













一篇帶給你 Kubectl 高效使用技巧
在學習如何更高效地使用 kubectl 之前,你應該對它是如何工作的有個基本的了解。kubectl 是 Kubernetes 集群的控制工具,它可以讓你執行所有可能的 Kubernetes 操作。
從技術角度上看,kubectl 是 Kubernetes API 的客戶端,Kubernetes API 是一個 HTTP REST API,這個 API 是真正的 Kubernetes 用戶界面,Kubernetes完全受這個 API 控制,這意味著每個 Kubernetes 操作都作為 API 端點暴露,并且可以由對此端點的 HTTP 請求執行,因此,kubectl 的主要工作是執行對 Kubernetes API 的 HTTP 請求:
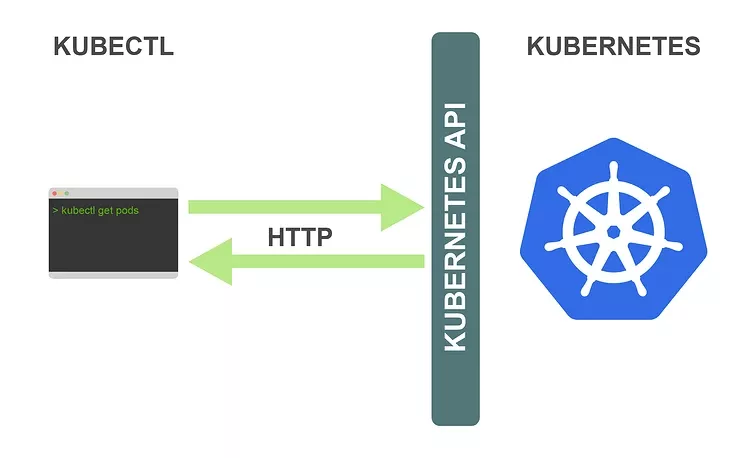
Kubernetes 是一個完全以資源為中心的系統,Kubernetes 維護資源的內部狀態并且所有的 Kubernetes 操作都是針對這些資源的 CRUD(增加、查詢、更新、刪除)操作,你完全可以通過操控這些資源來控制Kubernetes。
比如我們想要創建一個 ReplicaSet 資源,在一個名為 replicaset.yaml 的文件中定義 ReplicaSet 資源對象,然后運行以下命令:
- kubectl create -f replicaset.yaml
Kubernetes 有一個創建 ReplicaSet 的操作,并且它和其他所有 Kubernetes 操作一樣,都會作為 API 端點暴露出去,對于我們這里的操作而言,該 API 端點如下:
- POST /apis/apps/v1/namespaces/{namespace}/replicasets
當我們執行上述命令時,kubectl 將向上述 API 端點發出一個 HTTP POST 請求。ReplicaSet 的資源清單內容在請求的 body 中傳遞。這就是 kubectl 與 Kubernetes 集群交互的所有命令的最基本的工作方式,kubectl 只需向對應的Kubernetes API 端點發出 HTTP 請求即可。
所以我們完全完全也可以使用 curl、postman 之類的工具來控制 Kubernetes,Kubectl 只是讓我們可以更輕松地訪問 Kubernetes API。
執行了上面的資源創建命令之后,API server 將會在 etcd 保存 ReplicaSet 資源定義。然后會觸發 controller manager 中的 ReplicaSet controller,后者會一直watch ReplicaSet 資源的創建、更新和刪除。ReplicaSet controller 為每個 ReplicaSet 副本創建了一個 Pod 定義(根據在 ReplicaSet 定義中的Pod模板創建)并將它們保存到存儲后端。Pod 創建后會觸發了 scheduler,它一直 watch 尚未被分配給 worker 節點的 Pod。
Scheduler 為每個 Pod 選擇一個合適的 worker 節點,并在存儲后端中添加該信息到 Pod 定義中。這觸發了在 Pod 所調度到的 worker 節點上的kubelet,它會監視調度到其 worker 節點上的 Pod。Kubelet 從存儲后端讀取 Pod 定義并指示容器運行時來運行在 worker 節點上的容器。這樣我們的 ReplicaSet 應用程序就運行起來了。
熟悉了這些流程概念后會在很大程度上幫助我們更好地理解 kubectl 并利用它。接下來,我們來看一下具體的技巧,來幫助你提升 kubectl 的生產力。
命令補全
命令補全是提高 kubectl 生產率的最有用但經常被忽略的技巧之一。命令補全功能使你可以使用 Tab 鍵自動完成 kubectl 命令的各個部分。這適用于子命令、選項和參數,包括諸如資源名稱之類難以鍵入的內容。命令補全可用于 Bash 和 Zsh Shell。
官方文檔 https://kubernetes.io/docs/tasks/tools/#enabling-shell-autocompletion 中其實就有關于命令補全的說明。
命令補全是通過補全腳本而起作用的 Shell 功能,補全腳本本質上是一個 shell 腳本,它為特定命令定義了補全行為。通過輸入補全腳本可以補全相應的命令。Kubectl 可以使用以下命令為 Bash 和 Zsh 自動生成并 print out 補全腳本:
- kubectl completion bash
- # or
- kubectl completion zsh
