「中國達芬奇」機器人火了!除了縫葡萄皮還有這些腦洞大開的操作
自制一個能給葡萄縫針的機械臂?
近日,知名「硬核」up主稚暉君展示了一款自己從零到一設計的小型高精度六軸機械臂Dummy。
視頻一出,直接沖到B站排行榜前十,打開彈幕,滿屏都是驚嘆號。
在「瑟瑟發抖」、「保存=會做」、「他竟然在試圖教會我們」、「我看不懂,但大受震撼」的彈幕之中,有網友說「希望我們也能盡早做出中國版的『達芬奇』機器人」。
不止華為,其實各大科技公司都在發力機器人的技術研究。就在最近舉辦的國際智能機器人與系統大會IROS 2021上,我們就看到了很多熟悉的身影,其中不乏堪比穿針引線的靈活操作技術。
而這其中,有一個你肯定意想不到的名字!
沒條胳膊也算機器人?
雖然現在服務型機器人遍地開花,不過大多只能問個「您好,請問有什么能幫您」,然后回答一個「暫不支持該功能」,連送個外賣都得人追著外賣跑。

為什么這些機器人難以派上用場?
嗯。。。可能得先需要一個可以靈活抓取的機械臂。

此處先放一個彩蛋
抓取是機械臂的基本功,要想成功完成抓取任務,需要闖過三個關卡:抓取物體時定位要精準,抓取姿態要合適,對物體間遮擋可能造成的碰撞要先知先覺,闖過了這三關,機器人才算是入了門。
這篇字節跳動AI Lab和中科院自動化所合作發表在IROS 2021的論文就提出了一個全新的機器人抓取操作方法。

https://arxiv.org/pdf/2108.02425.pdf
作者通過結合3D物體分割、碰撞預測和物體姿態估計,讓機器人能在雜亂場景中準確地估計出物體級別、無碰撞的六自由度抓取姿態,并且達到了SOTA。
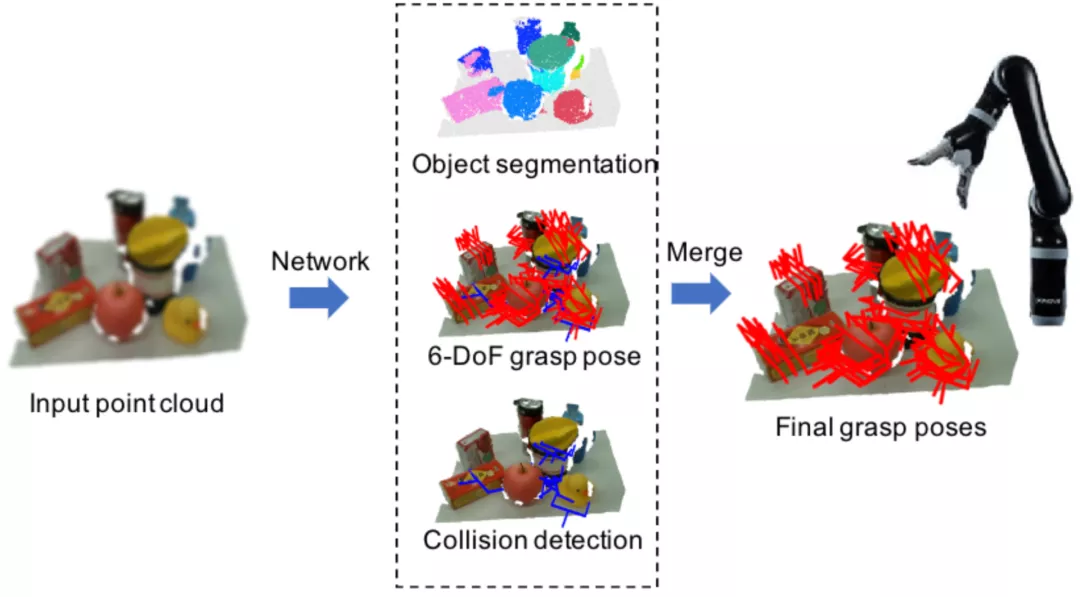
聯合實例分割及碰撞檢測的機器人抓取姿態估計示意圖
首先采用PointNet++作為編碼器從點云中捕捉3D特征信息,后接三個并行解碼器:實例分割解碼器,六自由度抓取姿態解碼器和碰撞檢測解碼器。
這三個解碼器分支分別輸出逐點的實例分割、抓取配置和碰撞預測。在推理階段,作用于同一個實例,且不會發生碰撞的抓取姿勢會被歸為一組,通過位姿非極大值抑制算法融合形成最后的抓取姿勢。
