500億參數,支持103種語言:谷歌推出「全球文字翻譯」模型
由于缺乏平行數據,小語種的翻譯一直是一大難題。來自谷歌的研究者提出了一種能夠翻譯 103 種語言的大規模多語言神經機器翻譯模型,在數據豐富和匱乏的語種翻譯中都實現了顯著的性能提升。他們在 250 億個的句子對上進行訓練,參數量超過 500 億。
在過去的幾年里,由于神經機器翻譯(NMT)的發展,機器翻譯(MT)系統的質量得到了顯著提升,打破了世界各地的語言障礙。但 NMT 的成功很大程度上要歸功于有監督的訓練數據。那么,數據較少甚至沒有數據的語言該怎么辦呢?多語言 NMT 是一種有效的解決方法,它有一種歸納偏見,即「來自一種語言的學習信號應該有助于提高其他語言的翻譯質量」。
多語言機器翻譯使用一種語言模型處理多種語言。數據匱乏語種多語言訓練的成功已經應用于自動語言識別、文本轉語音等系統。谷歌的研究者之前探索過擴展單個神經網絡可以學習的語言數量,同時控制每種語言的訓練數據量。但如果將所有限制因素都移除會發生什么?我們能否使用所有可用數據訓練單個模型——即使這些數據的大小、腳本、復雜度和領域都各不相同。
在一篇名為「Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges」的論文和后續幾篇論文中,谷歌的研究者們在超過 250 億的句子對上訓練了一個 NMT 模型,這些句子是 100 多種語言與英語的互譯,參數量超過 500 億。他們得到了一種大規模多語言、大規模神經機器翻譯方法 M4,在數據豐富和匱乏的語言中都實現了顯著的性能提升,可以輕松適應單個領域/語言,同時能夠有效應用于跨語言下游遷移任務。
大規模多語言機器翻譯
盡管跨語言對數據傾斜是 NMT 任務中的一大挑戰,但這種傾斜也為研究遷移創造了一種理想情景,在一種語言上訓練得到的信息可以應用到其他語言的翻譯中。法語、德語、西班牙語等數據豐富的語言占據分布的一端,提供了數十億的平行語料;約魯巴語、信德語、夏威夷語等數據匱乏的語言占據分布的另一端,只有幾萬的語料。
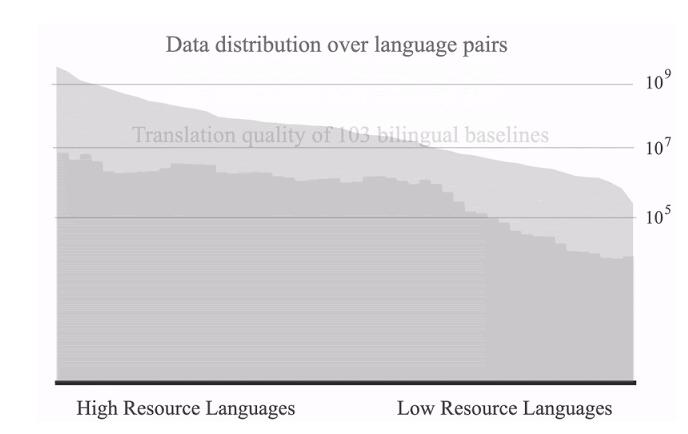
所有語言對的數據分布(取對數)和在每個特定語言對上訓練得到的雙語基線的相對翻譯質量(BLEU 分數)。
使用所有可用數據(來自 103 種語言的 250 億個樣本)訓練之后,研究者觀察到,數據匱乏語言有著強烈的正向遷移傾向,30 多種語言的翻譯質量得到了顯著提高,數據分布尾部的 BLEU 分數平均提高了 5 分。效果是已知的,但卻非常鼓舞人心,因為比較是在雙語基線(即只在特定語言對上訓練得到的模型)和單個多語言模型之間進行的,后者擁有類似于單個雙語模型的表征能力。這一發現表明,大規模多語言模型可以有效泛化,而且能夠捕捉大量語言之間的表征相似性。
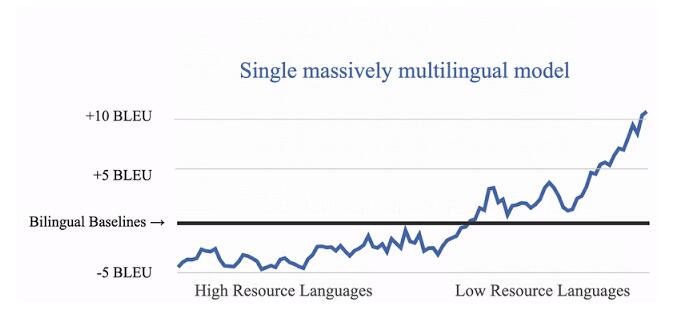
單個大規模多語言模型與雙語基線模型之間的翻譯質量對比。
