谷歌AI編舞師,能聽音樂來十種freestyle,想看爵士or芭蕾?
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
Transformer又又接新活了——
這次谷歌用它搞了一個會根據(jù)音樂跳舞的AI。
話不多說,先讓它給大家來幾段freestyle(原視頻見文末地址):
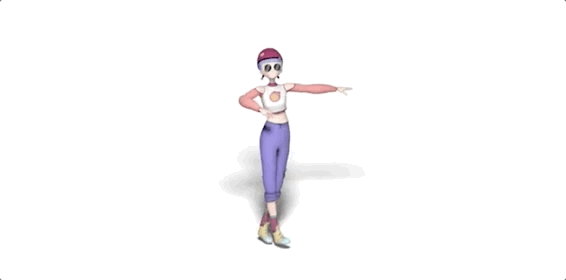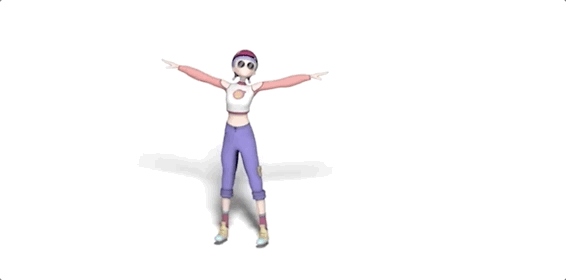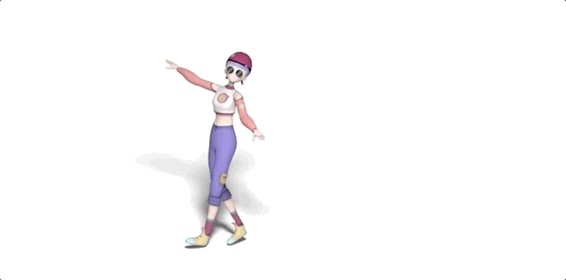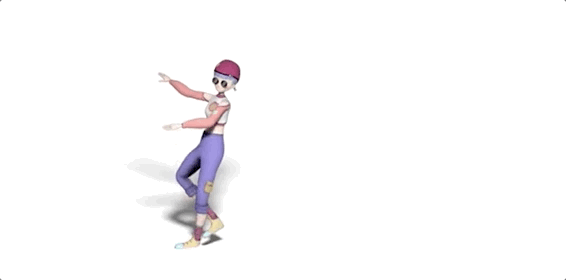



嗯,動作還挺美觀,各種風(fēng)格也駕馭住了。
看著我都想跟著來一段。
你pick哪個?
而這個AI也憑借著對音樂和舞蹈之間的關(guān)聯(lián)的深刻理解,打敗了3個同類模型取得SOTA,登上了ICCV 2021。

