面向長代碼序列的 Transformer 模型優化方法,提升長代碼場景性能
阿里云機器學習平臺PAI與華東師范大學高明教授團隊合作在SIGIR2022上發表了結構感知的稀疏注意力Transformer模型SASA,這是面向長代碼序列的Transformer模型優化方法,致力于提升長代碼場景下的效果和性能。由于self-attention模塊的復雜度隨序列長度呈次方增長,多數編程預訓練語言模型(Programming-based Pretrained Language Models, PPLM)采用序列截斷的方式處理代碼序列。SASA方法將self-attention的計算稀疏化,同時結合了代碼的結構特性,從而提升了長序列任務的性能,也降低了內存和計算復雜度。
論文:Tingting Liu, Chengyu Wang, Cen Chen, Ming Gao, and Aoying Zhou. Understanding Long Programming Languages with Structure-Aware Sparse Attention. SIGIR 2022
模型框架
下圖展示了SASA的整體框架:
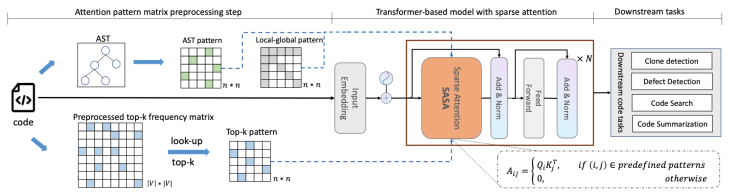
其中,SASA主要包含兩個階段:預處理階段和Sparse Transformer訓練階段。在預處理階段得到兩個token之間的交互矩陣,一個是top-k frequency矩陣,一個是AST pattern矩陣。Top-k frequency矩陣是利用代碼預訓練語言模型在CodeSearchNet語料上學習token之間的attention交互頻率,AST pattern矩陣是解析代碼的抽象語法樹(Abstract Syntax Tree,AST ),根據語法樹的連接關系得到token之間的交互信息。Sparse Transformer訓練階段以Transformer Encoder作為基礎框架,將full self-attention替換為structure-aware sparse self-attention,在符合特定模式的token pair之間進行attention計算,從而降低計算復雜度。
SASA稀疏注意力一共包括如下四個模塊:
- Sliding window attention:僅在滑動窗口內的token之間計算self-attention,保留局部上下文的特征,計算復雜度為,為序列長度,是滑動窗口大小。
- Global attention:設置一定的global token,這些token將與序列中所有token進行attention計算,從而獲取序列的全局信息,計算復雜度為,為global token個數。
- Top-k sparse attention:Transformer模型中的attention交互是稀疏且長尾的,對于每個token,僅與其attention交互最高的top-k個token計算attention,復雜度為。
- AST-aware structure attention:代碼不同于自然語言序列,有更強的結構特性,通過將代碼解析成抽象語法樹(AST),然后根據語法樹中的連接關系確定attention計算的范圍。
