













MQ那點破事!消息丟失、重復消費、消費順序、堆積、事務、高可用....
本文轉載自微信公眾號「微觀技術」,作者 微觀技術。轉載本文請聯(lián)系微觀技術公眾號。
大家好,我是 Tom哥~
馬上要開啟國慶小長假了,祝大家節(jié)日快樂,吃喝玩樂走起~
為了便于大家查找問題,了解全貌,整理個目錄,我們可以快速全局了解關于消息隊列,面試官一般會問哪些問題。
本篇文章的目錄:
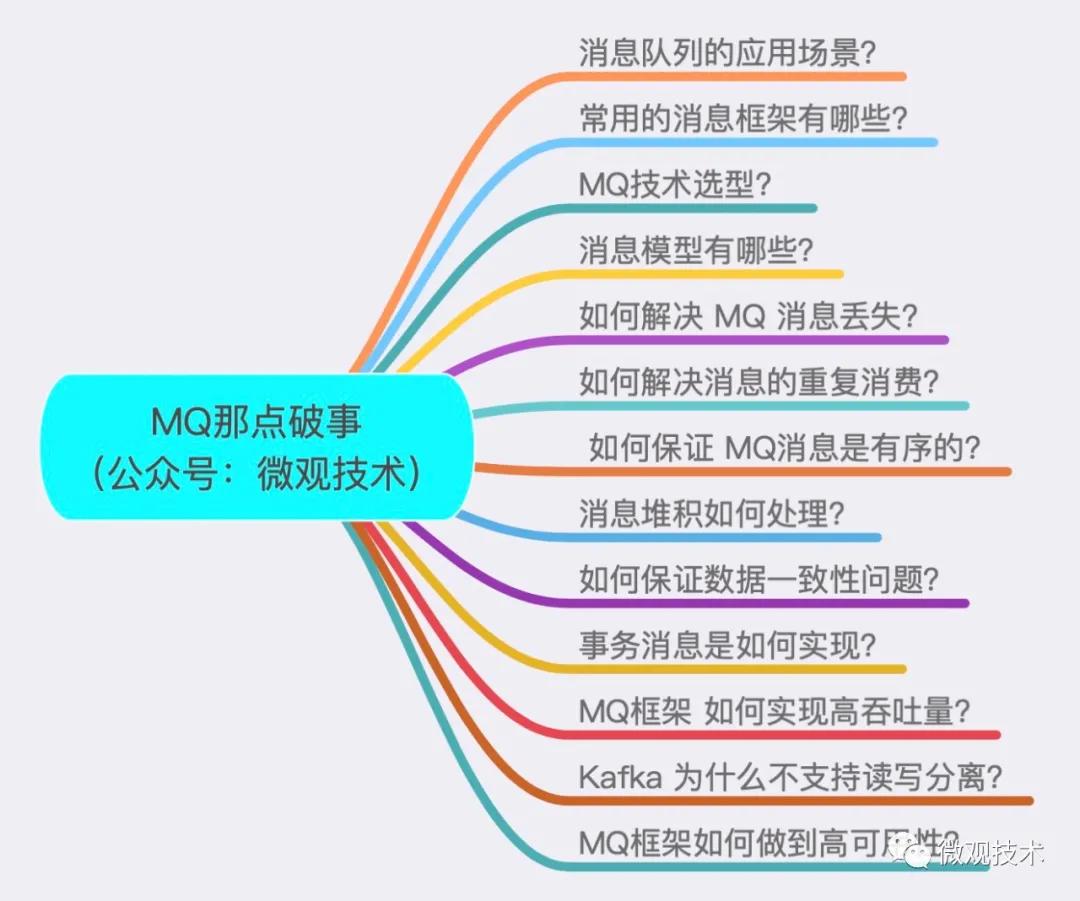
消息隊列的應用場景?
答案:1、異步處理 2、流量削峰填谷 3、應用解耦 4、消息通訊
- 異步處理。將一個請求鏈路中的非核心流程,拆分出來,異步處理,減少主流程鏈路的處理邏輯,縮短RT,提升吞吐量。如:注冊新用戶發(fā)短信通知。
- 削峰填谷。避免流量暴漲,打垮下游系統(tǒng),前面會加個消息隊列,平滑流量沖擊。比如:秒殺活動。生活中像電源適配器也是這個原理。
- 應用解耦。兩個應用,通過消息系統(tǒng)間接建立關系,避免一個系統(tǒng)宕機后對另一個系統(tǒng)的影響,提升系統(tǒng)的可用性。如:下單異步扣減庫存
- 消息通訊。內置了高效的通信機制,可用于消息通訊。如:點對點消息隊列、聊天室。
常用的消息框架有哪些?
