MYSQL 那點破事!索引、SQL調優、事務、B+樹、分表 ....
大家好,我是Tom哥~
為了便于大家查找問題,了解全貌,整理個目錄,我們可以快速全局了解關于mysql數據庫,面試官一般喜歡問哪些問題
接下來,我們逐條來看看每個問題及答案
MyISAM 和 InnoDB 的區別?
答案:InnoDB 支持 事務、外鍵、聚集索引,通過MVCC來支持高并發,索引和數據存儲在一起。InnoDB 不保存表的具體行數,執行 select count(*) from table 時需要全表掃描。而MyISAM 用一個變量保存了整個表的行數。
InnoDB 最小的鎖粒度是行鎖,MyISAM 最小的鎖粒度是表鎖,并發能力低。MySQL 將默認存儲引擎是 InnoDB
mysql 鎖有哪些類型?
答案:mysql鎖分為共享鎖( S lock ) 、排他鎖 ( X lock ),也叫做讀鎖和寫鎖。根據粒度,可以分為表鎖、頁鎖、行鎖。
什么是間隙鎖?
答案:間隙鎖是可重復讀級別下才會有的鎖,mysql會幫我們生成了若干左開右閉的區間,結合MVCC和間隙鎖可以解決幻讀問題。
如何避免死鎖?
答案:死鎖的四個必要條件:1、互斥 2、請求與保持 3、環路等待 4、不可剝奪。
- 合理的設計索引,區分度高的列放到組合索引前面,使業務 SQL 盡可能通過索引定位更少的行,減少鎖競爭。
- 調整業務邏輯 SQL 執行順序, 避免 update/delete 長時間持有鎖的 SQL 在事務前面。
- 避免大事務,將大事務拆成多個小事務
- 以固定的順序訪問表和行。比如兩個更新數據的事務,事務 A 更新數據的順序為 1,2;事務 B 更新數據的順序為 2,1。這樣更可能會造成死鎖。
- 在并發比較高的系統中,不要顯式加鎖,特別是是在事務里顯式加鎖。如 select … for update 語句,如果是在事務里(運行了 start transaction 或設置了autocommit 等于0),那么就會鎖定所查找到的記錄。
- 盡量用主鍵/索引去查找記錄
- 優化 SQL 和表設計,減少同時占用太多資源的情況。比如說,避免多個表join,將復雜 SQL 分解為多個簡單的 SQL。
數據庫的隔離級別?
答案:讀未提交、讀已提交、可重復讀(mysql的默認級別,每次讀取結果都一樣,但是有可能產生幻讀)、串行化。
Mysql有哪些類型的索引?
答案:
- 普通索引:一個索引只包含一個列,一個表可以有多個單列索引。
- 唯一索引:索引列的值必須唯一,但允許有空值
- 復合索引:多列值組成一個索引,專門用于組合搜索,其效率大于索引合并
- 聚簇索引:也稱為主鍵索引,是一種數據存儲方式。B+Tree結構,非葉子節點包含健值和指針,葉子節點包含索引列和行數據。一張表只能有一個聚簇索引。
- 非聚簇索引:不是聚簇索引,就是非聚簇索引。葉子節點只是存索引列和主鍵id。如果sql還要返回除了索引列的其他字段信息,需要回表,第一次索引一般是順序IO,回表的操作屬于隨機IO。回表的次數越多,性能越差。此時我們推薦覆蓋索引
什么是覆蓋索引和回表?
答案:
1、覆蓋索引,指的是在一次查詢中,一個索引包含所有需要查詢的字段的值,可能是返回值或where條件
- select buyer_id from order where money>100
假如我們創建了一個(money,buyer_id)的聯合索引,索引的葉子節點包含了buyer_id的信息,則不會再回表查詢。
2、回表,指查詢時一些字段值拿不到,需要到主鍵索引B+樹再查一次。
Mysql的最左前綴原則?
