













深度學習也有武林大會!八大科技巨頭:我的「流派」才能實現AGI
深度學習研究就像武林大會?
沒想到,這些看起來啥都搞的科技公司和AI實驗室其實,都有一個自己深耕的「流派」。

DeepMind
作為Alphabet的子公司,DeepMind可以說是強化學習的代名詞。
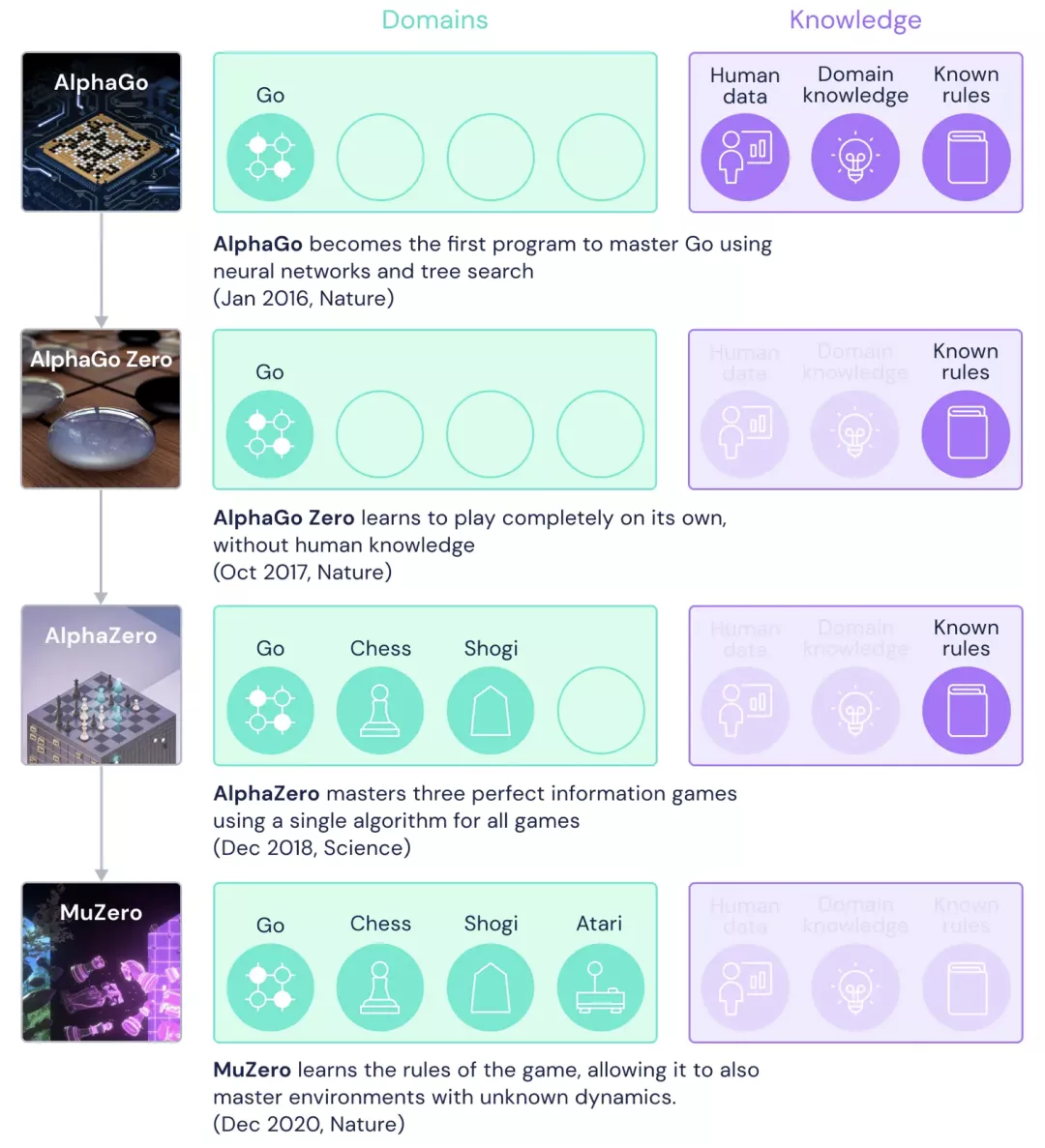
從AlphaGo到MuZero以及最近的AlphaFold 2,DeepMind一直在尋求強化學習方面的突破。
AlphaGo是一個打敗專業人類圍棋選手的計算機程序。它結合了先進的搜索樹和深度神經網絡。
MuZero除了在圍棋、國際象棋和象棋上達到了AlphaZero的水平之外,同時還掌握了一系列視覺上非常復雜的Atari游戲。
而MuZero在訓練的時候沒有任何外部的經驗,只知道游戲的規則。
https://deepmind.com/blog/article/muzero-mastering-go-chess-shogi-and-atari-without-rules
這些神經網絡將圍棋棋盤的描述作為輸入,并通過不同的層進行處理,這其中則包含了數百萬個神經元般的連接。
模型通過一個「策略網絡」選擇下一步棋,并通過另一個「價值網絡」預測游戲的贏家。