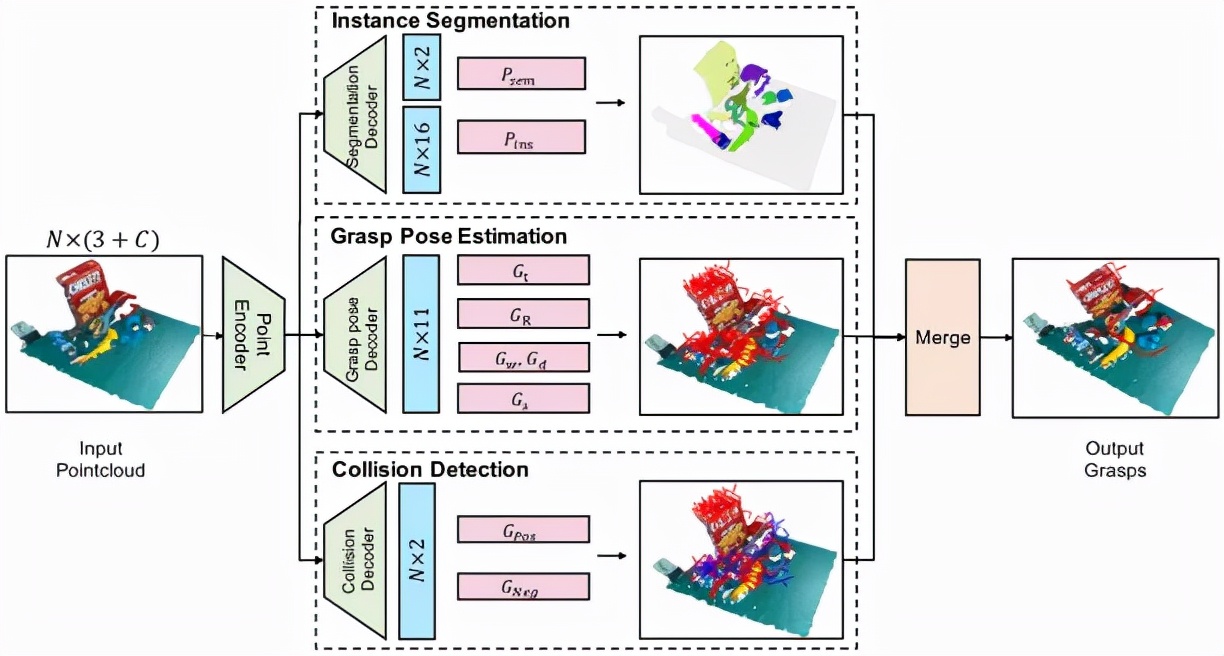
聯合實例分割及碰撞檢測的機器人抓取姿態估計算法框圖
實例分割分支
想抓取一個物體,得先能看清它,看得清楚,才能抓得準確。實例分割分支采用一個逐點實例語義分割模塊來區分多個對象。具體來說,屬于同一實例的點應該具有相似的特征,而不同實例的特征應該不同。
在訓練過程中,每個點的語義和實例標簽都是已知的,用二分類交叉熵來計算該分支輸出的語義損失
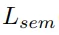
,可以對背景和前景進行分類。
而實例損失
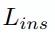
通過一個判別損失函數
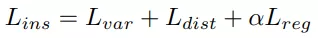
來計算:方差損失
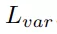
可以讓屬于同一個實例的點盡量向實例中心點靠近,而距離損失
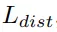
是為了增加不同實例中心之間的距離,正則化損失
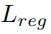
約束所有實例朝向原點,以保持激活有界。
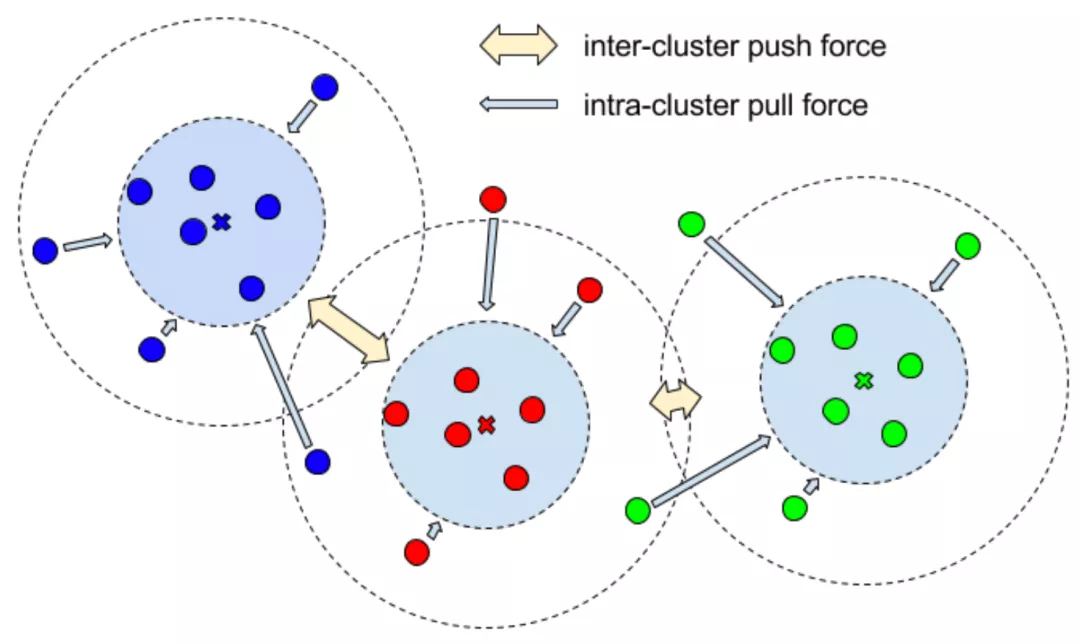
用于實例分割的判別損失函數圖解
整體實例分割的總損失
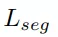
為語義損失和實例損失之和。
這樣,實例分割分支就可以為算法學習實例級的抓握提供實例信息,因而模型可以自主完成抓取,更可以由你指定抓取目標,聽你差遣,指哪抓哪。
六自由度抓取姿態估計分支
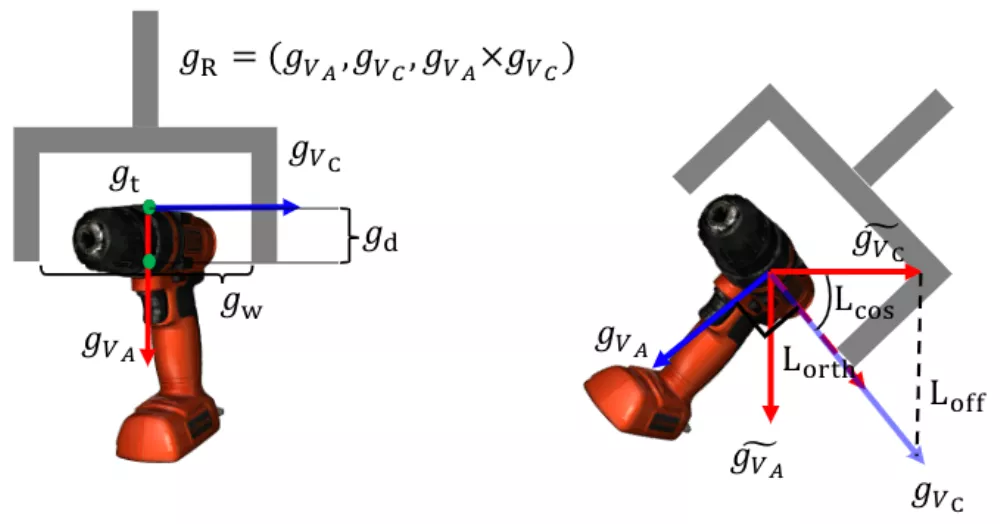
六自由度抓取姿態估計分支在得到了實例的點云后,會為點云中的每個點生成SE(3)抓取配置參數,SE(3)抓取配置g由抓取中心點gt、旋轉矩陣gR、抓取寬度gw、抓取深度gd和抓取質量評估分數gs構成且每個點僅對應一個最優的抓取配置參數組合。
