Hadoop、Spark、Hive到底是什么,做算法要不要學?
大家好,我是梁唐。
最近我發(fā)現(xiàn),很多萌新說著想要做算法工程師,但是卻對這個崗位的要求以及工作內(nèi)容一無所知。以為學一個Python,再學一些機器學習、深度學習的模型就可以勝任了。工作就是用Python不停地寫模型。
顯然,這樣的想法是有問題的,如果真這么干,即使通過了面試成功入職,也會干得非常痛苦。因為你會發(fā)現(xiàn)這也不知道那也不知道,做啥都很吃力,需要一段很長的時間學習。而這種為了應(yīng)付工作臨時抱佛腳的學習往往很難深入,有種不停打補丁的感覺。
今天就和大家聊聊算法工程師的幾項基本功,看看除了算法和模型之外,還需要學些什么。
hadoop
首先當然是hadoop,不過hadoop不是一門技術(shù),而是一個大數(shù)據(jù)框架。它的logo是一只黃色的小象,據(jù)說是這個項目的創(chuàng)建者用女兒的玩具命名的。

經(jīng)過了很多年的發(fā)展,現(xiàn)在hadoop框架已經(jīng)非常成熟,衍生出了一個龐大的家族。有多龐大呢,我在google里給大家找了一張圖,大家可以看看感受一下,這里面有多少是自己知道的,有多少沒聽說過。

當然對于算法工程師來說,hadoop家族并不需要全部了解,只需要著重關(guān)注幾個就可以了。
hdfs
首先是hdfs,hdfs是hadoop框架中的分布式文件系統(tǒng)。因為在工業(yè)場景當中,數(shù)據(jù)量是非常龐大的,動輒TB甚至是PB量級。如此龐大的數(shù)據(jù),顯然不可能存在一塊磁盤里,必須要分布式存儲,分成不同的部分,不同的部分分開存儲。通過hdfs我們可以很方便地實現(xiàn)這一點,可以使用一些簡單的shell命令管理大規(guī)模的數(shù)據(jù)。
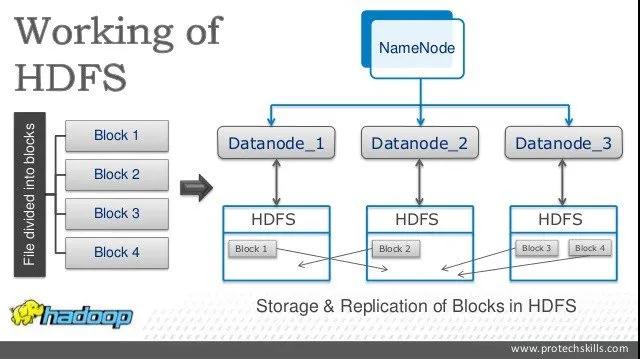
hdfs的內(nèi)部是分片(block)存儲的,并且設(shè)計了嚴謹?shù)娜蒎e機制,盡可能地保證了數(shù)據(jù)的準確性。一般我們用hdfs存儲一些離線數(shù)據(jù),也就是對延遲要求不高的數(shù)據(jù),比如模型的訓(xùn)練數(shù)據(jù)。它的特點是存儲能力很強,但是讀取速度很慢,中間的延遲很長。
因為訓(xùn)練數(shù)據(jù)的規(guī)模往往也非常龐大,并且從用戶線上的實時行為轉(zhuǎn)化成模型需要的輸入,中間需要大量的計算步驟。這會帶來巨大的計算壓力,因此對于這樣的數(shù)據(jù),我們往往都是借助于hdfs做離線處理。設(shè)計一套數(shù)據(jù)處理流程,進行若干步驟的處理,每一步處理的中間數(shù)據(jù)都存儲在hdfs上。
模型訓(xùn)練的時候,也通過掛載hdfs的方式直接讀取tensor進行訓(xùn)練。
MapReduce
hdfs是hadoop的存儲系統(tǒng),hadoop同樣也推出過一套計算系統(tǒng),就是MapReduce。
我在之前的文章曾經(jīng)介紹過MapReduce的原理,其實非常簡單,它將數(shù)據(jù)的計算過程抽象成了兩個步驟。一個步驟叫map,一個步驟叫reduce。
map步驟做的數(shù)據(jù)的映射,比如我們從一個很大的json文件當中讀取出我們想要的字段,在這個步驟當中,我們從json獲得了幾個字段。
reduce步驟做的是匯總,我們把剛剛map階段得到的結(jié)果,按照我們的想法匯聚在一起,比如計算平均數(shù)、中位數(shù)等等。
這個想法巧妙的地方在于map和reduce都是可以分布式進行的,比如map階段,我們可以對hdfs里的每一個文件都設(shè)置一個map讀取文件進行處理。map階段結(jié)束之后,我們也可以起多個reducer對map的結(jié)果進行加工,盡可能導(dǎo)致了整個過程都是并發(fā)進行的,也就保證了數(shù)據(jù)的處理速度。
雖然MapReduce的提出到現(xiàn)在已經(jīng)十多年了,但仍然沒有淘汰,還在很多場景當中廣泛使用。
hive
hive也是hadoop家族核心的一員,它的思想也很巧妙,做了一件非常有利于程序員的事情。