理論上,在合適的 shell(Bash或Zsh)中提供此命令的輸出將會啟用 kubectl 的命令補全功能。在 Bash 和 Zsh 之間存在一些細微的差別(包括在 Linux 和 macOS 之間也存在差別)。
Bash
Linux
Bash 的補全腳本主要依賴 bash-completion 項目,所以你需要先安裝它。我們可以使用不同的軟件包管理器安裝 bash-completion,如:
- # ubuntu
- apt-get install bash-completion
- # or centos
- yum install bash-completion
你可以使用以下命令測試 bash-completion 是否正確安裝:
- type _init_completion
如果輸出的是 shell 的代碼,那么 bash-completion 就已經正確安裝了。如果命令輸出的是 not found 錯誤,你必須添加以下命令行到你的 ~/.bashrc 文件:
- source /usr/share/bash-completion/bash_completion
你是否需要添加這一行到你的 ~/.bashrc 文件中,取決于你用于安裝 bash-completion 的軟件包管理器,對于 APT 來說,這是必要的,對于 yum 則不是。
bash-completion 安裝完成之后,你需要進行一些設置,以便在所有的 shell 會話中獲得 kubectl 補全腳本。一種方法是將以下命令行添加到 ~/.bashrc 文件中:
- source <(kubectl completion bash)
另一種是將 kubectl 補充腳本添加到 /etc/bash_completion.d 目錄中(如果不存在,則需要先創建它):
- kubectl completion bash > /etc/bash_completion.d/kubectl
/etc/bash_completion.d 目錄中的所有補全腳本均由 bash-completion 自動提供。
以上兩種方法都是一樣的效果。重新加載 shell 后,kubectl 命令補全就能正常工作了,這個時候我們可以使用 tab 來補全信息了。
Mac
使用 macOS 時,會有些復雜,因為默認的 Bash 版本是3.2,而 kubectl 補全腳本至少需要 Bash 4.1,蘋果依舊在 macOS 上默認使用過時的 Bash 版本是因為更新版本的 Bash 使用的是 GPLv3 license,而蘋果不支持這一 license。
所以要在 macOS 上使用 kubectl 命令補全功能,你必須安裝較新版本的 Bash。我們可以用 Homebrew 安裝/升級:
- brew install bash
重新加載 shell,并驗證所需的版本已經生效:
- echo $BASH_VERSION $SHELL
在繼續剩下的步驟之前,確保你現在已經在使用 Bash 4.1 或更高的版本(可以使用 bash --version 查看版本)。
同上一部分一樣,Bash 的補全腳本主要依賴 bash-completion 項目,所以你需要先安裝它。我們可以使用 Homebrew 安裝 bash-completion:
- brew install bash-completion@2
@2 代表 bash-completion v2 版本,Kubectl 補全腳本要求 bash-completion v2,而 bash-completion v2 要求至少是Bash 4.1,這就是你不能在低于 4.1 的 Bash 版本上使用 kubectl 補全腳本的原因。
brew intall 命令的輸出包括一個 Caveats 部分,其中的說明將以下行添加 ~/.bash_profile 文件:
- export BASH_COMPLETION_COMPAT_DIR=/usr/local/etc/bash_completion.d
- [[ -r "/usr/local/etc/profile.d/bash_completion.sh" ]] && . "/usr/local/etc/profile.d/bash_completion.sh"
必須執行此操作才能完成 bash-completion 的安裝,當然最好將上面的內容添加到 ~/.bashrc 文件中。重新加載 shell 之后,你可以使用以下命令測試 bash-completion 是否正確安裝:
- type _init_completion
如果輸出為 shell 功能的代碼,意味著一切都設置完成。現在,你需要進行一些設置,以便在所有的 shell 會話中獲得 kubectl 補全腳本。一種方法是將以下命令行添加到 ~/.bashrc 文件中:
- source <(kubectl completion bash)
另一種方法是將 kubectl 補全腳本添加到 /usr/local/etc/bash_completion.d 目錄中:
- kubectl completion bash >/usr/local/etc/bash_completion.d/kubectl
僅當你使用 Homebrew 安裝了 bash-completion 時,此方法才有效。在這種情況下,bash-completion 會在此目錄中提供所有補全腳本。如果你還用 Homebrew 安裝了kubectl,則甚至不必執行上述步驟,因為補全腳本應該已經由 kubectl Homebrew 放置在 /usr/local/etc/bash_completion.d 目錄中。在這種情況下,kubectl 補全應該在安裝 bash-completion 后就可以生效了。
重新加載 shell 后,kubectl 自動補全也就生效了。
Zsh
Zsh 的補全腳本沒有任何依賴項,所以配置要簡單很多,我們可以通過添加以下命令到你的 ~/.zshrc 文件中來實現這一效果:
- source <(kubectl completion zsh)
如果在重新加載你的 shell 之后,你獲得了 command not found: compdef 錯誤,你需要啟動內置的 compdef,你可以在將以下行添加到開始的 ~/.zshrc 文件中:
- autoload -Uz compinit
- compinit
此外我們還可以為 kubectl 定義一個別名,比如定義成 k:
- echo 'alias k=kubectl' >> ~/.zshrc
如果定義了別名也可以通過擴展 shell 補全來兼容該別名:
- echo 'complete -F __start_kubectl k' >> ~/.zshrc
另外還推薦配置 zsh 下面的 zsh-autosuggestions、zsh-syntax-highlighting、kubectl 這幾個插件,可以自動提示之前我們使用過的一些歷史命令,在 ~/.zshrc 中添加插件配置:
- plugins=(git zsh-autosuggestions zsh-syntax-highlighting kubectl)
查看資源規范
當你創建 YAML 資源定義時,你需要知道字段以及這些資源的意義,kubectl 提供了 kubectl explain 命令,它可以在終端中正確地輸入所有資源規范。
kubectl explain的用法如下:
- kubectl explain resource[.field]...
該命令輸出所請求資源或字段的規范,默認情況下,kubectl explain 僅顯示單個級別的字段,你可以使用 --recursive 標志來顯示所有級別的字段:
- kubectl explain deployment.spec --recursive
如果你不確定哪個資源名稱可以用于 kubectl explain,你可以使用以下命令查看:
- kubectl api-resources
該命令以復數形式顯示資源名稱(如 deployments),它同時顯示資源名稱的縮寫(如 deploy),這些名稱對于 kubectl 都是等效的,我們可以使用它們中的任何一個。例如,以下命令效果都是一樣的:
- kubectl explain deployments.spec
- # or
- kubectl explain deployment.spec
- # or
- kubectl explain deploy.spec
自定義列輸出格式
kubectl get 命令默認的輸出方式如下(該命令用于讀取資源):
- ➜ ~ kubectl get pods
- NAME READY STATUS RESTARTS AGE
- nfs-client-provisioner-54f4485448-kwr45 1/1 Running 1 67d
- nginx-674ff86d-t6gbd 1/1 Running 0 67d
默認的輸出格式包含有限的信息,我們可以看到每個資源僅顯示了一些字段,而不是完整的資源定義。此時,自定義列輸出格式就非常有用了,它使你可以自由定義列和想在其中顯示的數據,你可以選擇資源的任何字段,使其在輸出中顯示為單獨的列。自定義列輸出選項的用法如下:
- -o custom-columns=<header>:<jsonpath>[,<header>:<jsonpath>]...
