53幀變900幀!AI讓你不用昂貴的高速攝像機也能制作慢鏡頭
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
要制作慢動作視頻就必須要用死貴的高速攝像機?
NO! 可以用AI。



看到沒,這就是AI完成的效果!
雖然和真正的高速攝像機至少上千的幀數沒法比,但它完全可以做到每秒53幀的視頻輕輕松松變成960幀,沒有偽影也沒有噪聲。
很多網友看完效果都按耐不住了:“非常想要一個深入的教程”、“能不能出一個應用程序?”……


而這項酷斃的研究成果也成功入選CVPR 2021,研究人員來自華為蘇黎世研究中心和蘇黎世大學。

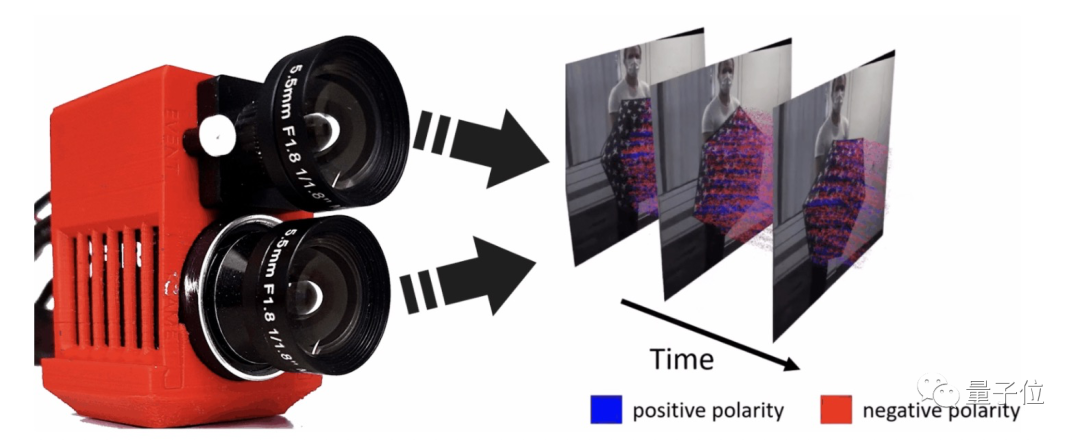
當然,也用了一個特殊的攝像頭
實現這一效果沒有采用通過視頻光流來猜測粒子運動的經典思想,而是先用了兩個攝像頭來捕捉畫面。
一個就是普通攝像頭,記錄低幀(20-60FPS)真實畫面;
要想達到慢動作效果,起碼得每秒300張畫面才夠;20幀的視頻給的信息太少了,沒法直接合成慢動作。
怎么辦?靠另一個特殊的攝像頭——
也就是事件相機(也稱為神經形態相機),它使用新型的傳感器,拍攝的是“事件”,也就是記錄像素亮度變化。
事件相機還比較新興,實驗室里有很多,市場上還沒有大規模問世,報價有2000美元一個或更高。