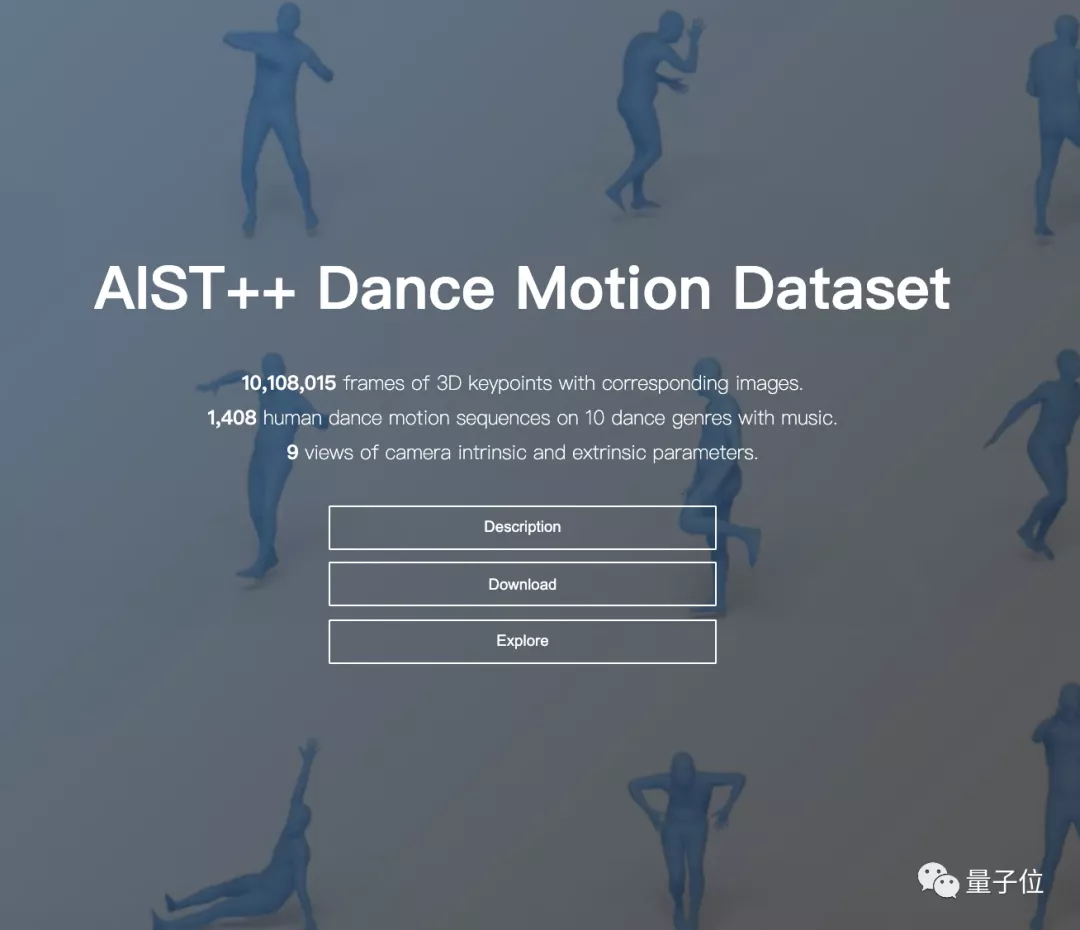
另外,除了代碼開源,研究團隊還隨之一起公開了一個含有10種類型的3D舞蹈動作數(shù)據(jù)集。
心動的,搞起來搞起來!
這個freestyle怎么來?
前面咱們不是說,這個AI用了Transformer嗎?
但這里的Transformer不是普通的Transformer,它是一個基于完全注意力機制(Full-Attention)的跨模態(tài)Transformer,簡稱FACT。
為什么要搞這么復(fù)雜?
因為研究人員發(fā)現(xiàn),光用單純的Transformer并不能讓AI理解音樂和舞蹈之間的相關(guān)性。
所以,這個FACT是怎么做的呢?
總的來說,F(xiàn)ACT模型采用了獨立的動作和音頻transformer。
首先輸入2秒鐘的seed動作序列和一段音頻,對其進行編碼。
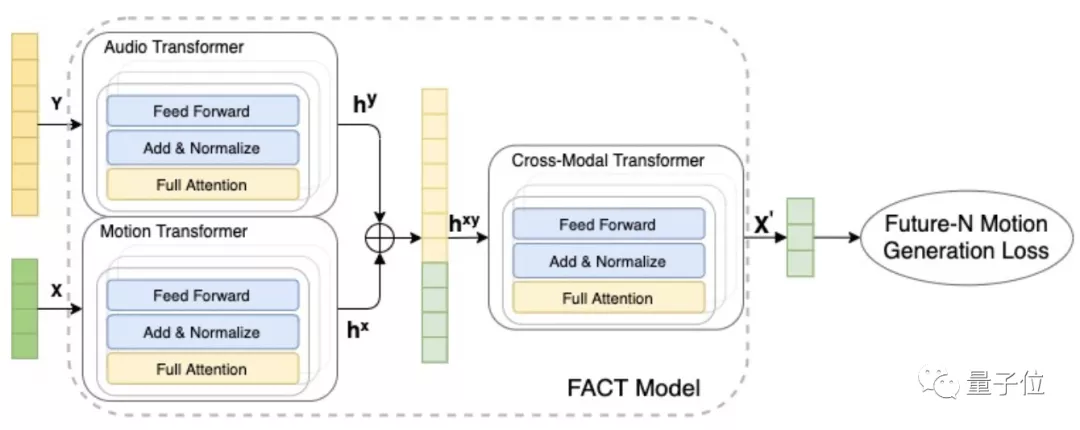
