適用于計算機視覺的九大開源數據集
譯文【51CTO.com快譯】使用開源數據集訓練的計算機視覺模型
計算機視覺(CV)是人工智能(AI)和機器學習(ML)領域中最令人興奮的子領域之一。它是許多人工智能和機器學習管道的主要組成部分,它正在改變各行業領域,使組織能夠徹底改變機器和業務系統的工作方式。
從學術上來說,計算機視覺幾十年來一直是計算機科學的一個成熟領域,多年來,許多研究工作已經進入該領域以使其變得更加完善。然而,深度神經網絡的使用最近徹底改變了該領域,并為其加速增長提供了新的動力。
計算機視覺有多種應用領域,例如:
- 自動駕駛。
- 醫學影像分析和診斷。
- 場景檢測和理解。
- 自動生成圖像標題。
- 社交媒體上的照片/人臉標簽。
- 家庭安全。
- 制造業和質量控制中的缺陷識別。
本文將討論深度學習領域中使用的一些最流行和最有效的數據集,以訓練先進的機器學習系統以執行計算機視覺任務。
如何選擇正確的開源數據集
對機器進行圖像和視頻文件訓練是一項非常復雜的數據密集型操作。單一圖像文件是一個多維、多兆字節的數字實體,而在整個“智能圖像分析”任務的場景中僅包含一小部分“洞察力”。
相比之下,一個大小相似的零售銷售數據表可以在計算硬件相同的情況下,對機器學習算法有更多的了解。在談論現代計算機視覺管道所需的數據和計算規模時,需要記住這一事實。
因此,在幾乎所有情況下,數百張甚至數千張圖像并不能為計算機視覺任務訓練高質量的機器學習模型。幾乎所有現代計算機視覺系統都使用復雜的深度學習模型架構,如果沒有提供足夠數量的精心挑選的訓練示例(即標記圖像),將出現欠擬合的現象。因此,健壯的、可推廣的、高生產質量的深度學習系統通常需要數百萬張精心挑選的圖像進行訓練,這正在成為一種普遍的趨勢。
此外,對于視頻分析,考慮到從大量視頻流中獲得的視頻文件或幀的動態特性,選擇和編譯訓練數據集的任務可能會更加復雜。
本文列出了一些最流行的圖片(由靜態圖像和視頻剪輯組成)。
計算機視覺模型的流行開源數據集
并非所有數據集都同樣適用于各種計算機視覺任務。這些常見的任務包括:
- 圖像分類。
- 對象檢測。
- 對象分割。
- 多對象注釋。
- 圖像字幕。
- 人體姿勢估計。
- 視頻幀分析。
以下將介紹流行的開源數據集,其中涵蓋了大多數類別。
1.ImageNet(最著名)
ImageNet是一項持續進行的研究工作,旨在為世界各地的研究人員提供易于訪問的圖像數據庫。它可能是全球最著名的圖像數據集,并被研究人員和學習者引用為黃金標準。
該項目的靈感來自圖像和視覺研究領域不斷增長的需求——對更多數據的需求。它是根據WordNet層次結構組織的。WordNet中每個有意義的概念,可能由多個詞或短語描述,其名稱為“同義詞集”。WordNet中有10萬個以上同義詞集。同樣,ImageNet旨在提供平均1000張圖像來對每個同義詞集進行說明。
ImageNet大規模視覺識別挑戰賽(ILSVRC)是一項全球年度競賽,旨在評估算法(由大學或企業研究小組的團隊提交)以進行大規模的對象檢測和圖像分類。其中一個主要的動機是允許研究人員比較更廣泛對象的檢測進展——利用相當昂貴的標記工作。另一個動機是衡量計算機視覺在用于檢索和注釋的大規模圖像索引方面的進展。這是機器學習領域最受關注的年度競賽之一。

2.CIFAR-10(初學者)
這是計算機視覺領域初學者常用于訓練機器學習和計算機視覺算法的圖像集合。它也是機器學習研究中最受歡迎的數據集之一,用于快速比較算法,因為它可以捕捉特定架構的弱點和優勢,而不會給訓練和超參數調整過程帶來不合理的計算負擔。
它包含10個不同類別的6萬張32×32像素彩色圖像。這些類代表飛機、汽車、鳥類、貓、鹿、狗、青蛙、馬、輪船和卡車。

3.MegaFace和LFW(人臉識別)
野外標記人臉(LFW)是一個人臉照片數據庫,旨在研究無約束人臉識別問題。它包含5,749位人物的13,233張圖像,是從網絡上抓取和檢測到的。作為額外的挑戰,機器學習研究人員可以使用1,680位人物的圖片,這些人物在數據集中有兩張或更多不同的照片。因此,它是人臉驗證的公共基準,也稱為配對匹配(至少需要同一個人的兩張圖像)。
MegaFace是一個大規模開源的人臉識別訓練數據集,是商業人臉識別問題最重要的基準之一。它包括672,057名人物的4,753,320張面孔,非常適合大型深度學習架構訓練。所有圖像均從Flickr(雅虎的數據集)獲得并獲得共享許可。

4.IMDB-Wiki(性別和年齡識別)
它是規模最大的開源人臉圖像數據集之一,帶有用于訓練的性別和年齡標簽。該數據集中共有523,051張人臉圖像,其中460,723張人臉圖像來自IMDB的20,284位名人和維基百科的62,328位名人。

