大模型高效釋放生產性能,HuggingFace開源Transformer擴展優化庫
特斯拉、谷歌、微軟、Facebook 等科技巨頭有很多共同點,其中之一是:它們每天都會運行數十億次 Transformer 模型預測。比如,Transformer 在特斯拉 AutoPilot 自動駕駛系統中驅動汽車、在 Gmail 中補全句子、在 Facebook 上及時翻譯用戶的帖子以及在 Bing 中回答用戶的自然語言查詢。
Transformer 在機器學習模型的準確率方面帶來了巨大提升,風靡 NLP 領域,并正在擴展到其它模態上(例如,語音和視覺)。然而,對于任何一個機器學習工程團隊來說,將這些大模型應用于工業生產,使它們大規模快速運行都是一個巨大的挑戰。
如果沒有像上述企業一樣聘用數百名技藝高超的機器學習工程師,應該怎么應用這樣的大規模模型呢?近日,Hugging Face 開源了一個新的程序包「Optimum」,旨在為 Transformer 的工業生產提供最佳的工具包,使得可以在特定的硬件上以最高的效率訓練和運行模型。
項目地址:https://github.com/huggingface/blog/blob/master/hardware-partners-program.md
Optimum 使 Transformer 實現高效工作
為了在訓練和服務模型過程中得到最佳性能,模型加速技術需要與目標硬件兼容。每個硬件平臺都提供了特定的軟件工具、特性和調節方式,它們都會對性能產生巨大影響。同樣地,為了利用稀疏化、量化等先進的模型加速技術,優化后的內核需要與硅上的操作兼容,并特定用于根據模型架構派生的神經網絡圖。深入思考這個三維的兼容性矩陣以及如何使用模型加速庫是一項艱巨的工作,很少有機器學習工程師擁有這方面的經驗。
Optimum 的推出正是為了「簡化這一工作,提供面向高效人工智能硬件的性能優化工具,與硬件合作者合作,賦予機器學習工程師對其機器學習的優化能力。」
通過 Transformer 程序包,研究人員和工程師可以更容易地使用最先進的模型,無需考慮框架、架構、工作流程的復雜性;工程師們還可以輕松地利用所有可用硬件的特性,無需考慮硬件平臺上模型加速的復雜性。
Optimum 實戰:如何在英特爾至強 CPU 上進行模型量化
量化為何如此重要卻又難以實現?
BERT 這種預訓練語言模型在各種各樣的 NLP 任務上取得了目前最佳的性能,而 ViT、SpeechText 等其它基于 Transformer 的模型分別在計算機視覺和語音任務上也實現了最優的效果。Transformer 在機器學習世界中無處不在,會一直存在下去。
然而,由于需要大量的算力,將基于 Transformer 的模型應用于工業生產很困難,開銷巨大。有許多技術試圖解決這一問題,其中最流行的方法是量化。可惜的是,在大多數情況下,模型量化需要大量的工作,原因如下:
首先,需要對模型進行編輯。具體地,我們需要將一些操作替換為其量化后的形式,并插入一些新的操作(量化和去量化節點),其它操作需要適應權值和激活值被量化的情況。
例如,PyTorch 是在動態圖模式下工作的,因此這部分非常耗時,這意味著需要將上述修改添加到模型實現本身中。PyTorch 現在提供了名為「torch.fx」的工具,使用戶可以在不改變模型實現的情況下對模型進行變換,但是當模型不支持跟蹤時,就很難使用該工具。在此基礎之上,用戶還需要找到模型需要被編輯的部分,考慮哪些操作有可用的量化內核版本等問題。
其次,將模型編輯好后,需要對許多參數進行選擇,從而找到最佳的量化設定,需要考慮以下三個問題:
- 應該使用怎樣的觀測方式進行范圍校正?
- 應該使用哪種量化方案?
- 目標設備支持哪些與量化相關的數據類型(int8、uint8、int16)?