然后將embedding(從語義空間到向量空間的映射)連接起來,送入跨模態(tài)transformer學(xué)習(xí)兩種形態(tài)的對應(yīng)關(guān)系,并生成n個后續(xù)動作序列。
這些序列再被用來進行模型的自監(jiān)督訓(xùn)練。
其中3個transformer一起學(xué)習(xí),采用的是不用預(yù)處理和特征提取,直接把原始數(shù)據(jù)扔進去得到最終結(jié)果的端到端的學(xué)習(xí)方式。
另外就是在自回歸框架中進行模型測試,將預(yù)期運動作為下一代階段的輸入。
最終,該模型可以逐幀地生成一段(long-range)舞蹈動作。
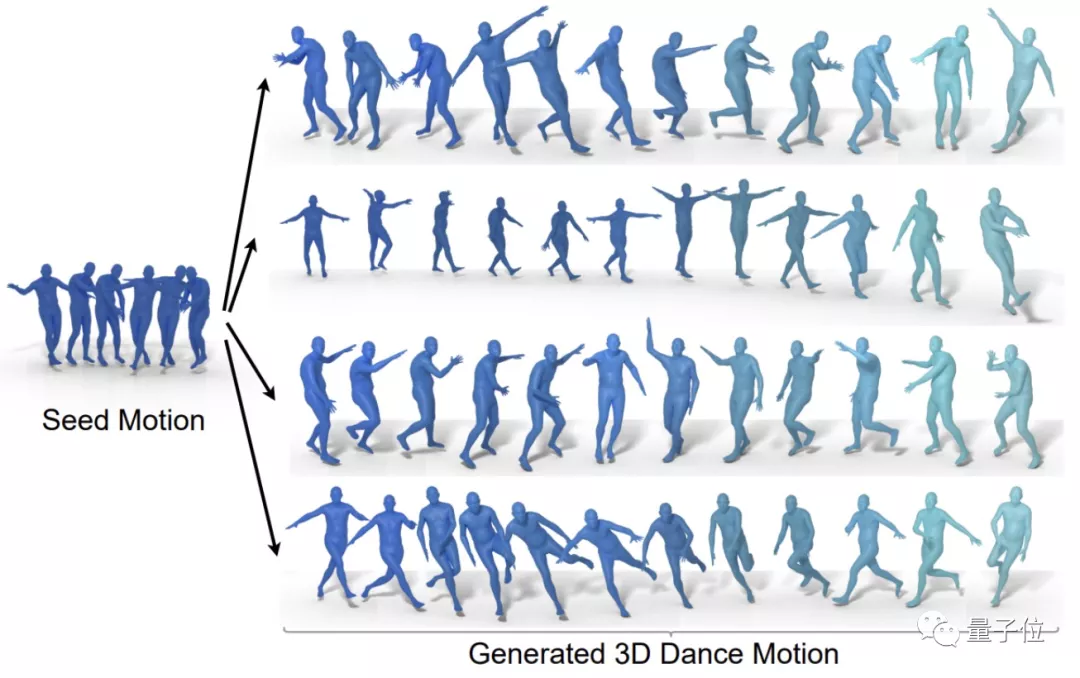
下圖則展示了該模型通過同一段種子動作(嘻哈風(fēng)格)、不同音樂生成了四種舞蹈作品(霹靂舞、爵士芭蕾、Krump和Middle Hip-hop)。
有沒有懂行的點評一下?
