我的系統有bug?你可得有證據!
本文轉載自微信公眾號「小姐姐味道」,作者小姐姐養的狗。轉載本文請聯系小姐姐味道公眾號。
你要知道,在線下、在測試開發環境能夠發現的bug,都是些小兒科。只有到了線上才發生的bug,你才會知道它的兇殘。數據錯亂,邏輯中斷,進程死亡。處在如此問題場景下的你,are you ok?
問題頻繁發生,故障難以定位,CTO怒而呵斥,“你們難道不能在線上調試一下問題的發生根本么?要形成一套可行的方法論!”
從這種訓話可以看出,CTO的技術水準一般,但太極修養十分了得。在平常的表達中,在一篇報告中,不要出現技術術語,不要把話說的太死,是一個CTO基本的素養。
但是活兒總是要有人干的,公司所有人都打太極,最后將形成一個虛幻的世界,不利于整個組織的健康發展。今天,我們就簡單的聊一下線上程序,要留下哪些證據。
1. 證據
問題之所以成為問題,是因為它留下了證據。沒有證據的問題,你雖然看到了影響結果,但是你無法找到元兇。比如,某個同學在辦公室的飲水機里放了巴豆,讓所有同事都暢快淋漓的發泄了一下。但由于沒有安裝監控,你也就無法找到這個可惡的同學。
而且問題通常都具有人性化,當它發現無法發現它的時候,它總會再次出現。就如同罪犯發現了漏洞,還會再次嘗試利用它。
所以,要想處理線上問題,你需要留下問題發生的證據,這是重中之重。如果沒有這些東西,你的公司,絕對會陷入無盡的扯皮之中。
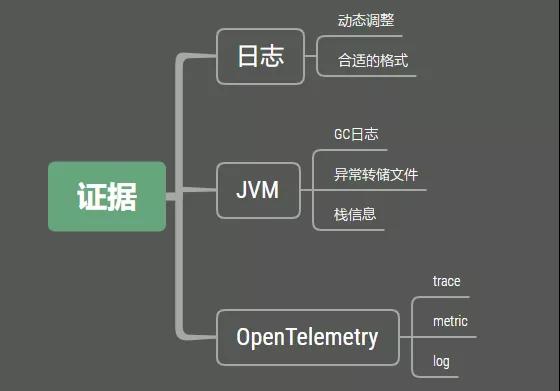
1.1 日志證據
日志是最常見的作法。通過在程序邏輯中進行打點,配合Logback等日志框架,可以快速定位到發生問題的代碼行。我們需要看一下bug的詳細發生過程,對可能發生問題的邏輯進行詳細的日志記錄,進行更加細致的日志輸出,在發生問題的時候,就可以切換到debug進行調試。
在SpringBoot中,可以通過actuator來動態調整相應類的日志級別。在下面的路徑中,可以看到日志級別的具體信息。
- localhost:8080/actuator/{loggers}
通過發送POST請求到具體的日志控制器,就可以實現動態更改。
- curl -X POST \
- http://localhost:8080/actuator/loggers/<Package/Class> \
- -d '{"configuredLevel":"<LEVEL>"}'
但bug的發生頻率可能很小,我們開啟了debug后,可能等了好幾天,同樣的問題也沒有再次復現,這是最讓人頭疼的事情。
接入一些APM平臺是非常有必要的。最新的opentelemetry,同時記錄了Traces, Metrics, Logs等三種格式的數據,對問題的分析支持非常大。
記錄詳細的監控信息也是非常有必要的,可以看到監控指標的歷史時序,輔助我們查找排查問題。
1.2 JVM證據
在事故出現的時候,通常并不是那么溫柔。你可能在半夜里就能接到報警電話,這是因為很多定時任務都設定在夜深人靜的時候執行。
這個時候,再去看 jstat 已經來不及了,我們需要保留現場。這個便是看門狗的工作,看門狗可以通過設置一些 JVM 參數進行配置。
Java8的gc日志配置和8以后的版本差異很大,下面直接給出相應的配置示例。
java8:
- -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps
- -XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistribution
- -Xloggc:/tmp/logs/gc_%p.log -XX:+HeapDumpOnOutOfMemoryError
- -XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log
- -XX:-OmitStackTraceInFastThrow