使用hdfs以及MapReduce其實就足夠應(yīng)付幾乎所有大數(shù)據(jù)計算的場景了,但是足夠應(yīng)付并不代表應(yīng)付起來很舒服。有些場景使用起來就不是很順手,比如說我們要把兩份數(shù)據(jù)關(guān)聯(lián)在一起,一份是用戶點擊數(shù)據(jù),一份是商品數(shù)據(jù),我們想要得到用戶點過的商品信息。
你會發(fā)現(xiàn)使用MapReduce去做這樣一件事情會非常蛋疼,要寫很多代碼。所以有人突發(fā)奇想,我們能不能利用hdfs以及MapReduce做一套好用一點的數(shù)據(jù)處理系統(tǒng),比如說將數(shù)據(jù)全部格式化,然后像是數(shù)據(jù)庫一樣使用SQL來進行數(shù)據(jù)的查詢和處理?于是就有了hive。
hive底層的運算框架就是MapReduce,只不過有了表結(jié)構(gòu)之后,很多之前很復(fù)雜的操作被大大簡化了。尤其是數(shù)據(jù)表之間的join、group by等操作,之前需要寫大量MapReduce的代碼,現(xiàn)在幾行SQL就搞定了。
不過hive畢竟不是數(shù)據(jù)庫,它的使用還是有一些它自己專屬的奇淫技巧。比如說避免數(shù)據(jù)傾斜的情況,比如說設(shè)置合理的內(nèi)存分片,比如說udf的使用等等。
只是懂SQL的語法是寫不好hive的,多少還需要做一些深入的了解。
spark
說到spark相信很多同學也是久仰大名,它是一個非常著名的開源集群計算框架,也可以理解成一個分布式計算框架。

spark在MapReduce的基礎(chǔ)上對MapReduce當中的一些問題進行了優(yōu)化,比如MapReduce每次運算結(jié)束之后都會把數(shù)據(jù)存儲在磁盤上,這會帶來巨大的IO開銷。
而spark使用了存儲器內(nèi)運算技術(shù),可以盡量減少磁盤的寫入。這其中的技術(shù)細節(jié)看不懂沒有關(guān)系,我們只需要知道它的運算性能比MapReduce快很多就可以了,一般來說運算速度是MapReduce的十倍以上。并且spark原生支持hdfs,所以大部分公司都是使用hdfs做數(shù)據(jù)存儲,spark來進行數(shù)據(jù)運算。
在hadoop推出了hive之后,spark也推出了自己的spark SQL。不過后來hive也支持使用spark作為計算引擎代替MapReduce了,這兩者的性能上差異也就很小了,我個人還是更喜歡hive一點,畢竟寫起來方便。
另外spark除了計算框架之外,當中也兼容了一些機器學習的庫,比如MLlib,不過我沒有用過,畢竟現(xiàn)在機器學習的時代都快結(jié)束了。很少再有使用場景了,大家感興趣也可以了解一下。
總結(jié)
最后做一個簡單的總結(jié),總體上來說想要成為一名合格的算法工程師,hadoop、MapReduce、hive這些或多或少都需要有所了解。不說能夠精通到原理級,但至少需要會用,大概知道里面怎么回事。
這也是工業(yè)界和實驗室里的最大區(qū)別,畢竟學校里的實驗數(shù)據(jù)量也不會很大,直接放在內(nèi)存里就完事了。所以數(shù)據(jù)處理一般都是numpy + pandas什么的,但是在公司里,幾乎沒有pandas的用武之地,畢竟數(shù)據(jù)量太大了,不可能都放內(nèi)存里,必須要借助大數(shù)據(jù)計算平臺來解決。
好了,就說這么多吧,感謝大家的閱讀。
本文轉(zhuǎn)載自微信公眾號「Coder梁」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系Coder梁公眾號。