而為了讓AI生成的舞蹈生動且和音樂風(fēng)格保持一致,這個模型設(shè)計里面有3個關(guān)鍵點:
1、模型內(nèi)部token可以訪問所有輸入,因此三個transformer都使用一個完全注意力mask。這使得它比傳統(tǒng)的因果模型更具表現(xiàn)力。
2、不止預(yù)測下一個,該模型還預(yù)測N個后續(xù)動作。這有助于模型關(guān)注上下文,避免在幾個生成步驟后出現(xiàn)動作不銜接和跑偏的情況。
3、此外,在訓(xùn)練過程的前期還用了一個12層深的跨模態(tài)transformer模塊來融合兩個embedding(音頻和動作)。研究人員表示,這是訓(xùn)練模型傾聽分辨輸入音樂的關(guān)鍵。
下面就用數(shù)據(jù)來看看真實性能。
打敗3個SOTA模型
研究人員根據(jù)三個指標(biāo)來評估:
1、動作質(zhì)量:用FID來計算樣本(也就是他們自己發(fā)布的那個數(shù)據(jù)集,后面介紹)和生成結(jié)果在特征空間之間的距離。一共用了40個模型生成的舞蹈序列,每個序列1200幀(20秒)。
FID的幾何和動力學(xué)特性分別表示為FIDg和FIDk。
2、動作多樣性:通過測量40套生成動作在特征空間中的平均歐氏距離(Euclidean distance)得出。
分別用幾何特征空間Distg和動力學(xué)特征空間k來檢驗?zāi)P蜕筛鞣N舞蹈動作的能力。
3、動作與音樂的相關(guān)性:沒有好的已有指標(biāo),他們自己提出了一個“節(jié)拍對齊分?jǐn)?shù)”來評估輸入音樂(音樂節(jié)拍)和輸出3D動作(運動節(jié)拍)之間的關(guān)聯(lián)。
下面是FACT和三種SOTA模型(Li等人的、Dancenet、Dance Revolution)的對比結(jié)果:
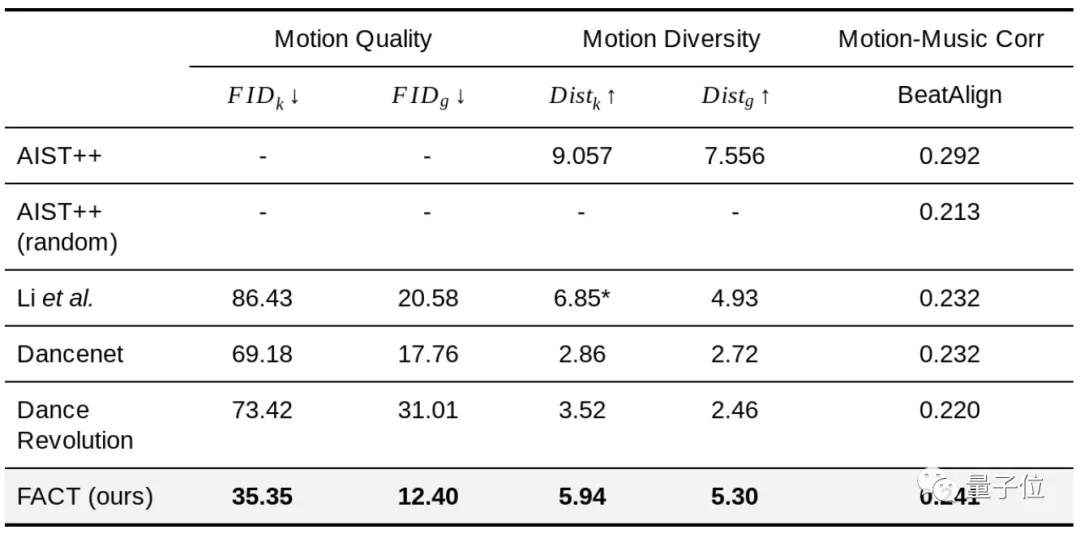
可以看到,F(xiàn)ACT在三項指標(biāo)上全部KO了以上三位。
*由于Li等人的模型生成的動作不連續(xù),所以它的平均動力學(xué)特征距離異常高,可以忽略。
看了數(shù)據(jù),咱們再看個更直觀的:
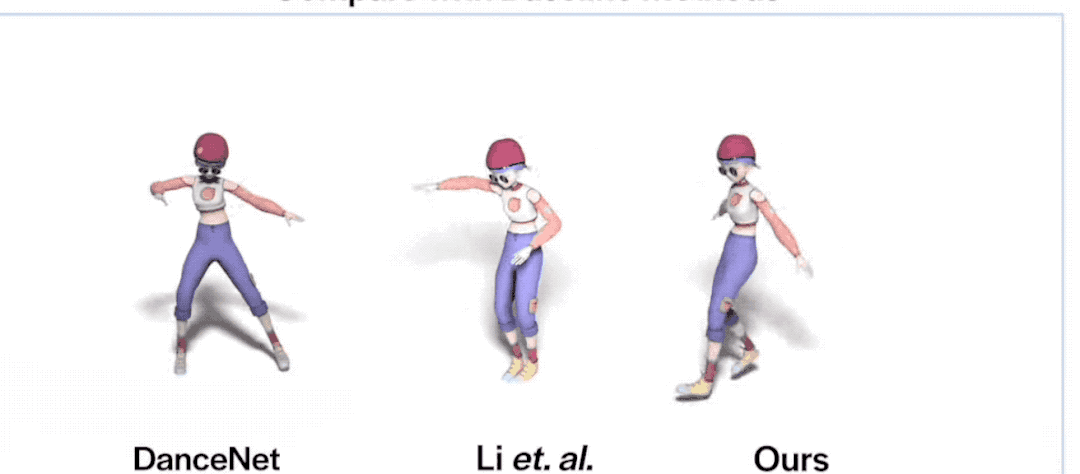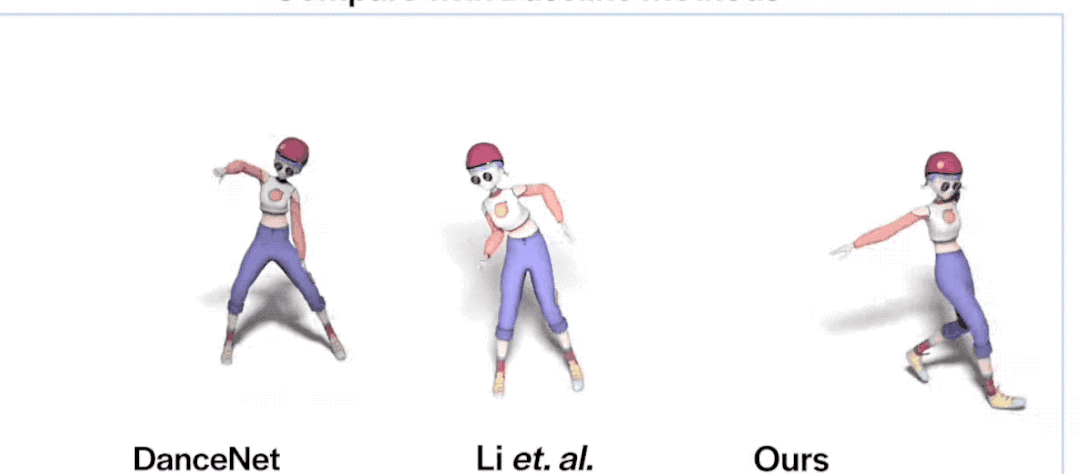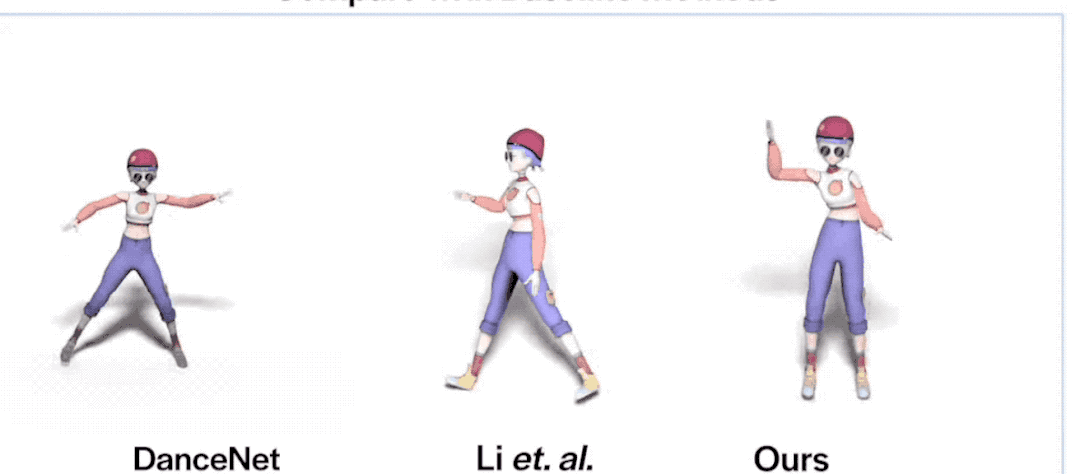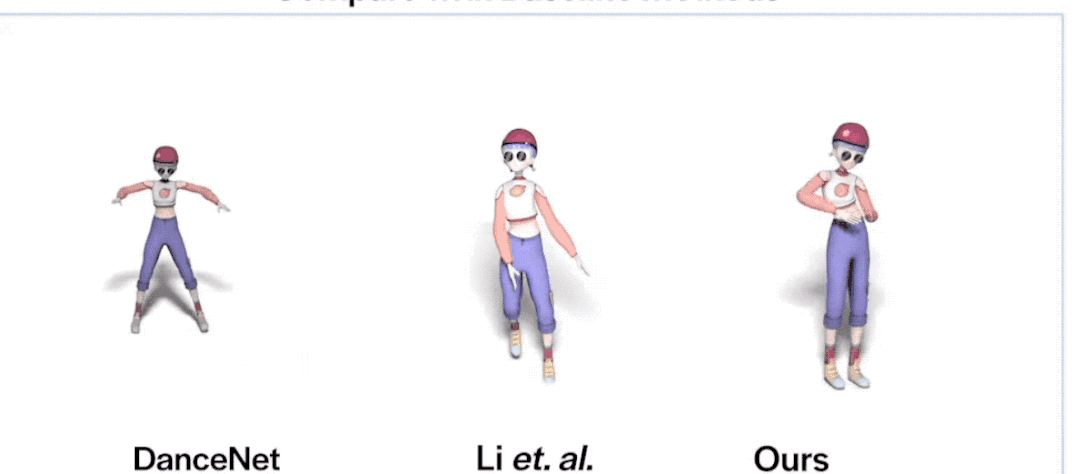
emmm,相比動作靈活的FACT,其他兩位看起來都有點“不太聰明”的亞子……
舞蹈動作數(shù)據(jù)集AIST++
最后,再來簡單介紹一下他們自己打造的這個3D舞蹈動作數(shù)據(jù)集AIST++。
看名字你也發(fā)現(xiàn)了,這是基于現(xiàn)有的舞蹈數(shù)據(jù)集AIST的“加強版”,主要是在原有基礎(chǔ)上加上了3D信息。
最終的AIST++一共包含5.2小時、1408個序列的3D舞蹈動作,跨越十種舞蹈類型,包括老派和新派的的霹靂舞、Pop、 Lock、Waack,以及Middle Hip-Hop、LA-style Hip-Hop、House、Krump、街頭爵士和爵士芭蕾,每種舞蹈類型又有85%的基本動作和15%的高級動作。
(怎么感覺全是街舞啊?)
每個動作都提供了9個相機視角,下面展示了其中三個。
它可以用來支持以下三種任務(wù):多視角的人體關(guān)鍵點估計;人體動作預(yù)測/生成;人體動作和音樂之間的跨模態(tài)分析。
團隊介紹
一作李瑞龍,UC伯克利一年級博士生,UC伯克利人工智能研究室成員,F(xiàn)acebook Reality Labs學(xué)生研究員。