你必須將每個輸出列定義為 <header>:<jsonpath> 對:
- <header> 是列的名稱,你可以選擇任何所需的內容
- <jsonpath> 是一個選擇資源字段的表達式
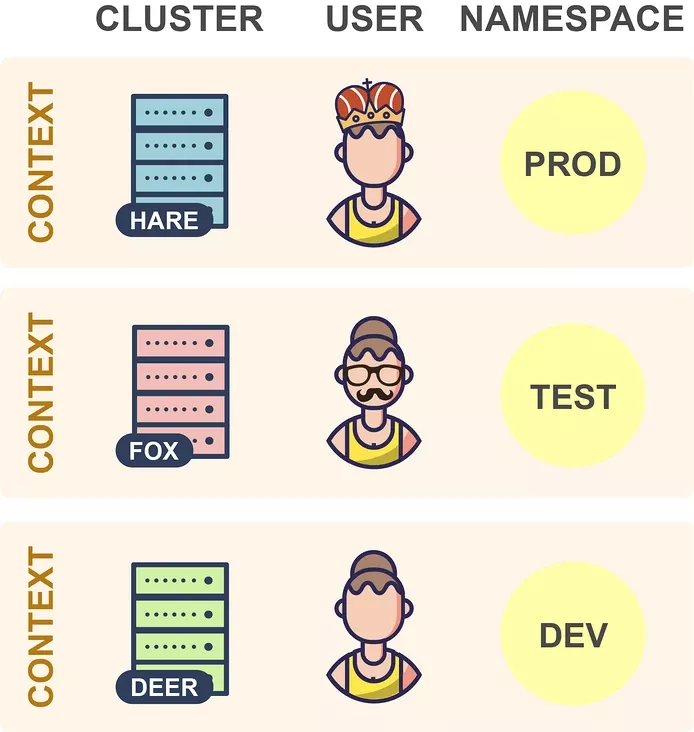
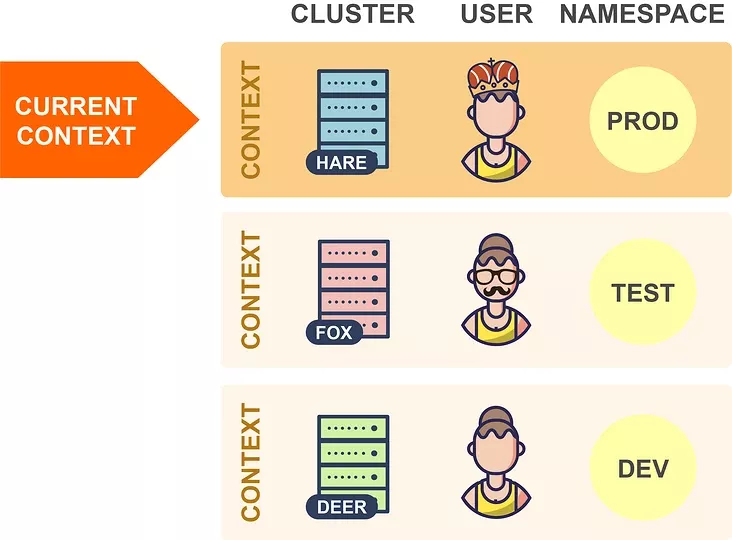
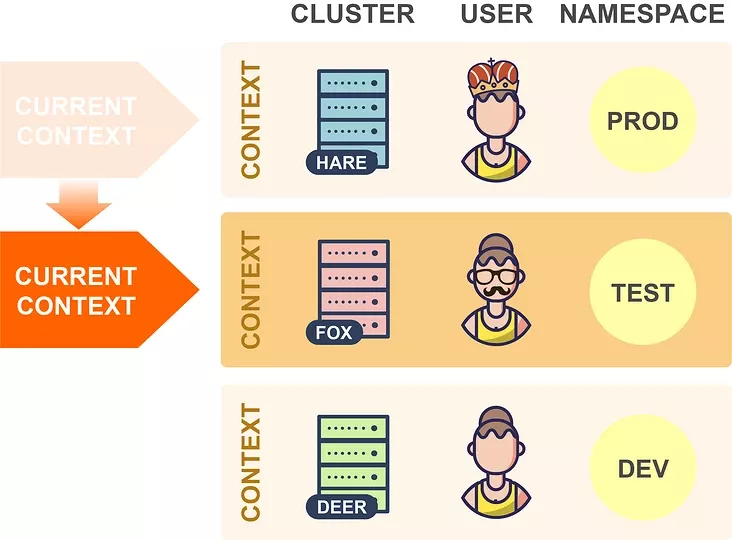
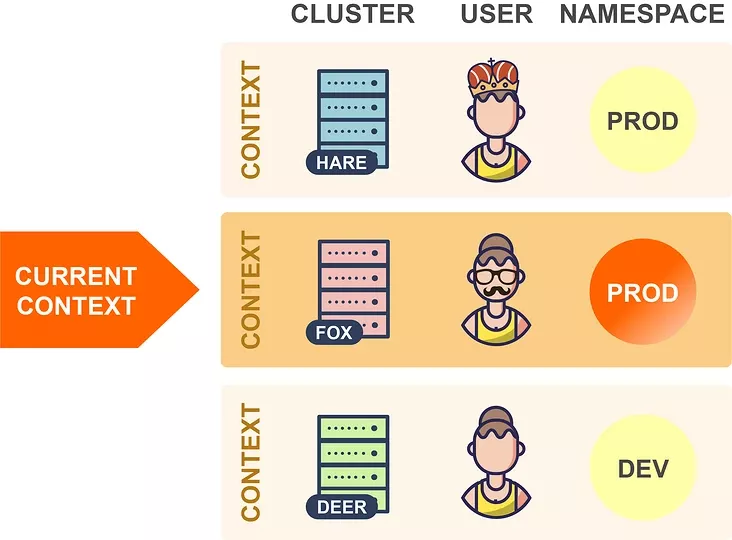
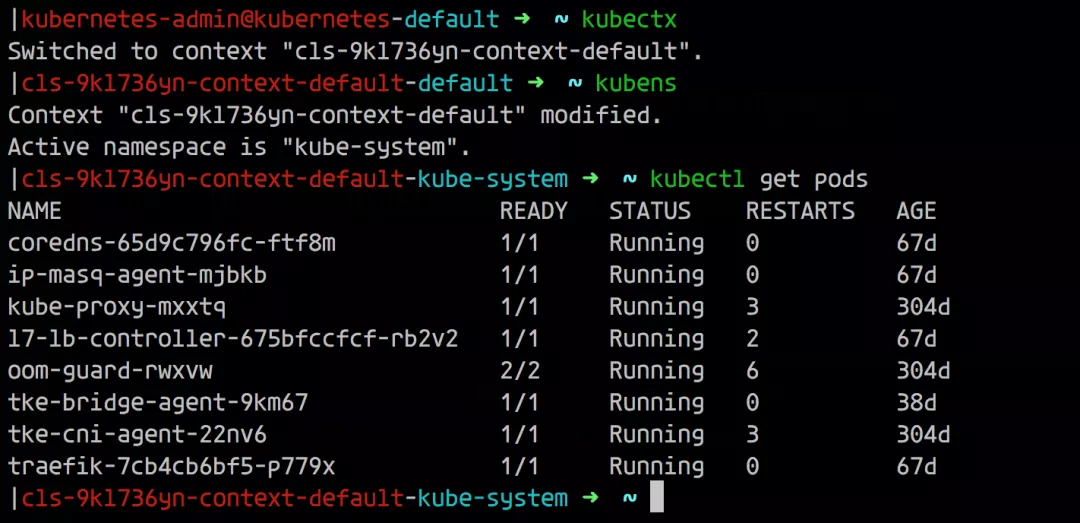
讓我們看一個簡單的例子: 在這里,輸出包括顯示所有 Pod 名稱的一列,選擇 Pod 名稱的表達式是 meta.name,因為 Pod 的名稱是在 Pod 資源的 metadata 屬性下面的 name 字段中定義的(我們可以使用 kubectl explain pod.metadata.name 進行查找)。 現在,假設你想在輸出中添加一個附加列,比如顯示每個 Pod 在其上運行的節點,那么我們只需在自定義列選項中添加適當的列規范即可: 選擇節點名稱的表達式是 spec.nodeName,這是因為已將 Pod 調度的節點保存在 Pod 的 spec.nodeName 字段中了。不過需要請注意的是 Kubernetes 資源字段是區分大小寫的。 我們可以通過這種方式將資源的任何字段設置為輸出列,只需瀏覽資源規范并嘗試使用任何你喜歡的字段即可。當然我們需要對字段選擇的 JSONPath 表達式要有一定的了解。 用于選擇資源字段的表達式基于 JSONPath 的。JSONPath 是一種用于從 JSON 文檔提取數據的語言(類似于 XPath for XML),選擇單個字段只是 JSONPath 的最基本用法,它還有很多其他功能,例如 list selector、filter 等。 但是,kubectl explain 僅支持 JSONPath 功能的子集,下面我們通過一些示例用法來總結下這些使用規則: 選擇一個列表的指定元素 選擇匹配過濾表達式的列表元素 選擇指定位置下的所有字段 選擇所有具有指定名稱的字段,無論其位置如何 其中的 [ ] 運算符特別重要,Kubernetes 資源的許多字段都是列表,使用此運算符可以選擇這些列表中的某一些元素,它通常與通配符一起使用 [*],以選擇列表中的所有項目。 使用自定義列輸出格式有無限可能,因為你可以在輸出中顯示資源的任何字段或字段組合。