答案:即最左優先,在檢索數據時從聯合索引的最左邊開始匹配,直到遇到范圍查詢(如:> 、< 、between、like等)
例子:where a = 1 and b = 2 and c > 3 and d = 4 ,如果建立(a,b,c,d)組合索引,d是用不到索引的;如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整。
線上SQL的調優經驗?
答案:
- 1、slow_query_log 日志中收集到的慢 SQL ,結合 explain 分析是否命中索引。
- 2、減少索引掃描行數,有針對性的優化慢 SQL。
- 3、建立聯合索引,由于聯合索引的每個葉子節點包含檢索字段的信息,按最左前綴原則匹配后,再按其它條件過濾,減少回表的數據量。
- 4、還可以使用虛擬列和聯合索引來提升復雜查詢的執行效率。
官方為什么建議采用自增id 作為主鍵?
答案:自增id是連續的,插入過程也是順序的,總是插入在最后,減少了頁分裂,有效減少數據的移動。所以盡量不要使用字符串(如:UUID)作為主鍵。
索引為什么采用B+樹,而不用B-樹,紅黑樹?
答案:提升查詢速度,首先要減少磁盤IO次數,也就是要降低樹的高度。
- 平衡二叉樹、紅黑樹,都屬于二叉樹。時間復雜度為O(n),當表的數據量上千萬時,樹的深度很深,mysql讀取時消耗大量 IO。另外,InnoDB引擎采用頁為單位讀取,每個節點一頁,但是二叉樹每個節點儲存一個關鍵詞,導致空間浪費。
- B-樹,非葉子節點存儲數據,占用較多空間,導致每個節點的指針少很多,無形增加了樹的深度。
- B+樹數據都存儲在葉子節點,非葉子節點只存儲健值+指針,索引樹更加扁平,三層深度可以支持千萬級表存儲。同時葉子節點之間通過鏈表關聯,范圍查找更快。
事務的特性有哪些?