研究方向是計算機視覺和計算機圖形學(xué)的交叉領(lǐng)域,主要為通過2D圖像信息生成和重建3D世界。
讀博之前還在南加州大學(xué)視覺與圖形實驗室做了兩年的研究助理。
本科畢業(yè)于清華大學(xué)物理學(xué)和數(shù)學(xué)專業(yè)、碩士畢業(yè)于計算機專業(yè),曾在Google Research和字節(jié)AI Lab實習(xí)。
共同一作Yang Shan,就職于Google Research。
研究方向包括:應(yīng)用機器學(xué)習(xí)、多模態(tài)感知、3D計算機視覺與物理仿真。
博士畢業(yè)于北卡羅來納大學(xué)教堂山分校(UNC,美國8所公立常春藤大學(xué)之一)。
David A. Ross,在Google Research領(lǐng)導(dǎo)Visual Dynamics研究小組。
加拿大多倫多大學(xué)機器學(xué)習(xí)和計算機視覺專業(yè)博士畢業(yè)。
Angjoo Kanazawa,馬里蘭大學(xué)博士畢業(yè),現(xiàn)在是UCB電氣工程與計算機科學(xué)系的助理教授,在BAIR領(lǐng)導(dǎo)旗下的KAIR實驗室,同時也是Google Research的研究員。
最最后,再來欣賞一遍AI編舞師的魅力吧:

論文:
https://arxiv.org/abs/2101.08779
GitHub:
https : //github.com/google-research/mint
數(shù)據(jù)集:
https://google.github.io/aistplusplus_dataset/
項目主頁:
https://google.github.io/aichoreographer/