Facebook全球6小時宕機原因查明:一條指令所致,內部工程師所為
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
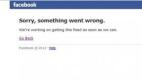
Facebook全球宕機6小時的原因,是公司內部工程師的一條錯誤指令。
最近,Facebook官方針對這次大規模宕機的原因做了回應。

這一新聞已經出現在了微博熱榜。

而在回復中,官方也(針對各種神奇的假說)強調:
沒有黑客惡意攻擊行為,用戶的數據也沒有受到損害。

在第二天,Facebook又發了另一則聲明,詳細地說明了這次宕機的技術細節。
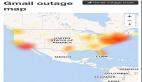
那么這場Facebook有史以來持續時間最長,規模最大,造成公司股價蒸發百億的宕機到底是因為什么?
一起來看看。
日常維護切斷網絡
一切都開始于日常維護中的一條錯誤指令。
也就是Facebook engineering平臺上的聲明中所提到的“配置變化”:
協調數據中心之間網絡流量的主干路由器的配置變化導致了通信中斷,進而影響了數據中心的的通信方式,最后導致了服務中斷。

在日常維護網絡基礎設施時,工程師經常需要離線維護部分主干網,比如修理一條光纖線路,增加更多容量,或者更新路由器本身的軟件。
而上面提到的“配置變化”,就是日常維護工作中主要用于檢測Facebook主干網絡的可用性的一條命令。
當然肯定有應對這種命令的保護措施,但不巧審計工具(audit tool)中出了個bug……

于是,這個“配置變化”就撒著歡兒,啪一下把Facebook主干網絡的所有連接都給切斷了。
這一斷,應用程序對數據的刷新搜索,上傳下載等請求就無法從用戶設備傳到最近的數據中心了。
而這些數據中心不僅有容納了數百萬臺存儲數據機器,用于支撐平臺運行的大型建筑,還有將主干網絡連接到更廣泛的互聯網和具體應用平臺的較小設施。
嗯,差不多就是這樣的嚴重性……
這還沒完。
上述數據中心里的小型設施還有一個工作,那就是響應DNS查詢。
DNS是互聯網的地址簿,能夠將瀏覽器中鍵入的簡單網絡名稱轉換為特定的服務器IP地址。
而這些地址又通過邊界網關協議(BGP)向互聯網其他地址進行廣播,類似一個地圖,提供通往各種目的地的線路。
當DNS服務器發現主干網絡失去了與互聯網的連接時,BGP的“廣播”也隨之停止。
相當于Facebook短暫地被從互聯網這塊地圖上抹除了存在。
只有Facebook受傷的世界完成了
當然,在派遣工程師進入現場數據中心進行修復之后,網絡服務也在10月4日下午4點左右逐漸恢復。

在官方回復的最后,他們也提到會通過這次的“演習”加強系統故障的測試、訓練和整體恢復能力。
而縱觀這次全球大宕機,不僅國外熱度爆表,就連國內也上了熱搜。

國內外的網友們弔圖一堆,苦中作樂。
同為社交媒體的Twitter則高傲盡數顯現。
甚至連Netflix都過來蹭了把熱度,順帶了夾雜了新劇宣傳私貨:

而Facebook在這次事件中股價暴跌6%,扎克伯格個人財富一日蒸發逾60億美元。
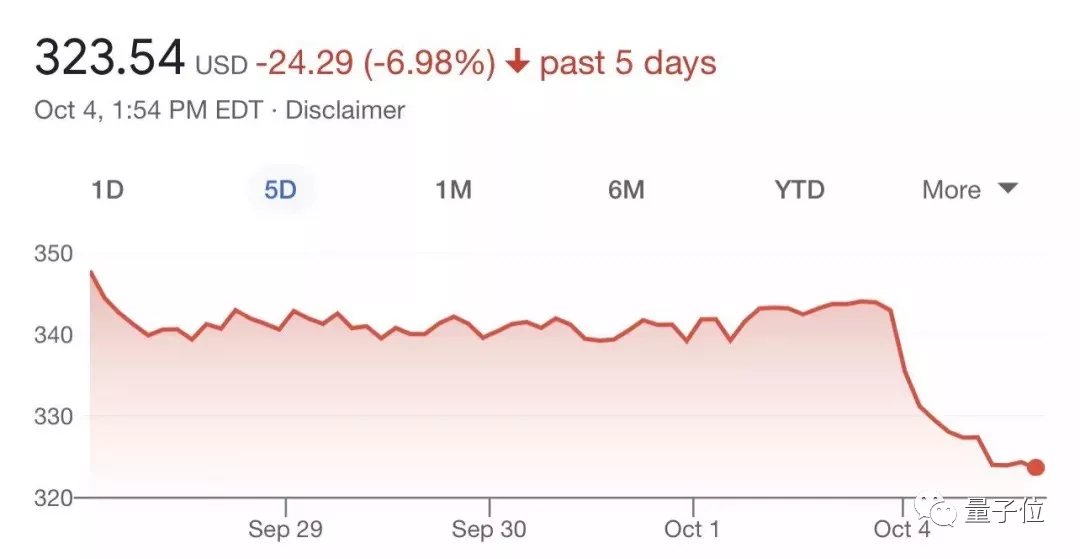
現在看來,只有小扎受傷的世界完成了(狗頭)。
官方回應:
[1]https://engineering.fb.com/2021/10/04/networking-traffic/outage/
[2]https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/