再次,平衡量化和可接受的準確率損失。
最后,從目標設備導出量化模型。
盡管 PyTorch 和 TensorFlow 在簡化量化方面取得了很大的進展,但是基于 Transformer 的模型十分復雜,難以在不付出大量努力的情況下使用現成的工具讓模型工作起來。
英特爾的量化神器:Neural Compressor
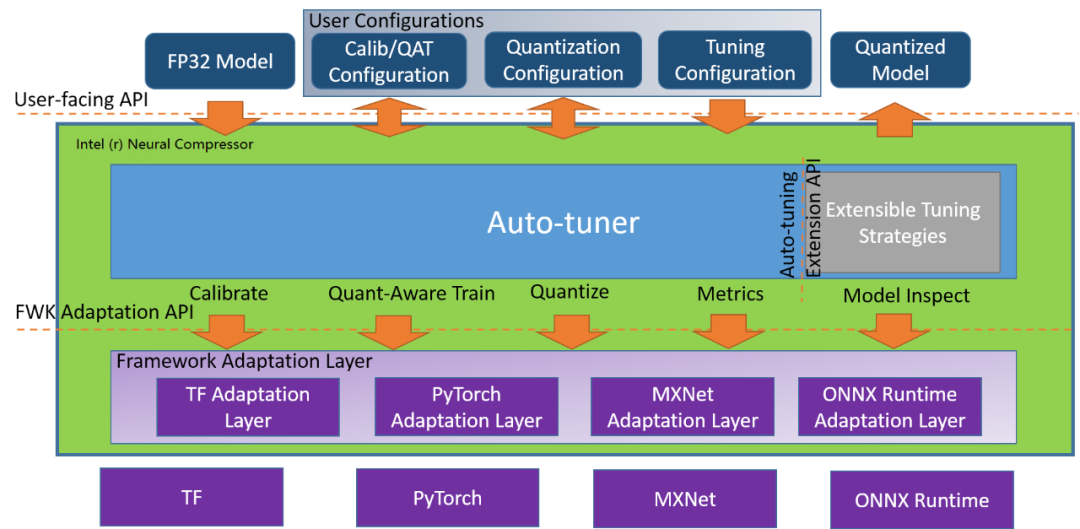
Neural Compressor 架構示意圖。地址:https://github.com/intel/neural-compressor
英特爾開源的 Python 程序庫 Neural Compressor(曾用名「低精度優化工具」——LPOT)用于幫助用戶部署低精度的推理解決方案,它通過用于深度學習模型的低精度方法實現最優的生產目標,例如:推理性能和內存使用。
Neural Compressor 支持訓練后量化、量化的訓練以及動態量化。為了指定量子化方法、目標和性能評測標準,用戶需要提供指定調優參數的配置 yaml 文件。配置文件既可以托管在 Hugging Face 的 Model Hub 上,也可以通過本地文件夾路徑給出。
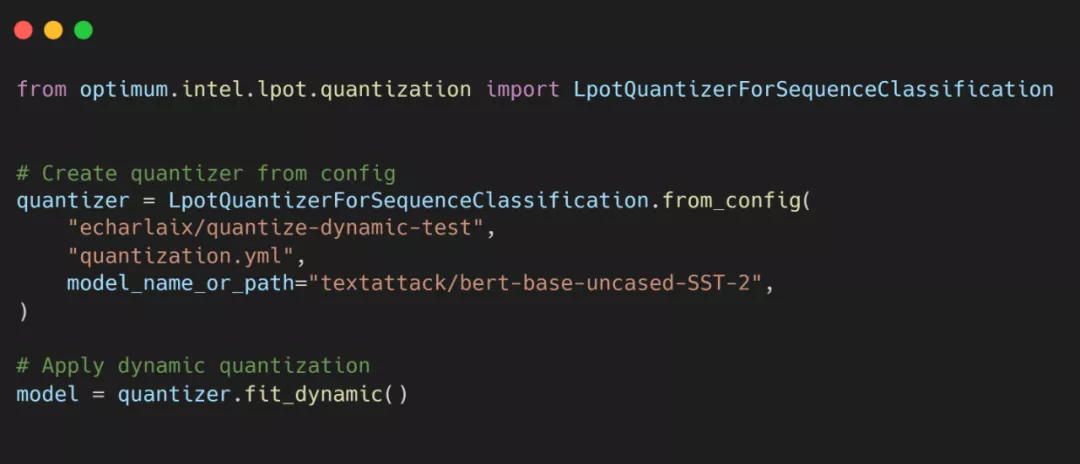
使用 Optimum 在英特爾至強 CPU 上輕松實現 Transformer 量化
實現代碼如下:
踏上 ML 生產性能下放的大眾化之路
SOTA 硬件
Optimum 重點關注在專用硬件上實現最優的生產性能,其中軟件和硬件加速技術可以被用來實現效率最大化。Optimum 團隊將與硬件合作伙伴協作,從而賦能、測試和維護加速技術,將其以一種簡單易用的方式交互。該團隊近期將宣布新的硬件合作者,與其一同實現高效機器學習。
SOTA 模型
Optimum 團隊將與硬件合作伙伴研究針對特定硬件的優化模型設置和組件,成果將在 Hugging Face 模型上向人工智能社區發布。該團隊希望 Optimum 和針對特定硬件優化的模型可以提升生產流程中的效率,它們在機器學習消耗的總能量中占很大的比例。最重要的是,該團隊希望 Optimum 促進普通人對大規模 Transformer 的應用。