Node工作負載異常,一部分Pod狀態為Terminating
本文轉載自微信公眾號「運維開發故事」,作者沒有文案的夏老師。轉載本文請聯系運維開發故事公眾號。
pod狀態為Terminating
在節點處于“NotReady”狀態時,deployment控制器會遷移節點上的容器實例,并將節點上運行的pod置為“Terminating”狀態。待節點恢復后,處于“Terminating”狀態的pod會自動刪除。偶現部分pod(實例)一直處于“Terminating ”狀態,發現這部分的pod沒有得到重新調度,不能提供服務。
Terminating不是pod生命周期PodStatus中的phase字段。會不會導致一些問題呢?我們來了解一下pod的生命周期與驅逐相關的概念。
pod的生命周期
Pod對象自從其創建開始至其終止退出的時間范圍稱為其生命周期。在這段時間中,Pod會處于多種不同的狀態,并執行一些操作;其中,創建主容器(main container)為必需的操作,其他可選的操作還包括運行初始化容器(init container)、容器啟動后鉤子(post start hook)、容器的存活性探測(liveness probe)、就緒性探測(readiness probe)以及容器終止前鉤子(pre stop hook)等,這些操作是否執行則取決于Pod的定義。如下圖所示:
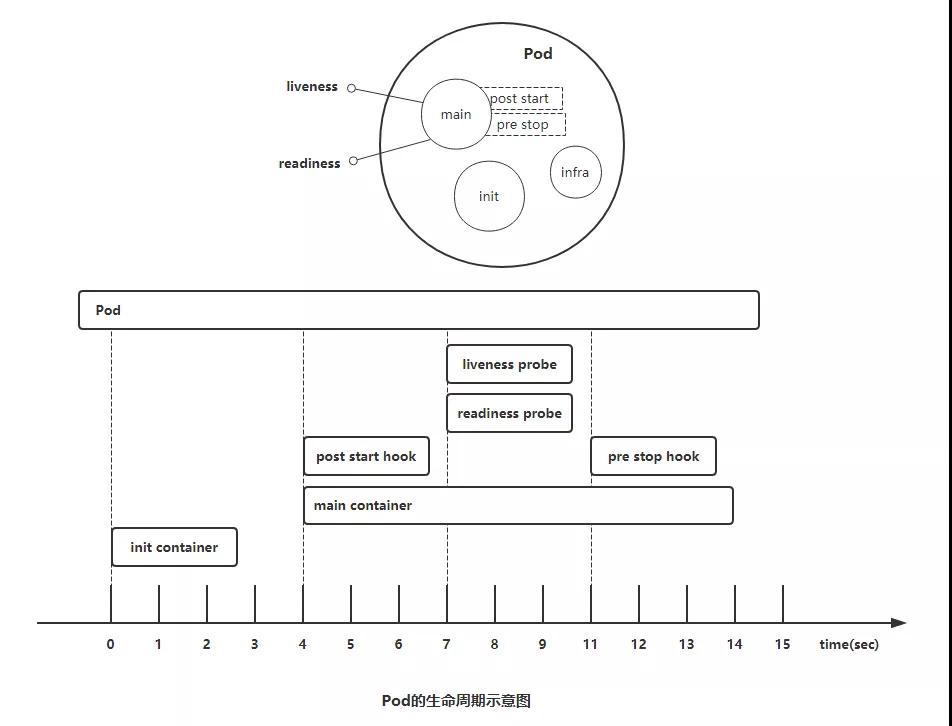
Pod 的生命周期
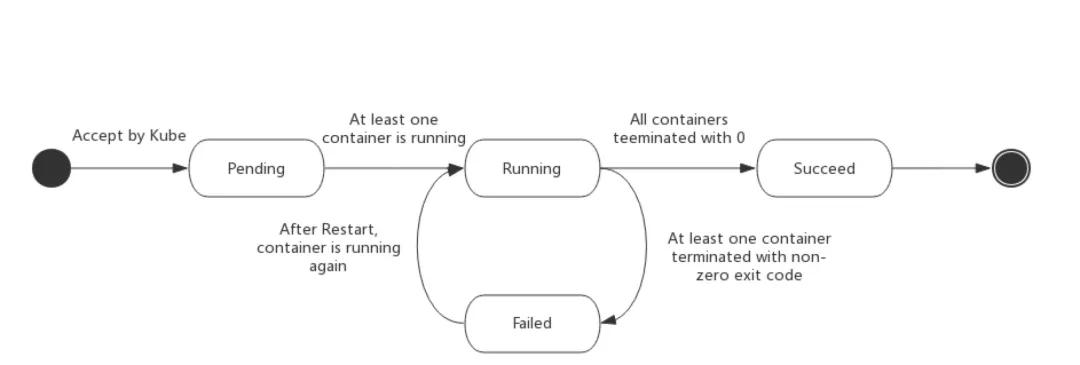
Pod的status字段是一個PodStatus的對象,PodStatus中有一個phase字段。無論是手動創建還是通過Deployment等控制器創建,Pod對象總是應該處于其生命進程中以下幾個階段(phase)之一。
- 掛起(Pending):API Server創建了pod資源對象已存入etcd中,但它尚未被調度完成,或者仍處于從倉庫下載鏡像的過程中。
- 運行中(Running):Pod已經被調度至某節點,并且所有容器都已經被kubelet創建完成。
- 成功(Succeeded):Pod中的所有容器都已經成功終止并且不會被重啟
- 失敗(Failed):Pod中的所有容器都已終止了,并且至少有一個容器是因為失敗終止。即容器以非0狀態退出或者被系統禁止。
- 未知(Unknown):Api Server無法正常獲取到Pod對象的狀態信息,通常是由于無法與所在工作節點的kubelet通信所致。
注意:當一個 Pod 被刪除時,它會Terminating被一些 kubectl 命令顯示為。此Terminating狀態不是 Pod 階段之一。Pod 默認的正常終止的期限,默認為 30 秒。您可以使用該標志--force來強行終止pod。
Pod是kubernetes的基礎單元,理解它的創建過程對于了解系統運作大有裨益。如下圖描述了一個Pod資源對象的典型創建過程。

- 用戶通過kubectl或其他API客戶端提交了Pod Spec給API Server。
- API Server嘗試著將Pod對象的相關信息存入etcd中,待寫入操作執行完成,API Server即會返回確認信息至客戶端。
- API Server開始反映etcd中的狀態變化。
- 所有的kubernetes組件均使用“watch”機制來跟蹤檢查API Server上的相關的變動。
- kube-scheduler(調度器)通過其“watcher”覺察到API Server創建了新的Pod對象但尚未綁定至任何工作節點。
- kube-scheduler為Pod對象挑選一個工作節點并將結果信息更新至API Server。