此外,DeepMind還推出了一個能夠預測蛋白質結構的系統:AlphaFold。
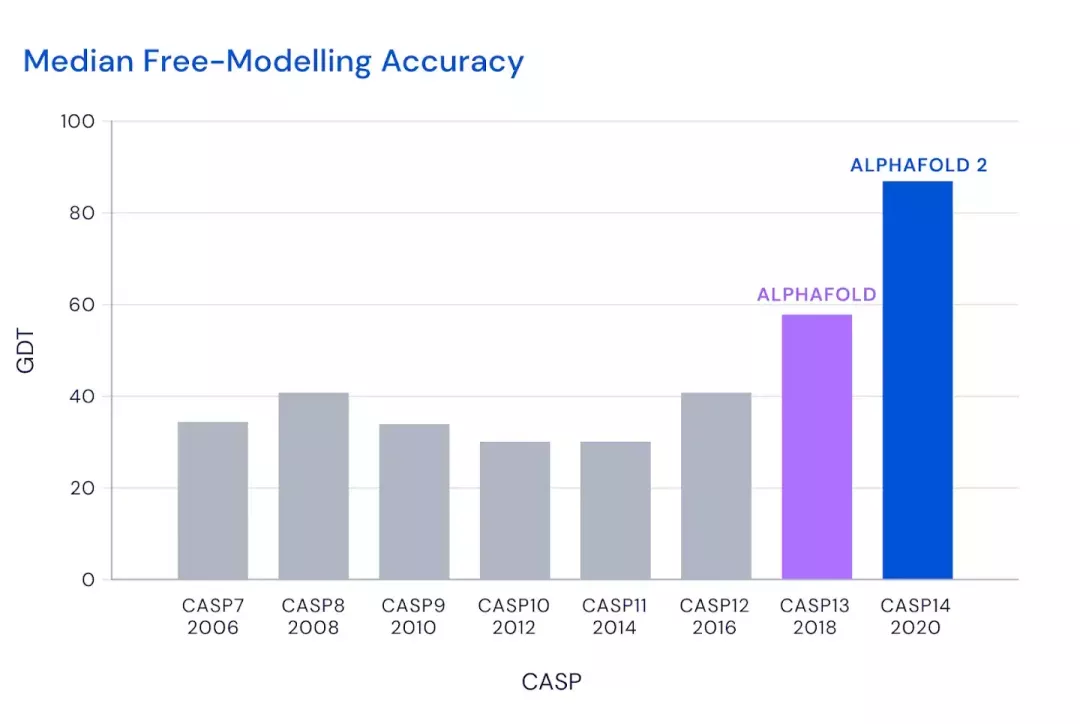
2018年,AlphaFold在國際蛋白質結構預測競賽(CASP)上首次亮相,在98只參賽隊伍中排名第一!
而第二代AlphaFold的突破在于,預測所有原子的3D結構,更快更準確地預測出蛋白質結構。
目前,DeepMind團隊將AlphaFold應用到20296種蛋白質,占人類蛋白質組的 98.5%。
AlphaFold幾乎是預測了人類蛋白質組里以單個蛋白為單位的空間三維結構,而且結果相當精確!這本身就是結構生物學上的一大突破。
OpenAI
GPT-3是全球談論最多的Transformer模型之一。
對于即將推出的語言模型GPT-4,雖然規模不會比GPT-3更大,但是會更加側重代碼的生成能力。
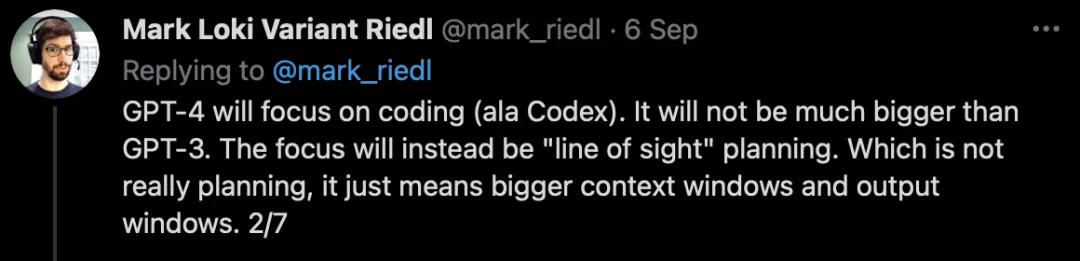
最近,OpenAI推出了OpenAI Codex,一個將自然語言翻譯成代碼的AI系統。
它是GPT-3的衍生版本,其訓練數據既包含自然語言,也包含數十億行公開來源的源代碼,包括公共GitHub存儲庫的代碼。
目前,GPT-3的競爭對手還包括EleutherAI GPT-j、BAAI的Wu Dao 2.0和谷歌的Switch Transformer等。
總而言之,OpenAI希望通過一系列Transformer模型實現AGI。
Facebook通過基礎的、開放的科學研究,讓跨領域的自監督學習技術改善其產品中的圖像、文本、音頻和視頻理解系統。
基于自監督學習的預訓練語言模型XLM-R,利用RoBERTa架構改善了Instagram和Facebook上的多語仇恨言論分類器。

