突破 100 種,微軟翻譯新增對 12 種語言/方言支持,包括藏語、維吾爾語...
IT之家 10 月 12 日消息,微軟翻譯今天宣布支持 12 種新的語言和方言。有了這項支持,微軟翻譯現在總共支持 103 種語言,覆蓋了世界人口的 72%。有了這個版本,微軟翻譯服務可以將文本和文件翻譯成全世界 56.6 億人所使用的本土語言。

IT之家獲悉,微軟翻譯新增加的語言是巴什基爾語、迪維希語、格魯吉亞語、吉爾吉斯語、馬其頓語、蒙古語(西里爾語)、蒙古語(傳統版)、塔塔爾語、藏語、土庫曼語、維吾爾語和烏茲別克語(拉丁語)。這些新語言有 8460 萬人使用。
微軟技術研究員和 Azure 人工智能首席技術官黃學東說:“一百種語言對我們來說是一個很好的里程碑,可以實現我們的雄心壯志,讓每個人無論說什么語言都能進行交流。”
微軟翻譯的演變
20 多年前,微軟研究院首次開發了機器翻譯系統。2003 年,一個機器翻譯系統將整個微軟知識庫從英文翻譯成西班牙文、法文、德文和日文,并將翻譯內容發布在其網站上,成為當時互聯網上最大的面向公眾的原始機器翻譯應用。
微軟在統計機器翻譯(SMT)模型的基礎上進一步發展了這些系統,并通過 Windows Live Translator、Translator API 以及微軟 Office 應用程序的內置功能向公眾提供。
微軟表示,多年來,我們為世界上許多最常用的語言增加了翻譯系統。隨著人工智能(AI)技術的發展,微軟采用了神經機器翻譯(NMT)技術,并將所有機器翻譯系統遷移到基于 Transformer 技術的神經模型上,實現了翻譯流暢性和準確性的巨大提升。
雖然 NMT 技術顯著提高了整體翻譯質量,但 Transformer 架構的出現為創建機器翻譯模型鋪平了新的道路,使其能夠用比以前更少的材料進行訓練。使用多語言 Transformer 架構,現在可以用其他語言的材料來增加訓練數據,通常是在同一或相關的語言家族中,為數據量小的語言制作模型,通常被稱為低資源語言。
即使有了這些技術,也必須要有一套目標語言的數字文件,以及另一種已經包括在內的語言的翻譯--通常被稱為 parallel 文件。
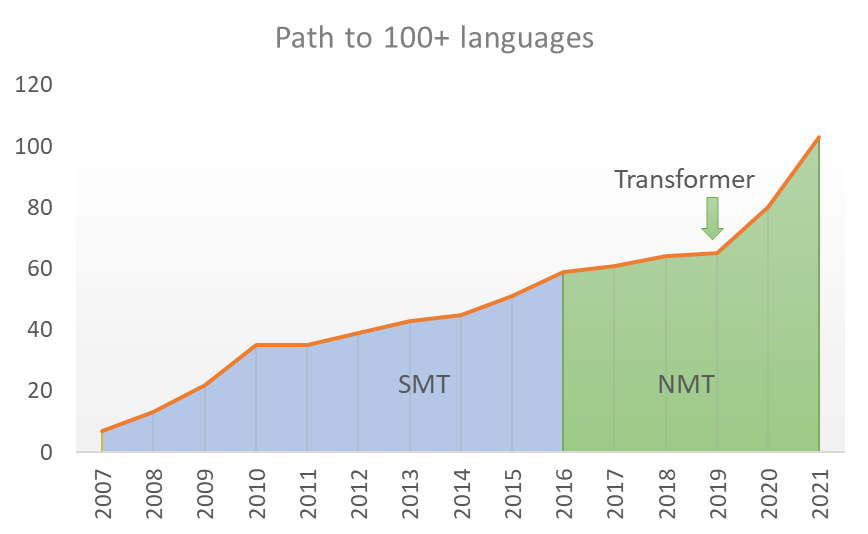
▲ 微軟翻譯所翻譯的語言數量折線圖,從 2007 年的 7 種到 2021 年的 100 多種。該系統從 2007 年到 2016 年一直使用統計機器翻譯(SMT)。2016 年采用神經機器翻譯(NMT)技術有助于提高翻譯質量,2019 年采用 Transformer 架構,使微軟團隊能夠用較少的數據量為低資源語言建立模型。
在增加新語言時,微軟表示,最大的挑戰之一是獲得訓練和制作機器翻譯模型所需的足夠的雙語數據。這些數據由高質量的人工翻譯內容組成,既包括想要添加的語言,也包括該服務已經支持的語言之一。對于許多語言來說,這種雙語數據是很難獲得的,特別是對于數字資源不足或瀕臨滅絕的語言。
微軟稱,很幸運與語言社區的伙伴合作,他們可以獲得人工翻譯的文本,并可以幫助收集資源不足的語言的數據。這些社區合作伙伴,通常是與他們各自社區合作的志愿者,通過咨詢社區成員,不辭辛苦地收集雙語句子。然后,他們評估所產生的機器翻譯模型的質量。
Azure 認知服務翻譯在微軟產品中公開了 NMT 模型,并通過文本翻譯和文檔翻譯 API 向翻譯客戶公開。這些 API 將純文本和復雜文件從一種語言翻譯成另一種語言。Azure 認知服務翻譯器 API 可在公共云和安全的微軟 Azure 政府云中使用。此外,文本翻譯 API 在 Docker 容器中可用,允許客戶在企業內部處理內容以滿足特定的監管要求。
Azure 認知服務翻譯還包括自定義翻譯服務,該服務使用戶能夠使用自己的翻譯記憶庫來建立自定義機器翻譯模型,以翻譯其業務和相關行業中使用的特定領域術語。這些自定義機器翻譯模型可以通過文本和文檔翻譯 API 使用。
為了翻譯音頻或語音內容,Azure 認知服務翻譯與 Azure 認知服務語音緊密結合,通過 Azure 語音 SDK 支持語音翻譯和多設備對話。
Azure 認知服務翻譯器及其支持的產品被客戶廣泛采用。該服務無縫集成到許多微軟產品中,并隨時供每個人使用和創建他們選擇的語言內容。一些微軟產品整合包括用于翻譯文本和文件的 Microsoft 365,用于翻譯整個網頁的 Microsoft Edge 瀏覽器,用于翻譯信息的 SwiftKey,用于翻譯用戶提交的內容的 LinkedIn,用于在移動中進行多語言對話的 Translator 應用程序,以及更多。