在訓練時,將場景點云中可抓取點的預測視為一個二分類任務,使用交叉熵損失函數監督排除不可抓點,僅保留可抓點。每個可抓點的損失包含了旋轉損失
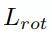
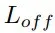
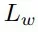
、抓持深度損失
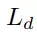
和抓持質量得分損失
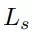
,以此進行監督訓練。
可是,從非線性和不連續的旋轉表示(如四元數或旋轉矩陣)中直接學習六自由度抓取姿態是非常困難的,為了解決這個問題,gR用兩個正交的單位向量將傳統旋轉矩陣分解為手爪的接近物體的方向
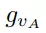
和手爪閉合的方向
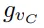
。
為了優化,將旋轉損失
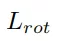
分為三個部分:偏移損失
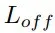
、余弦損失
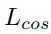
和關聯損失
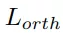
,分別用于約束位置、角度預測和正交性。抓持寬度損失
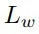
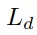
和抓持質量得分損失
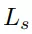
用均方誤差(MSE)損失進行優化。
六自由度抓取姿態估計分支無需事先假定物體的幾何信息,能夠直接從3D點云的特征中進行抓取姿態的預測,并對損失函數做了更精巧的設計,對于復雜場景中各種形狀和大小的物體都能「探囊取物」。
碰撞檢測分支
雖然前兩個分支能夠實現實例級六自由度抓取姿態預測,但仍然需要一個碰撞檢測分支來推斷每個抓取的潛在碰撞以保證生成的抓取姿態在場景中是有效的和可執行的。
碰撞檢測分支采用了一個可學習的碰撞檢測網絡來直接預測所生成的抓取姿態可能產生的碰撞。
在訓練過程中,將對無碰撞和有碰撞視為二分類問題并進行采樣,真實的碰撞結果標簽由已有的碰撞檢測算法根據六自由度抓取姿態估計分支的抓取配置生成,碰撞損失函數
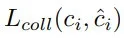
使用二分類交叉熵損失進行監督。
并行的碰撞檢測分支使得該方法的六自由度抓取姿態估計分支不依賴碰撞檢測作為后處理模塊來過濾無效的抓取姿態,大幅降低「思考」延遲,機械臂的抓取動作看上去就是兩個字,絲滑!

在公開數據集Graspnet-1Billion上的小試牛刀,一不小心就拿了個SOTA:
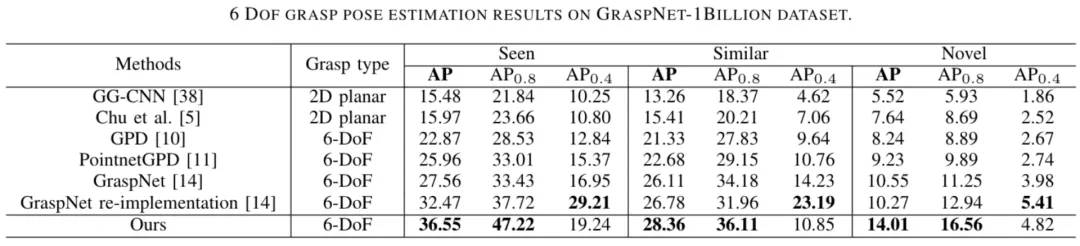
GraspNet-1Billion數據集實驗結果
刷刷榜不過癮,使用Kinova Jaco2機器人和商用RGB-D相機Realsense實戰演練,再拿SOTA,成功率和完成率較之前表現最好的GraspNet都有不小的提升:
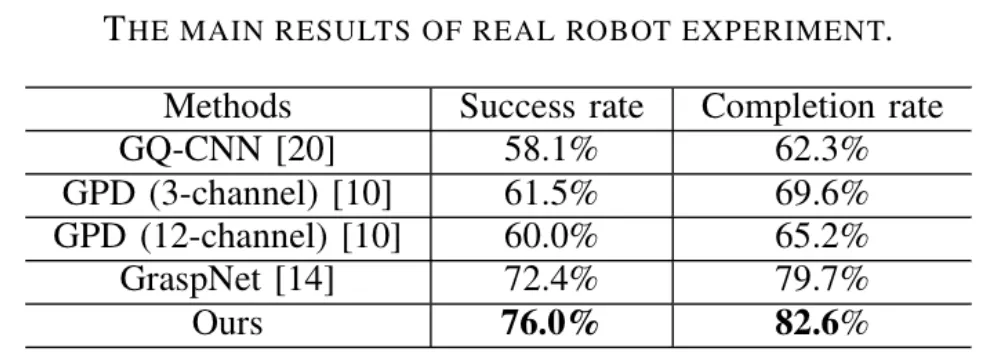
真實機器人平臺實驗結果
入門先學抓,要想拜師學藝,還得練練放。
合理地抓和放,可以完成更復雜的任務,比如自主裝配,搭建等任務。
同樣是IROS 2021收錄的一篇字節跳動和清華大學合作的論文,讓機器人可以在沒有人類指導的圖紙的情況下,也能進行結構設計與建造。
而以往機器人在裝配、布置、堆積木時,得先告訴它任務的最終目標狀態,相當于按「圖」施工,沒「圖」可干不了。

https://arxiv.org/pdf/2108.02439.pdf
搭個橋嘛,這有啥難的?
