連通系統與機器學習的 MLOps 挑戰在哪?這篇文章講清楚了
機器學習徹底改變了人們使用數據以及與數據交互的方式,提升了商業效率,從根本上改變了廣告業的格局,全面變革了醫療健康技術。但是,機器學習若要繼續擴大其影響力和影響范圍,開發 pipeline 必 須得到改進。通過將數據庫系統、分布式計算和應用部署等領域數十年的工作引入機器學習領域,機器學習系統研究可以滿足這一需求。此外,通過充分利用模型并行以及改進舊有解決方案,我們可以利用系統的重新設計來改進機器學習。
過去十年,機器學習(ML)已經成為各種領域中無數應用和服務的重要組成部分。得益于機器學習的快速發展,從醫療健康到自動駕駛等諸多領域已經出現了深刻的變革。
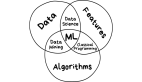
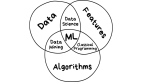
機器學習在實際應用中日益增加的重要性使人們開始關注一個專注于「實踐中機器學習」的新領域,即機器學習系統(或簡稱 MLOps)。該領域連通計算機系統和機器學習,并從傳統系統研究的視角考慮機器學習的新挑戰。
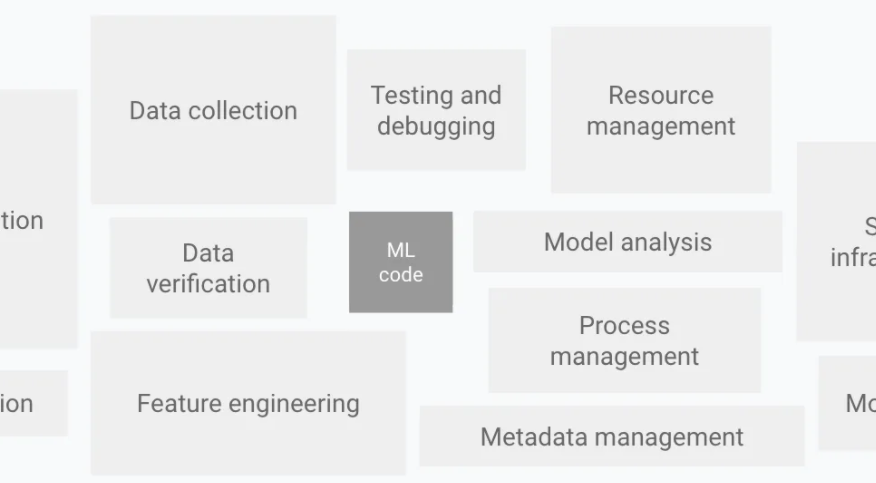
那么機器學習的挑戰究竟有哪些呢?加州大學圣地亞哥分校博士生 Kabir Nagrecha 使用 D. Sculley 2015 年的論文《 Hidden Technical Debt in Machine Learning Systems 》中提出的架構,來描述典型 ML 系統中的問題并一一分解其組件。
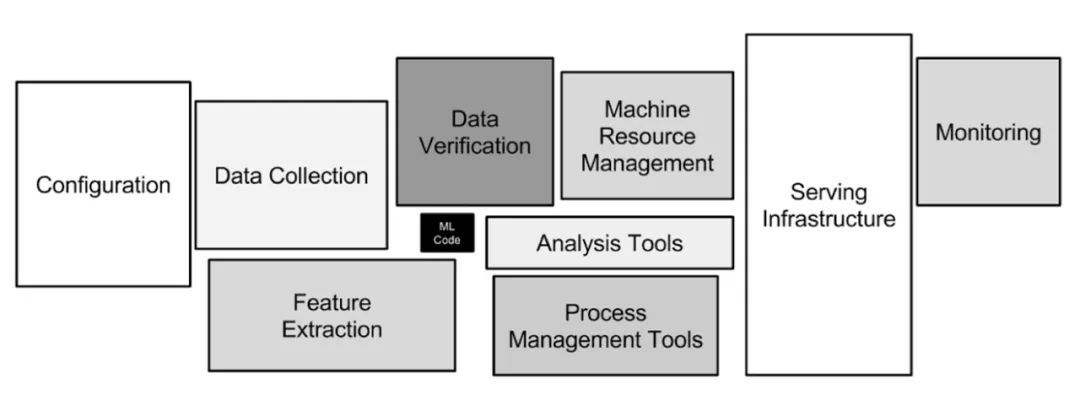
D. Sculley 論文中的 ML 系統架構,圖源:https://papers.nips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
Kabir Nagrecha 重點分析了數據收集、驗證和服務任務中的挑戰,并探討了模型訓練中的一些問題,這是因為近年來模型訓練已經成為系統開發中成本越來越高昂的部分。
接下來我們進行一一分析。