答案:ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaQ,RocketMQ、Pulsar 等
MQ技術選型?
答案:對比了 Kafka、RocketMQ 、Pulsar 三個框架,時耗、吞吐量、可靠性、事務、副本同步策略、多租戶、動態(tài)擴容、故障恢復等評估指標。
消息模型有哪些?
答案:1、點對點模式 2、發(fā)布/訂閱模式
如何保證 MQ 消息不丟失?
答案:在了解消息中間件的運作模式后,主要從三個方面來考慮這個問題:
1、生產端,不丟失消息
2、MQ服務端,存儲本身不丟失消息
3、消費端,不丟失消息
如何解決消息的重復消費?
答案:生產端為了保證消息發(fā)送成功,可能會重復推送(直到收到成功ACK),會產生重復消息。但是一個成熟的MQ Server框架一般會想辦法解決,避免存儲重復消息(比如:空間換時間,存儲已處理過的message_id),給生產端提供一個冪等性的發(fā)送消息接口。
但是消費端卻無法根本解決這個問題,在高并發(fā)標準要求下,拉取消息+業(yè)務處理+提交消費位移需要做事務處理,另外消費端服務可能宕機,很可能會拉取到重復消息。
所以,只能業(yè)務端自己做控制,對于已經消費成功的消息,本地數(shù)據(jù)庫表或Redis緩存業(yè)務標識,每次處理前先進行校驗,保證冪等。
如何保證 MQ消息是有序的?
答案:有些業(yè)務有上下文要求,比如:電商行業(yè)的下單、付款、發(fā)貨、確認收貨,每個環(huán)節(jié)都會發(fā)送消息。而消費端拉取并消費消息時,也是希望按正常的狀態(tài)機流程進行。所以對消息就有了順序要求。解決思路:
1、該topic強制采用一個分區(qū),所有消息放到一個隊列里,這樣能達到全局順序性。但是會損失高并發(fā)特性。
2、局部有序,采用路由機制,將同一個訂單的不同狀態(tài)消息存儲在一個分區(qū)partition,單線程消費。比如Kafka就提供了一個接口擴展org.apache.kafka.clients.Partitioner,方便開發(fā)人員按照自己的業(yè)務場景來定制路由規(guī)則。
消息堆積如何處理?
答案:主要是消息的消費速度跟不上生產速度,從而導致消息堆積。解決思路:
1、可能是剛上線的業(yè)務,或者大促活動,流量評估不到位,這時需要增加消費組的機器數(shù)量,提升整體消費能力
2、也可能是消費端的問題,正常情況,一條消息處理需要10ms,但是優(yōu)化不到位或者線上bug,現(xiàn)在要500ms,那么消費端的整體處理速度會下降50倍。這時,我們就要針對性的排查業(yè)務代碼。Tom哥之前帶的團隊就有小伙伴出現(xiàn)這個問題,當時是數(shù)據(jù)庫的一條sql沒有命中索引,導致單條消息處理耗時拉長,進而導致消息堆積,線上報警,不過憑我們豐富的經驗,很快就定位解決了。
如何保證數(shù)據(jù)一致性問題?