Facebook認為,自監督學習是通往人類水平智能的正確道路。并通過公開分享其最新工作并在頂級會議上發表文章以及同時組織研討會等,來加速這一領域的研究。
最近的一些工作包括VICReg、無文本NLP、DINO等。
谷歌是自動機器學習(AutoML)的先驅者之一。
它正在高度多樣化的領域中推進AutoML,如時間序列分析和計算機視覺。
今年,谷歌大腦的研究人員推出了一種新的基于符號編程的AutoML方法:PyGlove。其應用于Python的通用符號編程庫,從而實現AutoML的符號表述。
谷歌在該領域的一些最新產品包括Vertex AI、AutoML視頻智能、AutoML自然語言、AutoML翻譯和AutoML表格。

Apple
為何iPhone上的Siri在聽到我們自己說「Hey Siri」時會有反應,但是對其他人說的都沒有反應?
按理來說,訓練一個這種模型,會收集我們的聲音數據,并且這些數據都會保存在iPhone上。
但其實不然,蘋果采用了一種分布式機器學習形式:聯邦學習(Federated Learning。
聯邦學習可以有效解決數據孤島問題,在不公布用戶數據的前提下,可以將用戶的多個數據集中起來匯集成一個統一的模型。
這樣既確保邊緣的機器學習模型的順利訓練,同時維護用戶數據的隱私和安全。
聯邦學習是由谷歌研究人員在2016年的論文「Communication Efficient Learning of Deep Networks for Decentralized Data」中首次提出的,現已被業界的各種參與者廣泛采用。

https://arxiv.org/pdf/1602.05629.pdf
2019年,蘋果與斯坦福大學合作,發表了一篇名為「保護重構及其在私有聯合學習中的應用」的研究論文,展示了以前不可能實現的大規模本地私有模型訓練的實用方法。