數據收集
雖然學界研究者對 CIFAR 或 SQuAD 等隨時可用的數據集感到滿意,但業界從業者往往需要在模型訓練中手動標注并生成自定義數據集。但是,創建這類數據集,尤其是需要領域知識時,需要的成本可能非常高昂。
因此,這成為了 ML 系統開發者面臨的一個主要挑戰。
如何解決呢?該問題最成功的解決方案之一是借鑒系統與機器學習領域的研究。比如,通過結合數據管理技術與自監督學習工作,斯坦福大學研究者在 2017 年的論文《 Snorkel: Rapid Training Data Creation with Weak Supervision 》中提出了一種弱監督的數據編程方法。
他們提出的 SnorkelAI 將數據集創建視作一個編程問題,其中用戶可以為弱監督標注指定函數,然后通過組合和加權操作以生成高質量的標簽。這樣一來,專家標注的高質量數據和自動標注的低質量數據可以進行融合和跟蹤以確保模型訓練實現準確加權,從而充分考慮到不同級別的標簽質量。
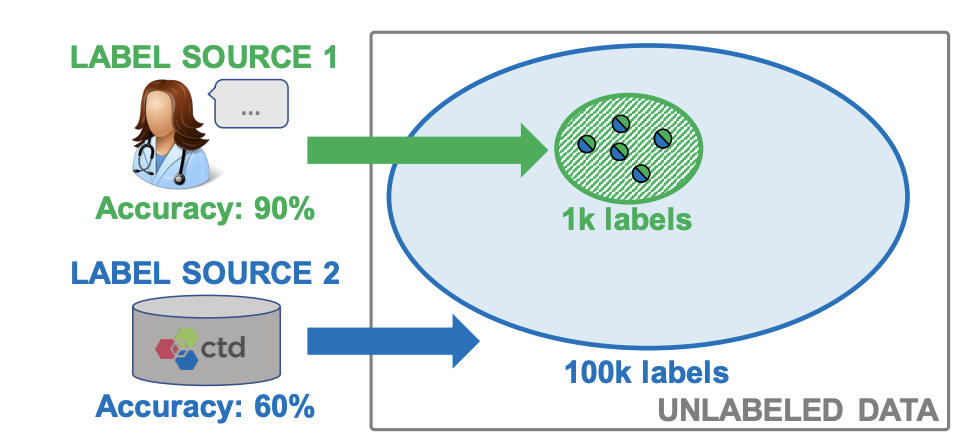
SnorkelAI 結合了不同來源的標簽,以允許模型大規模地聚合和改進混合質量的標簽。圖源:https://arxiv.org/pdf/1711.10160.pdf
這種方法令人聯想到數據庫管理系統的數據融合,將其應用到機器學習是一個支點和再設計,而不是僅僅針對 ML 的革命性創造。通過確認系統和 ML 領域的共有問題,并結合數據來源,傳統的系統技術可以應用于機器學習設置中。
數據驗證
數據驗證是數據收集的后續操作。數據質量是機器學習 pipeline 中的關鍵問題。維護者如果想要為自己的系統生成高質量模型,則必須保證輸入的數據也是高質量的。
調整機器學習方法并不能輕易地解決這一問題,因而需要對 ML 系統進行調整。幸運的是,雖然機器學習的數據驗證是一個新問題,但數據驗證不是。
引用 TensorFlow 數據驗證(TFDV)相關論文《 Data Validation for Machine Learning 》中的表述:
數據驗證既不是一個新問題,也不是機器學習獨有的,所以我們可以借鑒數據庫系統等相關領域中的解決方案。但是,我們認為數據驗證在機器學習場景中面臨著獨特的挑戰,因而需要重新思考現有解決方案。
再一次,通過確認機器學習系統和傳統計算機系統之間的并行挑戰,我們可以通過一些機器學習導向的修改來重新利用現有解決方案。
TFDV 的解決方案使用了數據管理系統中久經驗證的解決方案——schemas。一個數據庫強制執行屬性以確保數據輸入和更新遵循指定的格式。同樣地,TFDV 的數據模式系統也對輸入至模型的數據強制執行一些規則。
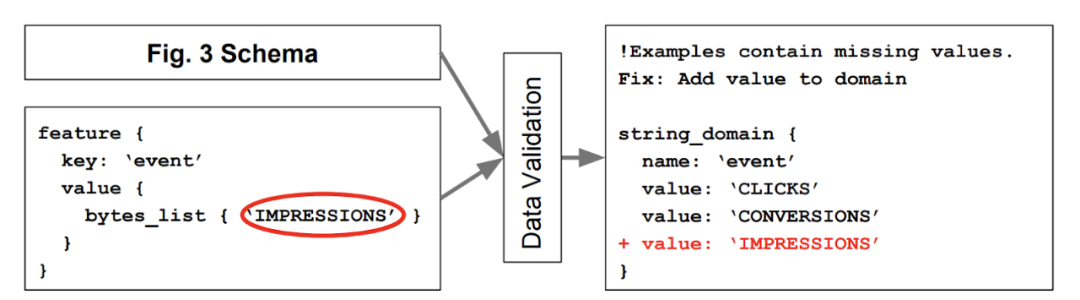
TFDV 的用于 ML 數據驗證的模式系統使用戶可以避免生成系統中數據饋送的異常現象。圖源:https://mlsys.org/Conferences/2019/doc/2019/167.pdf
當然會有一些不同的地方,反映出了機器學習系統與傳統范式的區別。ML 模式不僅需要與時俱進和實時調整以適應分布變化,而且需要考慮系統生命周期中模型自身可能出現的變化。
模型訓練
ML 從業者可能感到驚訝的是將模型訓練作為系統優化的一個領域。畢竟,如果機器學習應用中有一個領域真正依賴 ML 技術,那就是訓練。但即使這樣,系統研究依然可以發揮作用。
以模型并行化為例,隨著 Transformer 崛起,各種應用 ML 領域在模型尺寸方面都出現了顯著增加。幾年前,BERT-Large 模型的參數達到了 3.45 億,現在 Megatron-LM 增加到了 1 萬億以上。
這些模型的內存成本已經達到了數百 GB,沒有一個 GPU 可以 hold 它們。傳統解決方案——模型并行化采用了一種相對簡單的方法,即在不同的設備上對模型進行劃分以分配相應的內存成本。
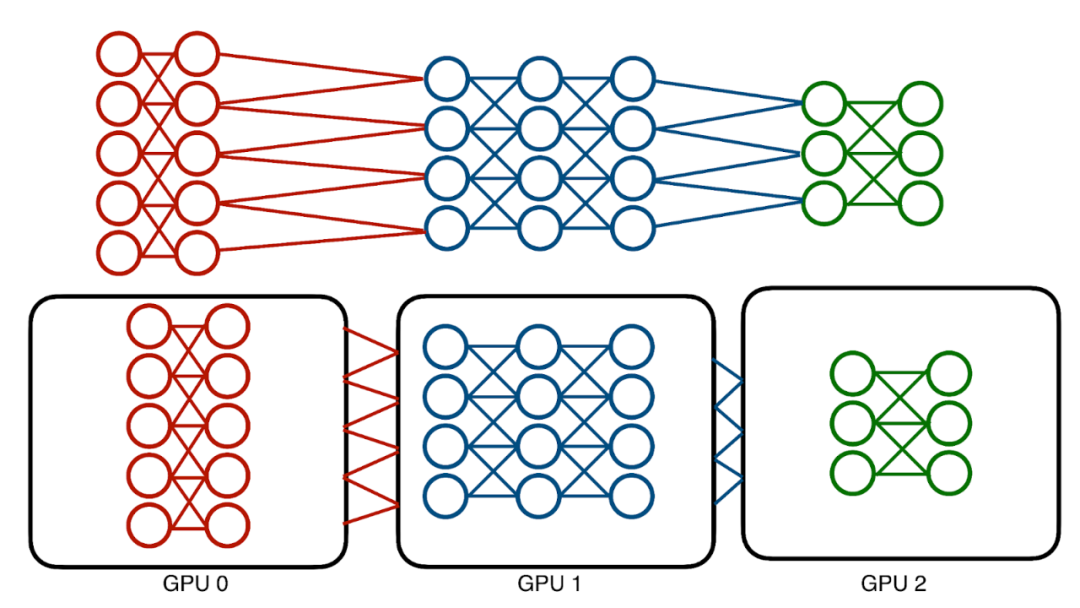
傳統模型并行化受到神經網絡架構序列性的影響。高效的并行化計算機會是有限的。
但是,這種技術也存在問題,即模型本質上是連續的,并且訓練模型需要在層間前向和后向地傳遞數據。因此,每次只能使用一個層和一個設備。這種情況將導致設備利用嚴重不足。
系統研究如何發揮助力作用呢?