- 調度結果信息由API Server更新至etcd存儲系統,而且API Server也開始反映此Pod對象的調度結果。
- Pod被調度到的目標工作節點上的kubelet嘗試在當前節點上調用Docker啟動容器,并將容器的結果狀態返回送至API Server。
- API Server將Pod狀態信息存入etcd系統中。
- 在etcd確認寫入操作成功完成后,API Server將確認信息發送至相關的kubelet,事件將通過它被接受。
刪除 Pod的邏輯
當發起一個刪除 Pod 的指令時 Pod 的刪除邏輯是這樣的:
- 調用 kube-apiserver 發起刪除 Pod 請求,如果刪除 Pod 時沒有設置 grace period 參數那么就會使用 30 秒的默認值,否則就會使用用戶指定的 grace period 進行優雅下線
- kube-apiserver 接受到這個請求以后給相應的 Pod 標記為“刪除狀態”。其實 Pod 沒有“刪除狀態”,此時 Pod 的 status 還是 Running 狀態,所謂的“刪除狀態”只是 deletionTimestamp 和 deletionGracePeriodSeconds 字段會被設置,這時候 kubelet 或者 kube-proxy 監聽到這樣的 Pod 就會認為此 Pod 已經不能提供服務了,然后開始做相應的清理操作。
- 此時如果通過 Dashbord 查看 Pod 的狀態是 Terminating ,其實 Terminating 也不是 Pod status 的字段的值。只是因為設置了 deletionTimestamp 和 deletionGracePeriodSeconds 字段所以 Dashbord 就會把 Pod 標記為 Terminating 狀態。
- (和第三條同時發生)當 kube-proxy 監聽到 Pod 處于 Terminatiing 狀態時就把 Pod 從 Service 的 EndPoint 中摘掉,這樣對外暴露的服務就摘掉了這個 Pod,防止新的請求發送到這個 Pod 上來
- kubelet 監測到 Pod 處于 Terminating 狀態的話會下線 Pod,下線的過程分成兩個步驟。1. 執行 PreStop 2. 殺死容器。第一步:如果 Pod 設置了 PreStop hook 的話 kubelet 監測到 Pod 處于 Terminating 狀態后就會執行 PreStop 操作,執行 PreStop 設置的超時時間和刪除 Pod 時指定的 grace period 一致(如果沒設置默認是 30 秒)
- PreStop 執行完以后還有第二步殺死容器,第二部也有超時時間,這個超時時間是 grace period 減去 PreStop 耗時。如果執行 PreStop 超時或者 grace period 減去 PreStop 耗時剩余的時間不夠兩秒(甚至可能是負數) kubelet 會強制設置成兩秒。第二部的超時時間暫且稱之為 tm2, kubelet 停止容器時執行的是 docker stop -t tm2 命令。所以 tm2 的邏輯是:首先發送 term 信號到容器的一號進程,如果容器在 tm2 時間內沒有停止就強制發送 kill 信號殺死容器
- kubelet 執行完 PreStop 和殺死容器兩步以后會回調 kube-apiserver,把 Pod 從 kube-apiserver 中刪除,這次的刪除是真的刪除,這時候通過 API 就再也看不到這個 Pod 的信息了
Eviction介紹
Eviction,即驅逐的意思,意思是當節點出現異常時,為了保證工作負載的可用性,kubernetes將有相應的機制驅逐該節點上的Pod。目前kubernetes中存在兩種eviction機制,分別由kube-controller-manager和kubelet實現。
