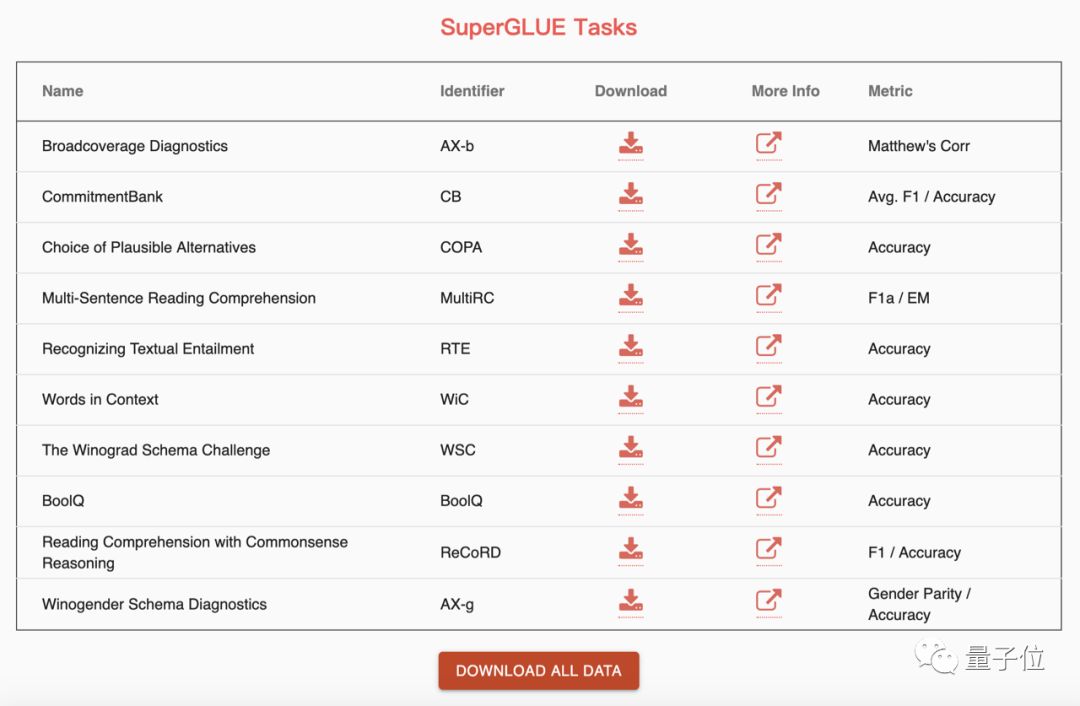
這些問題用當前最先進的算法還不能很好地解決,卻很容易被人類理解。
尤其是“選擇合理的替代方案”(COPA)這一項因果推理任務。它要求系統能根據給出的句子,在兩個選項中找出可能的原因或結果。比如:
那個男人的腳趾斷了。這是什么原因造出的?
備選答案1:他的襪子上有一個洞。
備選答案2:他把錘子掉在腳上了。
人類可以在COPA上獲得了100%的準確率,而BERT只有74%,這表明了NLU還存在巨大的進步空間。
現在SuperGLUE上超越了人類表現,微軟的研究人員認為:“這是通向通用AI的重要里程碑”。
微軟DeBERTa源代碼與預訓練模型:
https://github.com/microsoft/DeBERTa
谷歌T5和Meena:
https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html