以一個深度神經網絡為例,如果將其分解為最小的組件,則它可以被視為一系列轉換數據的算子。簡單地訓練意味著這樣一個過程:通過算子傳遞數據,產生梯度,再次通過算子將梯度反饋回來,最后更新算子。
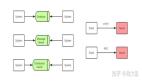
在這個層次分解之后,模型開始類似于其他階段式操作,比如 CPU 的指令 pipeline。谷歌于 2019 年在論文《 GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism 》中提出的 GPipe 系統和分布式任務處理系統 Hydra 試圖通過這種 CPU 并行指令將系統優化應用于可擴展性和并行性實現。
其中,GPipe 系統通過這種 CPU 并行指令將模型訓練轉變成了一個 pipeline 問題。模型的每個分區都被視為一個 pipe 的不同階段,并且 mini-batch 通過分區進行分級以實現利用效果最大化。
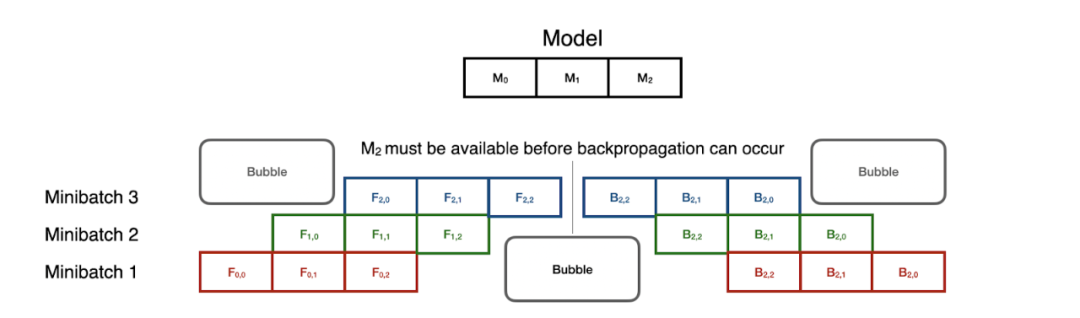
序列模型并行化中的 SOTA——pipeline 并行化可以并行處理 mini-batch 的訓練。但是,同步開銷非常高,尤其是在前向和后向傳遞的轉換過程中。
但是請注意,反向傳播通過相反的順序復用這些階段。這意味著:在前向 pipeline 完全暢通之前,反向傳播無法啟動。即便如此,這種技術可以將模型并行訓練加速至一個很好的水平,在 8 個 GPU 時速度提升 5 倍。
Hydra 則采用了另外一種方法,它將可擴展性和并行性分割為兩個不同的步驟。數據庫管理系統中的一個常見概念是溢出(spilling),多余數據被發送至內存層級結構的較低層次。Hydra 充分利用模型并行中的序列計算,并觀察到不活躍的模型分區不需要在 CPU 上處理。相反,Hydra 將不需要的數據溢出至 DRAM,在 GPU 上間斷性地切換模型分區,以模擬傳統的模型并行執行。
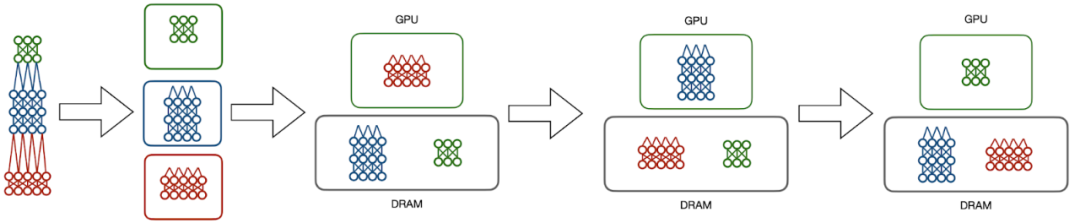
Hydra 的模型溢出技術將深度學習訓練的成本轉移至 DRAM 而不是 GPU 內存,同時保持了 GPU 執行的加速優勢。
這樣一來,一次只使用一個 GPU 就可以訓練模型。因此,在頂端引入一定程度的任務并行性很簡單。每個模型,無論它的大小如何,一次只需要一個 GPU,這樣系統可以充分利用每個 GPU。在 8 個 GPU 時可以實現 7.4 倍以上的近乎最優加速。
但是,模型并行只是系統研究為模型訓練所能帶來的開始,其他有潛力的貢獻包括數據并行(如 PyTorch DDP)、模型選擇(如 Cerebro 或模型選擇管理系統)、分布式執行框架(Spark 或 Ray)等。模型訓練是系統研究優化的成熟領域。