kube-controller-manager實現的eviction
kube-controller-manager主要由多個控制器構成,而eviction的功能主要由node controller這個控制器實現。該Eviction會周期性檢查所有節點狀態,當節點處于NotReady狀態超過一段時間后,驅逐該節點上所有pod。kube-controller-manager提供了以下啟動參數控制eviction:
- pod-eviction-timeout:即當節點宕機該時間間隔后,開始eviction機制,驅趕宕機節點上的Pod,默認為5min。
- node-eviction-rate:驅趕速率,即驅趕Node的速率,由令牌桶流控算法實現,默認為0.1,即每秒驅趕0.1個節點,注意這里不是驅趕Pod的速率,而是驅趕節點的速率。相當于每隔10s,清空一個節點。
- secondary-node-eviction-rate:二級驅趕速率,當集群中宕機節點過多時,相應的驅趕速率也降低,默認為0.01。
- unhealthy-zone-threshold:不健康zone閾值,會影響什么時候開啟二級驅趕速率,默認為0.55,即當該zone中節點宕機數目超過55%,而認為該zone不健康。
- large-cluster-size-threshold:大集群閾值,當該zone的節點多余該閾值時,則認為該zone是一個大集群。大集群節點宕機數目超過55%時,則將驅趕速率降為0.01,假如是小集群,則將速率直接降為0。
由kube-controller-manager觸發的驅逐,會留下一個狀態為Terminating的pod,想要刪除這些狀態的 Pod 有三種方法:
- 從集群中刪除該 Node。使用公有云時,kube-controller-manager 會在 VM 刪除后自動刪除對應的 Node。而在物理機部署的集群中,需要管理員手動刪除 Node(如 kubectl delete node。
- Node 恢復正常。Kubelet 會重新跟 kube-apiserver 通信確認這些 Pod 的期待狀態,進而再決定刪除或者繼續運行這些 Pod。
- 用戶強制刪除。用戶可以執行 kubectl delete pods--grace-period=0 --force 強制刪除 Pod。除非明確知道 Pod 的確處于停止狀態(比如 Node 所在 VM 或物理機已經關機),否則不建議使用該方法。特別是 StatefulSet 管理的 Pod,強制刪除容易導致腦裂或者數據丟失等問題。
kubelet的eviction機制
如果節點處于資源壓力,那么kubelet就會執行驅逐策略。驅逐Pod會考慮優先級,資源使用和資源申請。當優先級相同時,資源使用/資源申請最大的Pod會被首先驅逐。kube-controller-manager的eviction機制是粗粒度的,即驅趕一個節點上的所有pod,而kubelet則是細粒度的,它驅趕的是節點上的某些Pod,驅趕哪些Pod與Pod的Qos機制有關。該Eviction會周期性檢查本節點內存、磁盤等資源,當資源不足時,按照優先級驅逐部分pod。驅逐閾值分為軟驅逐閾值(Soft Eviction Thresholds)和強制驅逐(Hard Eviction Thresholds)兩種機制,如下:kubelet提供了以下參數控制eviction:
- 軟驅逐閾值:當node的內存/磁盤空間達到一定的閾值后,kubelet不會馬上回收資源,如果改善到低于閾值就不進行驅逐,若這段時間一直高于閾值就進行驅逐。
- 強制驅逐:強制驅逐機制則簡單的多,一旦達到閾值,直接把pod從本地驅逐。