答案:ACID。
原子性。一個事務中的操作要么全部成功,要么全部失敗。
持久性。永久保存在數據庫中。
一致性。總是從一個一致性的狀態轉換到另一個一致性的狀態
隔離性。一個事務的修改在提交前,其他事務是感知不到的
如何實現分布式事務?
答案:
1、流水任務,最終一致性,前提是接口要支持冪等性
2、事務消息
3、二階段提交
4、三階段提交
5、TCC
6、Seata 框架
日常工作中,MySQL 如何做優化?
答案:
- 1、分頁優化。比如電梯直達,limit 100000,10 先查找起始的主鍵id,再通過id>#{value}往后取10條
- 2、盡量使用覆蓋索引,索引的葉節點中已經包含要查詢的字段,減少回表查詢
- 3、SQL優化(索引優化、小表驅動大表、虛擬列、適當增加冗余字段減少連表查詢、聯合索引、排序優化、慢日志 Explain 分析執行計劃)。
- 4、設計優化(避免使用NULL、用簡單數據類型如int、減少 text 類型、分庫分表)。
- 5、硬件優化(使用SSD 減少 I/O 時間、足夠大的網絡帶寬、盡量大的內存)
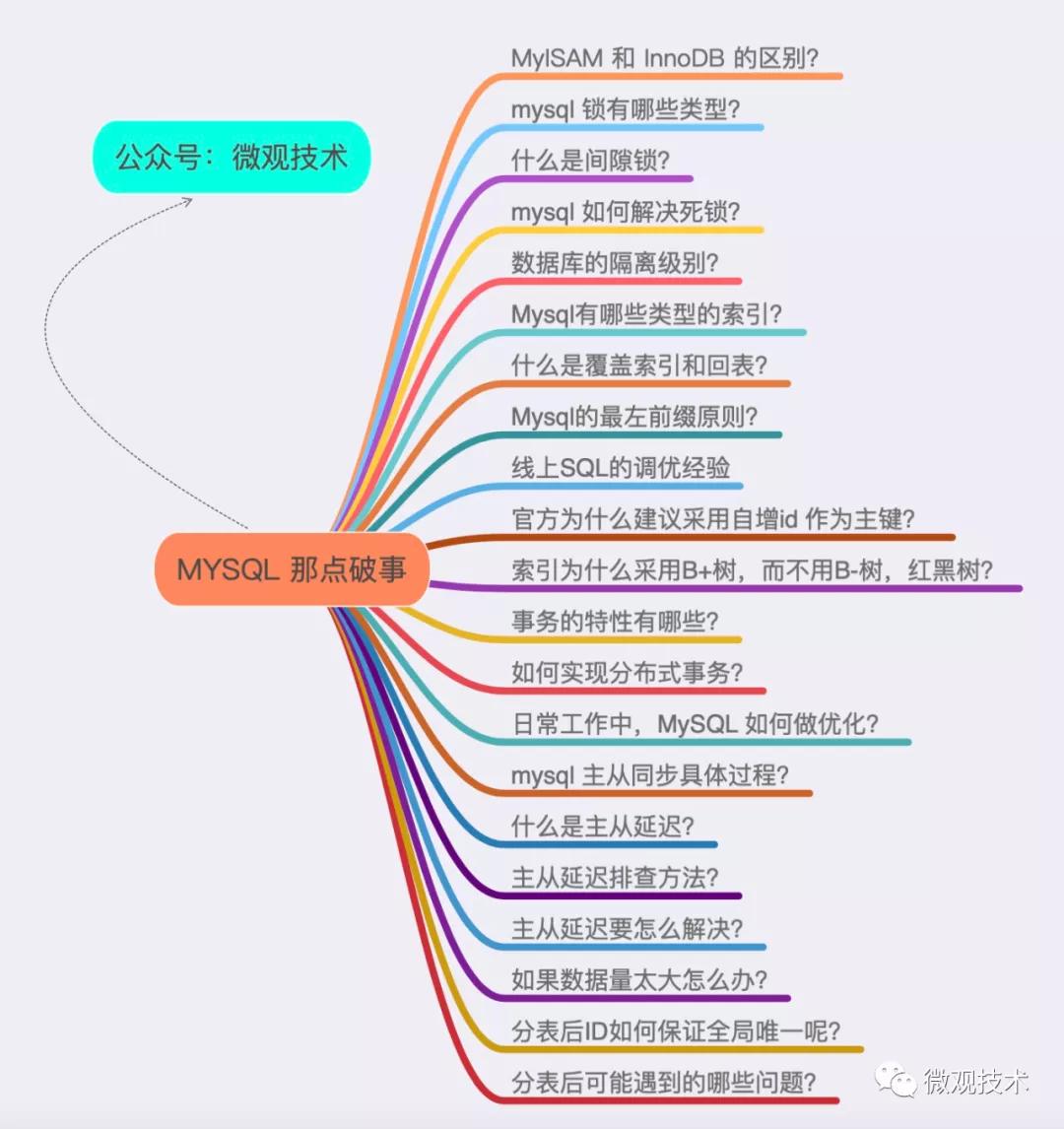
mysql 主從同步具體過程?
答案:
- master主庫,有數據更新,將此次更新的事件類型寫入到主庫的binlog文件中
- 主庫會創建log dump 線程通知slave有數據更新
- slave,向master節點的 log dump線程請求一份指定binlog文件位置的副本,并將請求回來的binlog存到本地的Relay log 中繼日志中
- slave 再開啟一個SQL 線程讀取Relay log事件,并在本地執行redo操作。將發生在主庫的事件在本地重新執行一遍,從而保證主從數據同步
什么是主從延遲?