由于該相機記錄的信息經過壓縮表示,因此可以較低的清晰度、高速率進行拍攝,也就是犧牲圖像質量換取更多圖像信息。
最終的信息量足夠AI理解粒子的運動,方便后續插值。
這倆相機同步拍攝到的內容合起來就是這樣的:
拍好以后,就可以使用機器學習來最大化地利用這兩種相機的信息進行插幀了。
研究人員在這里提出的AI模型叫做Time Lens ,一共分為四塊。
首先,將倆相機拍到的幀信息和事件信息發送到前兩個模塊:基于變形(warp)的插值模塊和合成插值模塊。
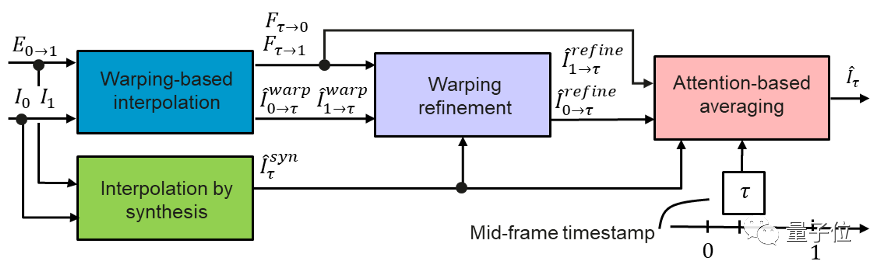
基于變形的插值模塊利用U形網絡將運動轉換為光流表示,然后將事件轉換成真實的幀。
合成插值模塊也是利用U形網絡將事件置于兩個幀之間,并直接為每個事件生成一個新的可能幀(現在就為同一事件生成兩個幀了)。
該模塊可以很好地處理幀之間出現的新對象以及光線變化(比如水反射啥的)。
不過到這里的話,合成的視頻可能會有一個問題:出現噪聲。
這時,第三個模塊的作用就派上用場了,它使用第二個插值合成模塊中的新信息來細化第一個模塊。
也就是提取同一事件的兩個生成幀中最有價值的信息,進行變形優化——再次使用U-net網絡生成事件的第三個幀版本。
最后,這三個候選幀被輸入到一個基于注意力的平均模塊。
該模塊采用三幀表示中最好的部分將它們組成最終幀。
現在,有了幀之間第一個事件的高清幀后,再對事件相機提供的所有事件重復此過程,就能生成最終我們想要的結果了。
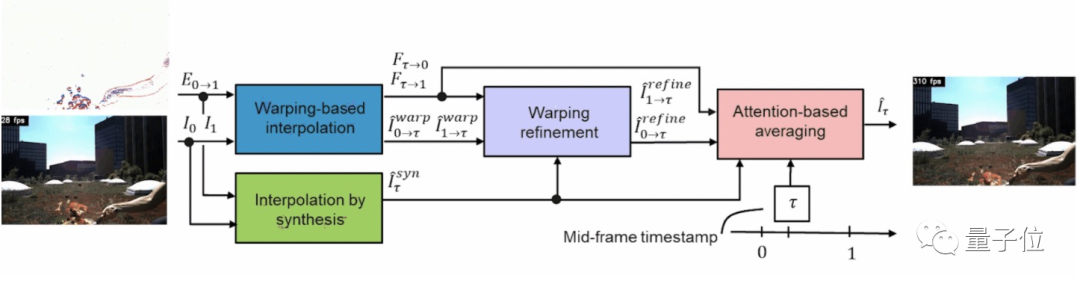
這就是使用AI創建逼真的慢動作視頻的方法。怎么樣?
附一個攝像機的參數圖:
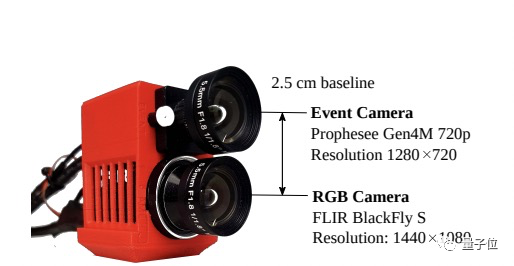
取得了智能手機和其他模型無法達到的效果
你說這個AI模型的效果好,那得對比一下才知道。

比如上面這個與最優秀的插值模型之一的DAIN(入選CVPR 19)的對比,誰好誰壞效果就很明顯了。
而且它的插值方法的計算復雜度也是最優的:圖像分辨率為640×480,在研究人員的GPU上進行單個插值時,DAIN模型需要878毫秒,該AI則只需要138毫秒。
另外,雖然不建議,用該模型輸入的視頻即使只有5幀,也可以生成慢動作。

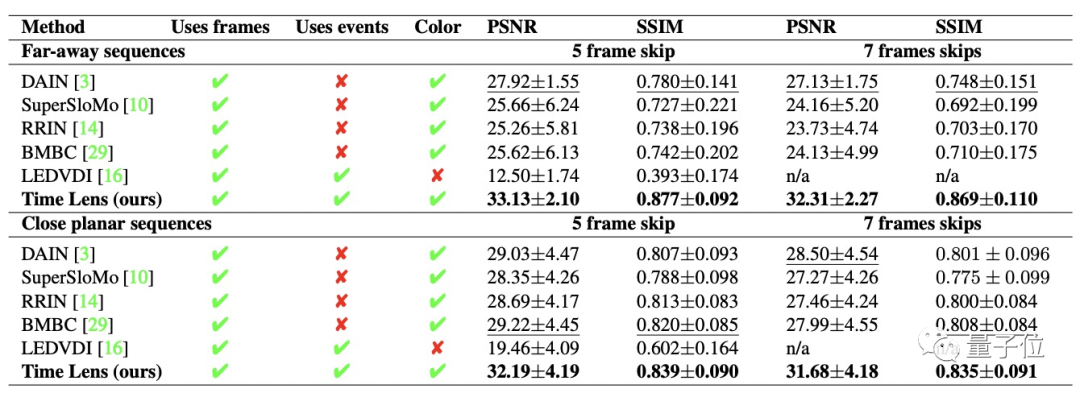
和其他模型的對比實驗數據,大家感興趣的可以查看論文。
最后,作者在介紹成果的視頻里也再次說道,不和昂貴的專業設備相比,該模型至少取得了智能手機和其他模型無法達到的效果。
作者介紹
一作Stepan Tulyakov,華為蘇黎世研究中心機器學習研究員。
共同一作Daniel Gehrig,蘇黎世大學博士生。蘇黎世聯邦理工大學機械工程碩士。
論文地址:
http://rpg.ifi.uzh.ch/docs/CVPR21_Gehrig.pdf
開源地址:
https://github.com/uzh-rpg/rpg_timelens