以下是一些示例應用程序,但你可以自己探索并找到對你有用的應用程序。 提示:如果你經常使用這些命令,則可以為其創建一個 shell 別名。 此命令顯示每個 Pod 的所有容器鏡像的名稱。因為一個 Pod 可能包含多個容器。在這種情況下,單個 Pod 的容器鏡像在同一列中顯示為由逗號分隔的列表。 如果你的 Kubernetes 集群部署在公有云上,則此命令很有用,它顯示每個節點所在的可用區。每個節點的可用區均通過特殊的 failure-domain.beta.kubernetes.io/zone 標簽獲得,如果集群在公有云基礎架構上運行,則將自動創建此標簽,并將其值設置為節點的可用性區域的名稱。 標簽不是 Kubernetes 資源規范的一部分,但是,如果將節點輸出為 YAML 或 JSON,則可以看到它的相關信息: 當 kubectl 向 Kubernetes API 發出請求時,它將讀取 kubeconfig 文件,以獲取它需要訪問的所有連接參數并向 APIServer 發出請求。默認的 kubeconfig 文件是 ~/.kube/config,在使用多個集群時,在 kubeconfig 文件中配置了多個集群的連接參數,所以我們需要一種方法來告訴 kubectl 要將其連接到哪個集群中。在集群中,我們可以設置多個命名空間,Kubectl 還可確定 kubeconfig 文件中用于請求的命名空間,所以同樣我們需要一種方法來告訴 kubectl 要使用哪個命名空間。 此外我們還可以通過在 KUBECONFIG 環境變量來設置它們,還可以為每個 kubectl 命令使用 --kubeconfig 選項覆蓋默認的 kubeconfig 文件。 kubeconfig 文件由一組上下文組成,上下文包含以下三個元素: 通常大部分用戶在其 kubeconfig 文件中為每個集群使用單個上下文,但是,每個集群也可以有多個上下文,它們的用戶或命名空間不同,但并不太常見,因此集群和上下文之間通常存在一對一的映射。 在任何指定時間,這些上下文其中之一都可以被設置為當前上下文: 當 kubectl 讀取 kubeconfig 文件時,它總是使用當前上下文中的信息,所以在上面的示例中,kubectl 將連接到 Hare 集群。因此,要切換到另一個集群時,你只需在 kubeconfig 文件中更改當前上下文即可: 這樣 kubectl 現在將連接到 Fox 集群,并切換到同一集群中的另一個命名空間,可以更改當前上下文的命名空間元素的值: 在上面的示例中,kubectl 現在將在 Fox 集群中使用 Prod 命名空間,而不是之前設置的 Test 命名空間了。