模型服務
歸根結底,構建機器學習模型最終是為了使用。模型服務與預測是最重要的機器學習實踐領域之一,也是系統研究產生最大影響的領域之一。
預測可以劃分為兩個主要設置:離線部署和在線部署:
- 離線部署相對更加直接,它涉及到單一的、不定期運行的大批量預測工作。常見的設置包含商業智能、保險評估和醫療健康分析;
- 在線部署屬于網絡應用,如果用戶想要自己的查詢得到快速響應,則需要快速、低延遲的預測。
離線部署和在線部署具有各自的需求和要求。通常來說,離線部署需要高通量的訓練過程以快速瀏覽大量的示例,在線部署在單一預測上需要極快的周轉時間,而不是一次進行多個預測。
系統研究已經重新塑造了處理離線和在線部署任務的方式。以加州大學圣地亞哥分校的研究者在論文《 Incremental and Approximate Computations for Accelerating Deep CNN Inference 》中提出的 Krypton 工具為例,它將視頻分析重新視作一項「多查詢優化任務(multi-query optimization, MQO)」任務。
MQO 不是一個新的領域,它是數十年來關系數據庫設計的一部分。總體思路很簡單:不同的查詢可能共享相關組件,然后可以保存和復用這些組件。Krypton 工具觀察到,CNN 推理通常是在批量相關圖像上完成,比如在視頻分析中。
一般來說,視頻是以高幀率生成,這樣一來,相鄰幀往往相對一致。幀 1 中的大部分信息依然出現在幀 2 中。這種情況與 MQO 明顯相同,即一系列任務之間共享信息。
Krypton 在第一幀上運行常規推理,然后具象或保存 CNN 在預測過程中產生的中間數據。隨后的圖像與第一幀進行比較以確定圖像中的哪些 patch 產生的變化足以值得重新計算。一旦確定了 patch,Krypton 通過 CNN 計算 patch 的「變化域」,以確定模型整個狀態中哪些神經元輸出發生了變化。這些神經元會根據變化的數據重新運行,其余的數據只需要從基礎幀中復用即可。
結果就是在推理負載上實現 4 倍以上的端到端加速,并且過期數據只有很小的準確率損失。這種運行時改進對于安全錄像視頻分析等長時間運行的流媒體應用來說至關重要。
Krypton 并不是唯一一個專注于模型推理的工具。加州大學伯克利分校的研究者在論文《 Clipper: A Low-Latency Online Prediction Serving System 》中提出的 Clipper 和 TensorFlow Extended 等其他工具利用系統優化和模型管理技術提供高效和魯棒的預測,從而解決了同樣的高效預測服務問題。