為了適應現代硬件的并行計算特性,我們將序列劃分為若干block,而非以token為單位進行計算,每個query block與
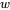
個滑動窗口blocks和
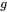
個global blocks以及
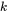
個top-k和AST blocks計算attention,總體的計算復雜度為
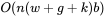
b為block size。
每個sparse attention pattern 對應一個attention矩陣,以sliding window attention為例,其attention矩陣的計算為:
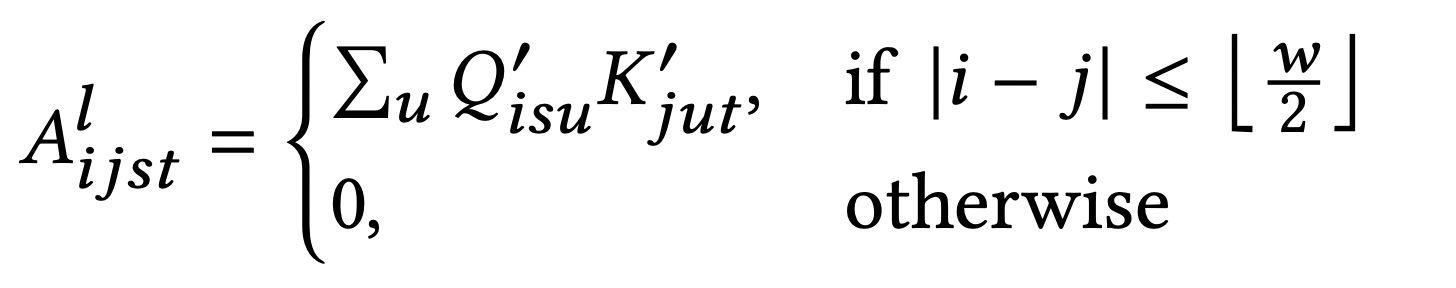
ASA偽代碼:

實驗結果
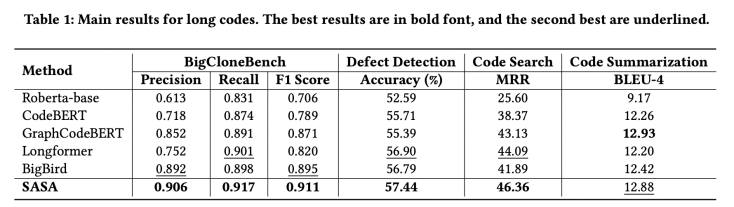
我們采用CodeXGLUE[1]提供的四個任務數據集進行評測,分別為code clone detection,defect detection,code search,code summarization。我們提取其中的序列長度大于512的數據組成長序列數據集,實驗結果如下:
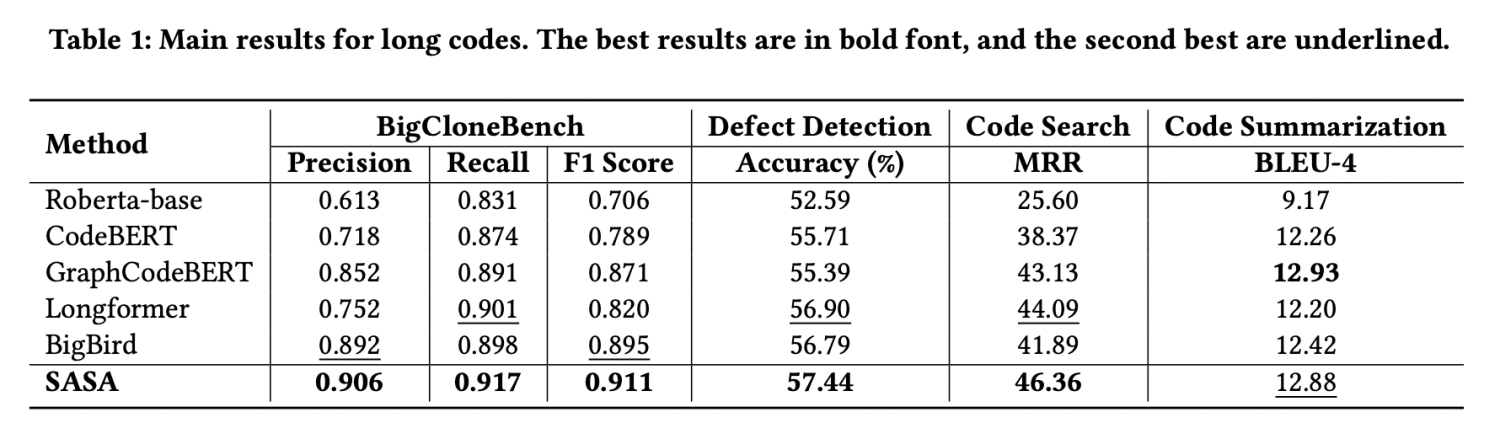
從實驗結果可以看出,SASA在三個數據集上的性能明顯超過所有Baseline。其中Roberta-base[2],CodeBERT[3],GraphCodeBERT[4]是采用截斷的方式處理長序列,這將損失一部分的上下文信息。Longformer[5]和BigBird[6]是在自然語言處理中用于處理長序列的方法,但未考慮代碼的結構特性,直接遷移到代碼任務上效果不佳。
為了驗證top-k sparse attention和AST-aware sparse attention模塊的效果,我們在BigCloneBench和Defect Detection數據集上做了消融實驗,結果如下:
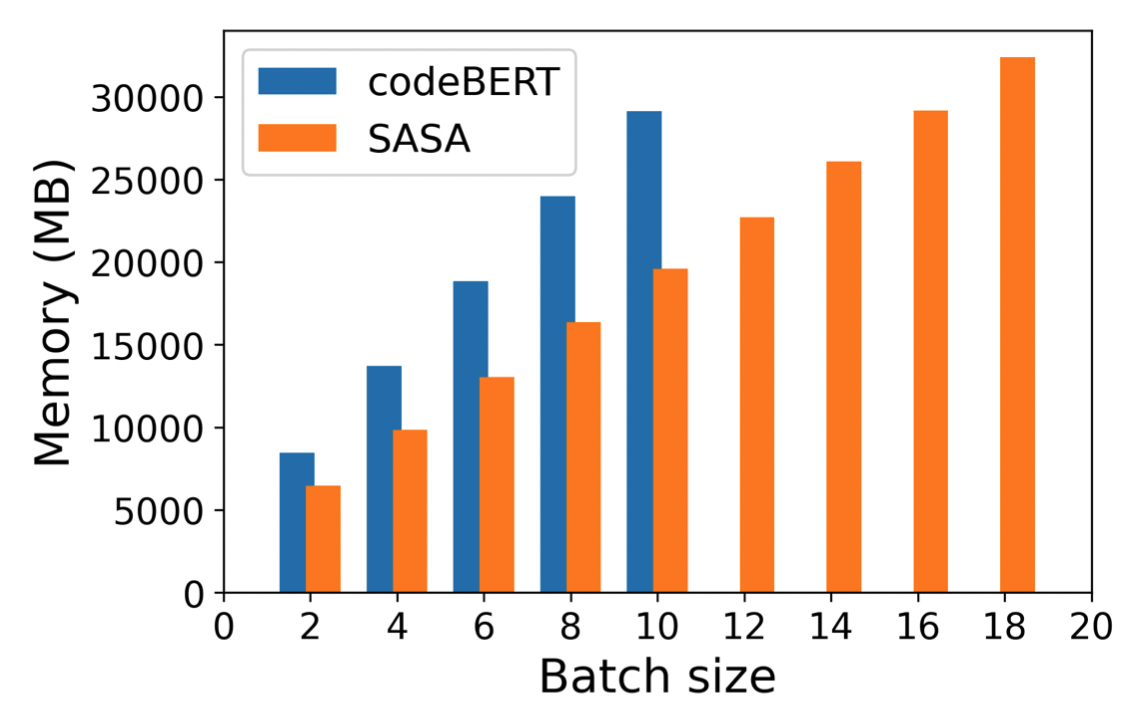
sparse attention模塊不僅對于長代碼的任務性能有提升,還可以大幅減少顯存使用,在同樣的設備下,SASA可以設置更大的batch size,而full self-attention的模型則面臨out of memory的問題,具體顯存使用情況如下圖:
SASA作為一個sparse attention的模塊,可以遷移到基于Transformer的其他預訓練模型上,用于處理長序列的自然語言處理任務,后續將集成到開源框架EasyNLP(https://github.com/alibaba/EasyNLP)中,貢獻給開源社區。
論文鏈接:
https://arxiv.org/abs/2205.13730