理論上講,我們可以通過手動編輯 kubeconfig 文件來進行這些更改,kubectl config 也命令提供了用于編輯 kubeconfig 文件的子命令: 比如現在我有兩個 kubeconfig 文件,分別連接兩個集群,現在我們可以使用下面的命令來合并兩個 kubeconfig 文件: 通過上面的命令可以將兩個 kubeconfig 合并到一起,我們可以看到現在有兩個集群和兩個上下文,在操作資源對象的時候可以通過使用參數 --context 來指定操作的集群: 我們可以看到操作的時候是非常繁瑣的,下面我們使用其他的工具來幫助我們自動進行這些更改。 Kubectx 可以有效幫助我們在集群和命名空間之間進行切換,該工具提供了 kubectx 和 kubens 命令,使我們可以分別更改當前上下文和命名空間。如果每個集群只有一個上下文,則更改當前上下文意味著更改集群。 如果我們已經安裝過 kubectl 插件管理工具 Krew,則直接使用下面的命令來安裝 Kubectx 插件即可: 安裝完成后,可以使用 kubectl ctx 和 kubectl ns 命令進行操作。但是需要注意這種方式不會安裝 shell 自動補全腳本,如果需要,可以使用另外的方式進行安裝,比如 macOS 下面使用 Homebrew 進行安裝: 此安裝命令將自動設置 bash/zsh/fish 自動補全腳本,由于經常需要切換不同的集群,很可能會誤操作集群,這個時候有個提示就很棒了,我們可以使用 kube-ps1 工具來修改 PS1。 不過由于我這里本地使用的是 oh-my-zsh,所以可以不用安裝,直接在 ~/.zshrc 開啟 plugin 加上 kube-ps1 就可以了,然后自定義一下,重新 source 下即可: 現在我們只需要輸入 kubectx 命令就可以切換集群了: 由于我們配置了 kube-ps1,所以在操作的終端前面也直接顯示了當前操作的集群,防止操作集群錯誤。 kubectx 的另一個十分有用的功能是交互模式,這需要與 fzf 工具一起工作(安裝 fzf 會自動啟用kubectx交互模式)。交互式模式允許你通過交互式模糊搜索界面選擇目標上下文或命名空間。 從1.12版開始,kubectl 就提供了插件機制,可讓你使用自定義命令擴展 kubectl,Kubectl 插件作為簡單的可執行文件分發,名稱形式為 kubectl-x,前綴 kubectl- 是必填項,其后是允許調用插件的新的 kubectl 子命令。 