java8+:
- -verbose:gc -Xlog:gc,gc+ref=debug,gc+heap=debug,gc+age=trace:file
- =/tmp/logs/gc_%p.log:tags,uptime,time,level -Xlog:safepoint:file=/tmp
- /logs/safepoint_%p.log:tags,uptime,time,level -XX:+HeapDumpOnOutOfMemoryError
- -XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log
- -XX:-OmitStackTraceInFastThrow
2. 分析
問題分析是最困難的一環。有了證據環節,我們就避免了靠猜去找問題的現狀,但如何在這些分散的信息和復雜的路徑中,找到問題的根本原因,是非常有挑戰的。
如果是大范圍的bug,那么強烈建議直接在線上進行調試。不太推薦使用Arthas等工具動態的修改字節碼進行測試,當然也不推薦IDEA的遠程調試。相反,推薦使用類似金絲雀發布的方式,導出非常小的一部分流量,構造一個新的版本進行測試。如果你沒有金絲雀發布平臺,類似Nginx的負載均衡工具也可以通過權重做到類似的事情。
在這個新的小版本中,你可以盡情的輸出日志,把所有的輸入輸出都打印到日志里。大多數情況下,你能夠通過日志很快發現這個問題。
緩存會是bug產生非常重要的一個影響因素。因為緩存和db通常不在一個基礎設施中,通常會存在一致性問題。即使選用了cache aside pattern,實現了延時雙刪,在某些情況下,數據仍然會發生一致性問題。這種偶發的不一致問題,因為發生頻率低,觸發條件苛刻,一點發生會非常難以發現。所以一些非常關鍵的業務,通常會提供一鍵刪除緩存的功能。如果清掉緩存之后,問題消失,那大可不必浪費時間花費在這種小概率事件上。
多線程是另外一個容易出現問題的地方,每個邏輯都必須仔細的進行評估。因為多線程是異步的,有些邏輯只能通過手工去推理,灰度的線上程序可能永遠沒有條件走到這一步。這個時候,給線程起一個合適的名字,是非常有必要的,這通常是由ThreadFactory去做的。
比如,有些同學,喜歡將字符串拼接起來直接打印成日志。
- logger.debug("the request info: userId:{} tel:{},role:{},timeCost:{}")
這二種方式不是說不好,但在你處理問題的時候,就會遇到很多障礙,日志的輸出不應該太隨意。
- logger.debug("the request info$ userId{}|tel:{}|role:{}|timeCost:{}")
通過這種方式,我們可以很容易的利用各種Linux工具,比如sed、awk、grep進行分析。在日志輸出的時候,要有一定的技巧,否則你就只能使用肉眼去分析。
3. 總結
要想解決問題,就得通過不斷的試錯。試錯并不是盲目的,我們必須要有各種證據的支持。手機證據最有效的是通過日志,尤其是有一定規律的日志信息。除了分析正常的業務邏輯,數據問題或者多線程問題,同樣是常見的bug引起原因。
日志系統與監控系統,對硬件的需求是比較大的,尤其是你的請求體和返回體比較大的情況下,對存儲和計算資源的額要求更是高。它的硬件成本,在整個基礎設施中,占比也是比較高的。但這些證據信息,對分析問題來說,是非常有必要的。所以即使比較貴,很多公司依然會有很大的投入在這上面,包括硬件投入和人力投入。
如果你想要這樣的功能但是沒錢也沒人?其實那也沒關系,雇一個會扯皮的CTO,你的這些問題和bug,都會在你面前消失不見的。
作者簡介:小姐姐味道 (xjjdog),一個不允許程序員走彎路的公眾號。聚焦基礎架構和Linux。十年架構,日百億流量,與你探討高并發世界,給你不一樣的味道。