答案:指一個寫入SQL操作在主庫執行完后,將數據完整同步到從庫會有一個時間差,稱之為主從延遲。計算公式:
- 主庫生成一條寫入SQL的binlog,里面會有一個時間字段,記錄寫入的時間戳 t1
- binlog 同步到從庫后,一旦開始執行,取當前時間 t2
- t2-t1,就是延遲時間
注意:不同服務器要保持時鐘一致
主從延遲排查方法?
答案:通過 show slave status 命令輸出的Seconds_Behind_Master參數的值來判斷
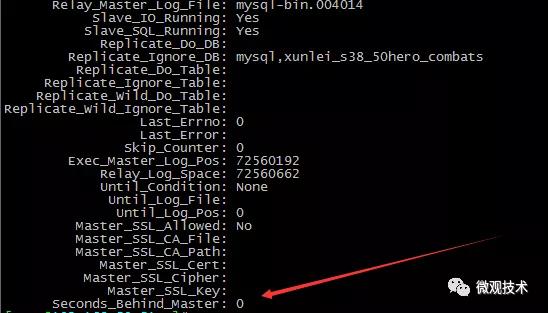
- 為零:表示主從復制良好
- 正值:表示主從已經出現延時,數字越大,表示從庫延遲越嚴重
主從延遲要怎么解決?
答案:
- 看業務的接受程度。如果不能接受延遲,那么建議強制走主庫查詢
- 可以考慮引入緩存,更新主庫后同步寫入緩存,保證緩存的及時性
- 提升從庫的機器配置,提高從庫binlog的同步效率
- 縮短主、從庫的網絡距離,減少binlog的網絡傳輸時間
- 一主多從,每個從庫都啟一個線程從主庫同步 binlog,導致主庫壓力過大,可以采用canal 增量訂閱&消費組件,緩解主庫壓力。
- 因為數據庫必須要等到事務完成之后才會寫入binlog,所以減少大事務的執行,盡量控制數量,分批執行。
- 5.6版本之前,從庫是單線程復制,當遇到執行慢的sql時,就會阻塞后面的同步。5.7 版本后支持多線程復制,可以在從服務上設置slave_parallel_workers為一個大于0的數,然后把slave_parallel_type參數設置為LOGICAL_CLOCK
- 為從庫增加浮動IP,并通過腳本檢測從庫的延遲,延遲大于指定閾值時,將浮動IP切換至Master庫,追平后再切換回從庫。
如果數據量太大怎么辦?
答案:mysql表的數據量一般控制在千萬級別,如果再大的話,就要考慮分庫分表。除了分表外,列舉了面對海量數據業務的一些常見優化手段
- 緩存加速
- 讀寫分離
- 垂直拆分
- 分庫分表
- 冷熱數據分離
- ES助力復雜搜索
- NoSQL
- NewSQL
分表后ID如何保證全局唯一呢?
答案:分庫分表后,多張表共用一套全局id,原來單表主鍵自增方式滿足不了要求。我們需要重新設計一套id生成器。特點:全局唯一、高性能、高可用、方便接入。
- UUID
- 數據庫自增ID
- 數據庫的號段模式,每個業務定義起始值、步長,一次拉取多個id號碼
- 基于Redis,通過incr命令實現ID的原子性自增。
- 雪花算法(Snowflake)
- 市面的一些開源框架,如:百度(uid-generator),美團(Leaf), 滴滴(Tinyid)等
分表后可能遇到的哪些問題?
答案:分表后,與單表的最大區別是有分表鍵sharding_key,用來路由具體的物理表,以電商為例,有買家和賣家兩個維度,以buyer_id路由,無法滿足賣家的需求,反之同樣道理。如何解決?
- 分買家庫和賣家庫,將買家庫做為寫庫,保存完整的數據關系。同時將數據異構同步一份到賣家庫,賣家庫可以只存儲seller_id,order_id,buyer_id 等幾個簡單關系字段即可,以seller_id作為分表鍵
- 多線程掃描,分段查找,然后再聚合結果
- 另外也可以存到ES中,支持多維度復雜搜索