https://arxiv.org/pdf/1812.00984.pdf
該研究還涉及到理論和經驗上的方法,以適應大規模的圖像分類和語言模型,效用幾乎沒有下降。
目前,蘋果也在研究各種創新方法,通過利用聯邦學習和分布式替代技術,開發注重用戶隱私的產品和應用程序。
Microsoft
微軟研究院是全球頂尖人工智能實驗室之一,在計算機視覺和語音分析方面開創了機器教學研究和技術的先河。
隨著AI應用的場景越來越豐富,加上數據量小、任務復雜等種種實踐中可能出現的挑戰,有時機器學習的結果并不理想,而且效率低下。
為此,機器教學(Machine Teaching)便誕生了,人類可以利用自己的專業知識和經驗幫助AI進行更有針對性的學習,幫助強化學習算法更快地找到解決方案。
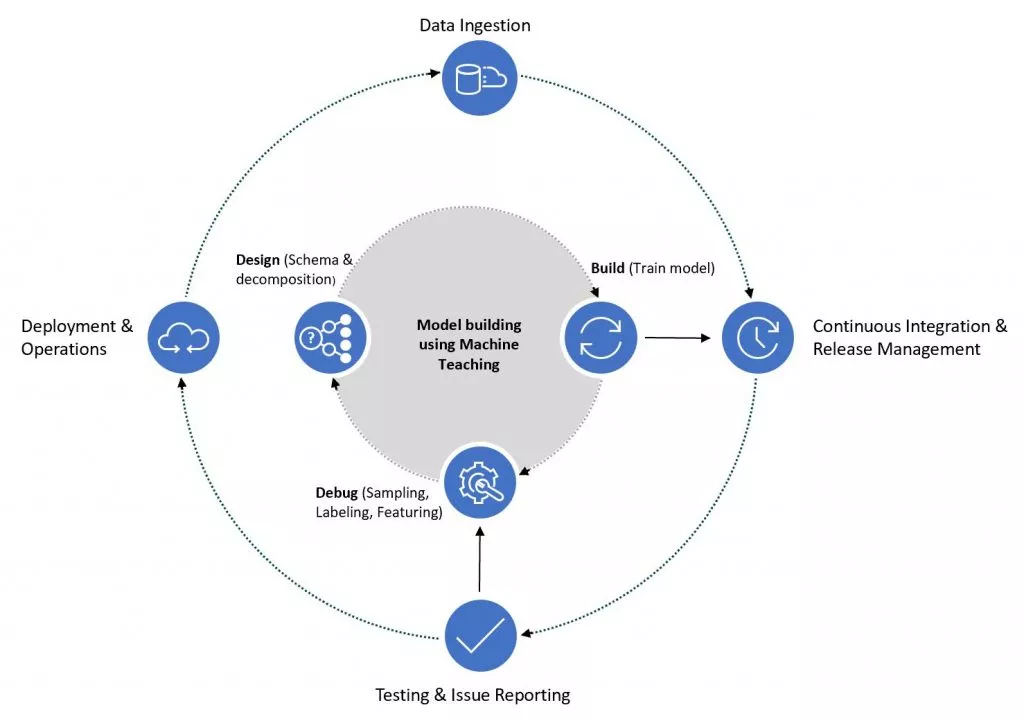
https://www.msra.cn/zh-cn/news/features/machine-teaching
此外,在智能方面,微軟涵蓋了人工智能、計算機視覺、搜索和信息檢索等研究領域。系統方面,則提供量子計算、數據平臺和分析、安全、隱私和密碼學等方面的資源。
Amazon
由于遷移學習方法在Alexa上的表現十分出色,亞馬遜目前已經成為領先研究中心之一。
無論是在不同的語言模型、技術,還是更好的機器翻譯中,亞馬遜都推動了遷移學習領域的研究。
今年1月,亞馬遜的研究人員提出了ProtoDA,一種高效的用于幾率意圖分類的遷移學習方法。
IBM
盡管IBM在機器學習方面開創了先河,但卻失去了其在科技公司中的領先地位。
在1950年,IBM的Arthur Samuel開發了一個用于下棋的計算機程序(深藍),一個專門分析國際象棋的超級電腦。
1996年2月10日,深藍首次挑戰國際象棋世界冠軍卡斯巴羅夫,但以2-4落敗。其后研究小組把深藍加以改良——它有一個昵稱叫「更深的藍」(depper blue)。并在1997年再度挑戰卡斯巴羅夫,最終以3.5—2.5擊敗對手.
到了2020年,IBM則開始推動它在量子機器學習方面的研究。
目前,IBM正在開拓專業硬件并建立電路庫,使研究人員、開發人員和企業能夠在沒有量子計算知識的前提下,通過量子云服務來編碼語言,
2023年,IBM期望能提供整套跨域預構建運行,可從基于云的API調用,并用通用的開發框架。
IBM堅信已經同量子內核和算法開發者打下了基礎,并將幫助企業開發者獨立探索量子計算模型,而無需考慮量子物理。
換句話說,開發人員能自由地在任何云原生混合運行中建構系統、語言和編程框架,或將量子組件集成到任何業務中。



