答案:為了解耦,引入異步消息機制。先進行本地數(shù)據(jù)庫操作,處理成功后,再發(fā)送MQ消息,由消費端進行后續(xù)操作。比如:電商訂單下單成功后,要通知扣減庫存。
這兩者一定要保證事務操作,否則就會出現(xiàn)數(shù)據(jù)不一致問題。這時候,我們就需要引入事務消息來解決這個問題。
另外,在消費環(huán)節(jié),也可能出現(xiàn)數(shù)據(jù)不一致情況。我們可以采用最終一致性原則,增加重試機制。
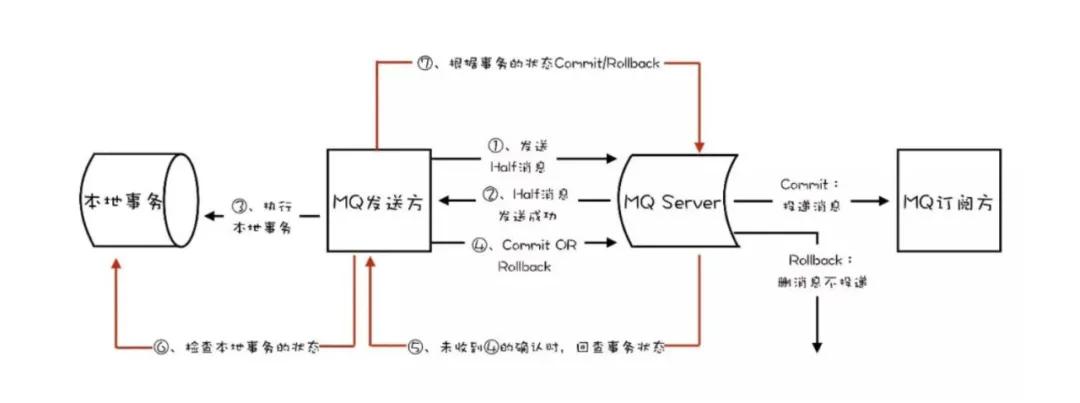
事務消息是如何實現(xiàn)?
答案:
- 1、生產者先發(fā)送一條半事務消息到MQ
- 2、MQ收到消息后返回ack確認
- 3、生產者開始執(zhí)行本地事務
- 4、if 本地事務執(zhí)行成功,發(fā)送commit到MQ;失敗,發(fā)送rollback
- 5、如果MQ?時間未收到生產者的二次確認commit或rollback,MQ對生產者發(fā)起反向回查
- 6、生產者查詢事務執(zhí)行最終狀態(tài)
- 7、根據(jù)查詢事務狀態(tài),再次提交二次確認
MQ框架 如何實現(xiàn)高吞吐量?
答案:
1、消息的批量處理
2、消息壓縮,節(jié)省傳輸帶寬和存儲空間
3、零拷貝
4、磁盤的順序寫入
5、page cache 頁緩存,由操作系統(tǒng)異步將緩存中的數(shù)據(jù)刷到磁盤,以及高效的內存讀取
6、分區(qū)設計,一個邏輯topic下面掛載N個分區(qū),每個分區(qū)可以對應不同的機器消費消息,并發(fā)設計。
Kafka 為什么不支持讀寫分離?
答案:我們知道,生產端寫入消息、消費端拉取消息都是與leader 副本交互的,并沒有像mysql數(shù)據(jù)庫那樣,master負責寫,slave負責讀。
這種設計主要是從兩個方面考慮:
1、數(shù)據(jù)一致性。一主多從,leader副本的數(shù)據(jù)同步到follower副本有一定的延時,因此每個follower副本的消息位移也不一樣,而消費端是通過消費位移來控制消息拉取進度,多個副本間要維護同一個消費位移的一致性。如果引入分布式鎖,保證并發(fā)安全,非常耗費性能。
2、實時性。leader副本的數(shù)據(jù)同步到follower副本有一定的延時,如果網(wǎng)絡較差,延遲會很嚴重,無法滿足實時性業(yè)務需求。
綜上考慮,讀寫操作都是針對 leader 副本進行的,而 follower 副本主要是用于數(shù)據(jù)的備份。
MQ框架如何做到高可用性?
答案:以Kafka框架為例,其他的MQ框架原理類似。
Kafka 由多個 broker 組成,每個 broker 是一個節(jié)點。你創(chuàng)建一個 topic,這個 topic 可以劃分為多個 partition,每個 partition 存放在不同的 broker 上,每個 partition 存放一部分數(shù)據(jù),每個 partition 有多個 replica 副本。
寫的時候,leader 會負責把數(shù)據(jù)同步到所有 follower 上去,讀的時候就直接讀 leader 上的數(shù)據(jù)即可。
如果某個 broker 宕機了,沒事兒,那個 broker 上面的 partition 在其他機器上都有副本,此時會從 follower 中重新選舉一個新的 leader 出來,大家繼續(xù)讀寫那個新的 leader 即可。這就是所謂的高可用性。
關于Kafka,面試官一般喜歡考察哪些問題?
答案:
- 消息壓縮
- 消息解壓縮
- 分區(qū)策略
- 生產者如何實現(xiàn)冪等、事務
- Kafka Broker 是如何存儲數(shù)據(jù)?備份機制
- 為什么要引入消費組?



