- eviction-soft:軟驅逐閾值設置,具有一系列閾值,比如memory.available<1.5Gi時,它不會立即執行pod eviction,而會等待eviction-soft-grace-period時間,假如該時間過后,依然還是達到了eviction-soft,則觸發一次pod eviction。
- eviction-soft-grace-period:默認為90秒,當eviction-soft時,終止Pod的grace的時間,即軟驅逐寬限期,軟驅逐信號與驅逐處理之間的時間差。
- eviction-max-pod-grace-period:最大驅逐pod寬限期,停止信號與kill之間的時間差。
- eviction-pressure-transition-period:默認為5分鐘,脫離pressure condition的時間,超過閾值時,節點會被設置為memory pressure或者disk pressure,然后開啟pod eviction。
- eviction-minimum-reclaim:表示每一次eviction必須至少回收多少資源。
- eviction-hard:強制驅逐設置,也具有一系列的閾值,比如memory.available<1Gi,即當節點可用內存低于1Gi時,會立即觸發一次pod eviction。
由kubelet觸發的驅逐,會留下一個狀態為Evicted的pod,此pod只是方便后期定位的記錄,可以直接刪除。
總結:
偶現部分pod(實例)一直處于“Terminating ”狀態,發現這部分的pod沒有得到重新調度,不能提供服務。這一類deployment其發布策略是Recreate模式(先刪舊POD,再啟動新POD)。該問題對于rollout滾動發布的deployment沒有影響,僅對recreate的造成影響(類似statefulset也有影響)根據以上描述deployment最好使用rollout滾動發布策略。
部分pod(實例)一直處于“Terminating ”狀態,情況分為很多種,這里騰訊云做過一個總結:
《Pod 一直處于 Terminating 狀態》。
https://cloud.tencent.com/document/product/457/43238
有興趣的可以去了解一下。
想要刪除這些狀態的 Pod 有三種方法:
- 從集群中刪除該 Node。使用公有云時,kube-controller-manager 會在 VM 刪除后自動刪除對應的 Node。而在物理機部署的集群中,需要管理員手動刪除 Node(如 kubectl delete node。
- Node 恢復正常。Kubelet 會重新跟 kube-apiserver 通信確認這些 Pod 的期待狀態,進而再決定刪除或者繼續運行這些 Pod。
- 用戶強制刪除。用戶可以執行 kubectl delete pods--grace-period=0 --force 強制刪除 Pod。除非明確知道 Pod 的確處于停止狀態(比如 Node 所在 VM 或物理機已經關機),否則不建議使用該方法。特別是 StatefulSet 管理的 Pod,強制刪除容易導致腦裂或者數據丟失等問題。
參考文章:
https://feisky.gitbooks.io/kubernetes/content/troubleshooting/pod.html
https://v1-20.docs.kubernetes.io/docs/concepts/workloads/pods/#
https://v1-20.docs.kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
https://cloud.tencent.com/document/product/457/43238