要安裝插件,你只需要將 kubectl-x 文件復制到 PATH 中的任何目錄并使其可執行,之后,你可以立即使用 kubectl x 調用插件。你可以使用以下命令列出系統上當前安裝的所有插件: Kubectl 插件可以像軟件包一樣共享和重用,但是在哪里可以找到其他人共享的插件?Krew 項目旨在為共享、查找、安裝和管理 kubectl 插件提供統一的解決方案。Krew 根據 kubectl 插件進行索引,你可以從中選擇和安裝。當然 krew 本身就是一個 kubectl 插件,這意味著,安裝 krew 本質上就像安裝其他任何 kubectl 插件一樣。你可以在GitHub頁面上找到krew的詳細安裝說明:https://github.com/kubernetes-sigs/krew。 下面是一些重要的 krew 命令: 需要注意 kubectl krew list 命令僅列出已與 krew 一起安裝的插件,而 kubectl plugin list 命令列出了所有插件,即與 krew 一起安裝的插件和以其他方式安裝的插件。 我們也可以很方便創建自己的 kubectl 插件,只需要創建一個執行所需操作的可執行文件,將其命名為 kubectl-x,然后按照如上所述的方式安裝即可。可執行文件可以是任何類型,可以是 Bash 腳本、已編譯的 Go 程序、Python 腳本,這些類型實際上并不重要。唯一的要求是它可以由操作系統直接執行。 讓我們現在創建一個示例插件。前面我們使用 kubectl 命令列出每個 Pod 的容器鏡像,我們可以輕松地將此命令轉換為可以使用 kubectl img 調用的插件。只需創建一個名為 kubectl-img 的文件,其內容如下: 現在,使用 chmod + x kubectl-img 使該文件可執行,并將其移動到 PATH 中的任何目錄,之后,你可以立即將插件與 kubectl img 一起使用了: kubectl 插件可以用任何編程或腳本語言編寫,如果使用 Shell 腳本,則具有可以輕松從插件調用 kubectl 的優勢。但是,你可以使用真實的編程語言編寫更復雜的插件,例如使用 Kubernetes 客戶端庫,如果使用 Go,還可以使用 cli-runtime 庫,該庫專門用于編寫 kubectl 插件。 JSONPath 表達式
選擇一個列表的所有元素
示例應用程序
顯示 Pod 的容器鏡像
顯示節點的可用區
多集群和命名空間切換
kubeconfig
Kubectx
kubectl 插件
創建插件
