在一篇名為「Investigating Multilingual NMT Representations at Scale」的 EMNLP 2019 論文中,谷歌的研究者比較了多語言模型在多種語言中的表征能力。他們發現,多語言模型無需外部限制就能學習在語言學上相似的語言的共享表征,驗證了長期以來利用這些相似性的直覺和實驗結果。
在「Evaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation」一文中,研究者進一步證明了這些學習到的表征在下游任務中跨語言遷移的有效性。
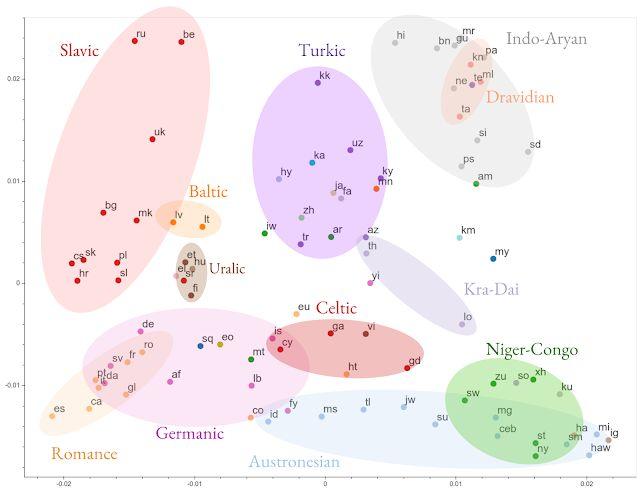
所有 103 種語言編碼表征聚類的可視化,基于表征相似性。不同的顏色代表不同的語系。
構建大規模神經網絡
在增加數據匱乏的語種數量之后,數據豐富的語種翻譯質量開始下降。這種下降在多任務設置中可以被觀察到,由任務間的競爭和遷移的單向性引起(即從數據豐富的語言到數據匱乏的語言)。研究人員探索了能夠更好地學習和實現能力控制的算法,以此來解決這種負遷移問題。在此過程中,他們還通過增加神經網絡模型的參數量來提高其表征能力,以此來提高數據豐富語言的翻譯質量。
提高神經網絡的能力還有其他幾種方法,包括添加層數、增加隱藏表征的寬度等。為了訓練更深的翻譯模型,研究者利用 GPipe 來訓練 128 層、參數超過 60 億的 Transformer。模型能力的提高使得所有語言的翻譯質量都得到了顯著提升,BLEU 分數平均提高了 5 分。他們還研究了深度網絡的其他性質,包括深度-寬度權衡、可訓練性難題以及將 transformer 擴展到 1500 多層、840 億參數的設計選擇等。
盡管擴展深度是提高模型能力的一種方法,探索能夠利用問題多任務特性的架構也是一種非常可行的補充方法。研究者通過用稀疏門控專家混合層(sparsely-gated mixture of experts)替代原始的前饋層修改 transformer 的架構,顯著提高了模型能力,使得我們可以成功地訓練和傳遞 500 億參數,從而進一步提高了翻譯質量。
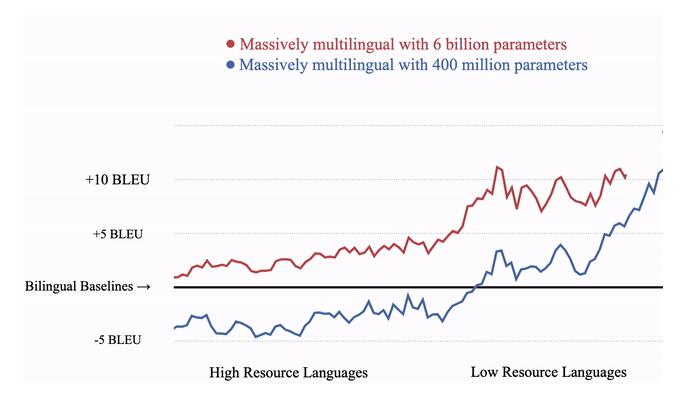
與 103 個雙語翻譯基準相比,谷歌的新方法在單個多語言模型上提高了容量(參數量),進而提高了翻譯質量。
讓 M4 模型實用化
對于每個語言的領域或遷移任務來說,訓練大型模型,花費大量算力非常不經濟。谷歌提出的方法通過使用容量可調層使新模型適應特定的語言或領域,無需更改原始模型,使得這些模型變得更加實用。
展望
有研究顯示,到 21 世紀末,全球至少有 7000 種目前正在使用的語言將會不復存在。多語言機器翻譯系統可以拯救這些語言嗎?谷歌認為,M4 是通向另外 1000 種語言翻譯的基石。從這類多語言模型開始,即使沒有平行語料,我們也可以輕松地將機器翻譯擴展到新的語言、領域和下游任務中去。在通用機器翻譯的方向上,很多有希望的解決方案似乎是跨領域的,多語言 NMT 正在成為多任務學習、元學習、深層網絡訓練等機器學習技術的理想測試平臺。