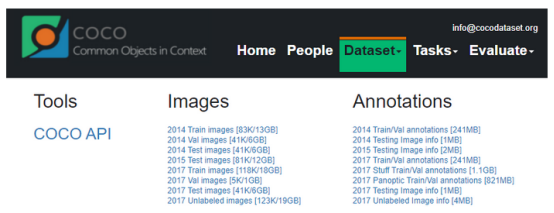
5.MSCoco(對象檢測和分割)
Common Objectsin CONtext(COCO)是大規模對象檢測、分割和字幕數據集。該數據集包含91種易于識別的對象類型的照片,在32. 8萬張圖像中共有250萬個標記實例。此外,它還為更復雜的計算機視覺任務提供資源,例如多對象標記、分割掩碼注釋、圖像字幕和關鍵點檢測。它得到了直觀的API的良好支持,該API有助于在COCO中加載、解析和可視化注釋。API支持多種注釋格式。
6.MPII人體姿勢(姿勢估計)
該數據集用于評估人體關節姿勢估計。它包括大約25,000張圖像,其中包含超過4萬名身體關節帶有注釋的人物。在這里,每張圖像都是從YouTube視頻中提取的,并提供前后未注釋的幀。總的來說,數據集涵蓋了410項人類活動,每個圖像都提供了一個活動標簽。

7.Flickr-30k(圖像字幕)
它是一個圖像字幕語料庫,由158,915個眾包字幕組成,描述了31,783張圖像。這是之前的Flickr 8k數據集的擴展。新的圖像和字幕側重于參與日常活動和事件的人物。

8.20BN-SOMETHING-SOMETHING(人類行為的視頻剪輯)
該數據集是大量密集標記的視頻剪輯,顯示人類對日常物品執行預定義的基本操作。它是由大量群組工作者創建的,它允許機器學習模型對物理世界中發生的基本動作進行細粒度的理解。
以下是這一數據集中捕獲的常見人類活動的子集:

9.Barkley DeepDrive(用于自動駕駛汽車訓練)
加州大學伯克利分校的伯克利DeepDrive數據集包含超過10萬個視頻序列,其中提供各種注釋,包括對象邊界框、可駕駛區域、圖像級標記、車道標記和全幀實例分割。此外,該數據集在表示各種地理、環境和天氣條件方面具有廣泛的多樣性。
這對于為自動駕駛汽車訓練強大的模型非常有用,這樣自動駕駛系統就不會對不斷變化的道路和駕駛條件感到困惑。

數據集的正確硬件和基準測試
毋庸置疑,只是擁有這些數據集不足以構建高質量的機器學習系統或業務解決方案。需要正確選擇數據集、訓練硬件以及巧妙的調優和基準測試策略,才能為任何學術或商業問題獲得最佳解決方案。
這就是為什么高性能GPU幾乎總是與這些數據集配對以提供所需性能的原因。
GPU的開發(主要迎合視頻游戲行業)使用數千個微型處理器進行大規模并行計算。它們還具有大內存帶寬來處理快速數據流(處理單元緩存到較慢的主內存并返回),當神經網絡進行大量訓練時,處理數據流需要進行更多的計算。這使它們成為處理計算機視覺任務計算負載的理想硬件。
然而,市場上有很多GPU可供選擇,并且市場上已經提供了一些很好的基準策略,以在這方面指導潛在用戶。一個良好的基準測試必須考慮多種類型,例如深度神經網絡(DNN)架構、GPU和廣泛使用的數據集。
例如,一篇優秀文章考慮了以下內容:
- 架構:ResNet-152、ResNet-101、ResNet-50和ResNet-18。
- GPU:EVGA RTX2080ti、技嘉RTX2080ti和NVIDIA TITAN RTX。
- 數據集:ImageNet、CIFAR-100和CIFAR-10。
此外,必須考慮性能的多個維度才能獲得良好的基準。
要考慮的GPU性能維度有三個主要指標:
(1)第二批時間:完成第二批訓練的時間。這個數字衡量的是GPU運行足夠長的時間來加強之前的性能。沒有考慮GPU的熱節流。
(2)平均批處理時間:ImageNet中1個歷元(epoch)或CIFAR中15個歷元(epoch)后的平均批處理時間。考慮了GPU的熱節流。
(3)同步平均批處理時間:ImageNet中1個epoch或CIFAR中15個epoch后的平均批處理時間,所有GPU同時運行。這測量了所有GPU發出的熱量而導致系統中的熱節流效應。
哪些開源數據集最適合計算機視覺模型?
本文討論了獲得高質量、無噪聲、大規模數據集以訓練復雜深度神經網絡(DNN)模型的必要性,這些模型在計算機視覺應用中逐漸普及。
還給出了多個開源數據集的示例,這些數據集廣泛用于各種類型的計算機視覺任務——圖像分類、姿態估計、圖像字幕、自動駕駛、對象分割等。
最后,還討論了將這些數據集與適當的硬件和基準策略配對的必要性,以確保它們在商業和研發領域的最佳使用。
原文標題:Open Source Datasets for Computer Vision,作者:Kevin Vu
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】