如果不依賴人類設計出的藍圖,機器人要面對的是一個任意寬的懸崖,一堆雜亂擺放的積木塊。
搭個什么樣的橋啊?自己考慮。用幾塊積木啊?越少越好。這橋不會塌吧?那誰知道呢。
一問三不知,這可比給了精確目標狀態的標準裝配任務難多了,因為機器人既要考慮積木的操作順序,還必須找出即物理上穩定的橋的架構,規劃的搜索空間之大,讓人頭皮發麻。

工程師們腦洞大開,提出了一個雙層框架來解決橋梁的設計和施工任務,在概念上,類似于任務與動作規劃(Task and Motion Planning,TAMP) :機器人先學習一個高層藍圖策略來一次又一次生成將一個構建塊移動到所需位置的組裝指令,再實施一個低層操縱策略來執行高層指令。
這其中的創新之處在于:高級藍圖策略是以物理感知的方式,使用深度強化學習在一個魔改的物理模擬器中學習神經藍圖策略。
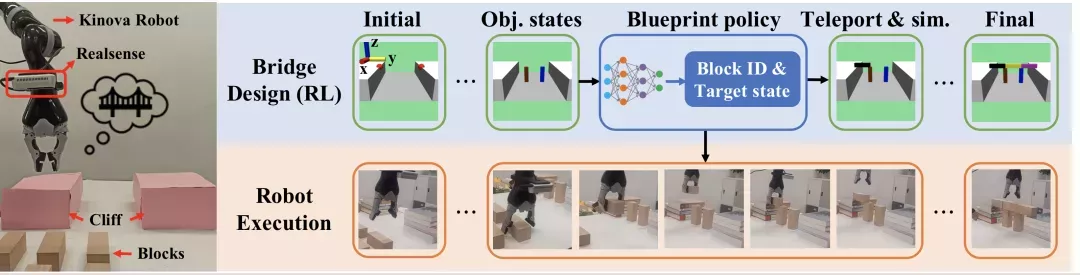
高層藍圖策略
高層藍圖策略要學習的,就是按順序生成取放指令,用最少的積木搭建一座連接兩個懸崖的平橋,還不能倒。
每次,agent都可以觀察一下當前場景,然后指示拿一個積木去搭橋。讓物理引擎飛一會兒,agent就可以接收來自環境的反饋(橋垮沒垮),繼續觀察連續的場景并給出下一個指令。
咦?這個不就是傳說中的馬爾可夫決策過程(MDP)問題嗎?不用懷疑,你又學會了。
用元組{S,A,Γ,R,T}定義這個問題,S表示狀態空間,A表示動作空間,Γ是轉移函數,R代表獎勵函數,T是一回合的視野。
狀態空間編碼所有N個構建塊和2個懸崖的狀態:
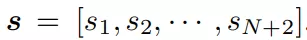
,
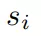
是包含三維位置、歐拉角、笛卡爾速度、角速度、表示物體是否為積木的一維物體類型指示器和一維時間組成的向量。
動作空間簡單一點,只生成拾取放置指令,將構建塊放在橫跨兩個懸崖中間的yz二維平面上,編碼了一維目標對象標識、一維目標y位置、一維目標z位置和圍繞x軸的一維旋轉角度。
轉移函數的構建非常復雜,想是想不出來的,咋辦呢?
記得剛剛說過的物理模擬器嗎?模擬器在接受藍圖策略的指令后直接將選中的積木塊傳送到指令位置,繼續物理模擬,直到環境達到穩定狀態后,將結果狀態返回給藍圖agent。
因此,即使不依賴符號規則或任何已知的動力學模型,agent仍然可以獲知某個指令在很長一段時間內會造成的的物理結果,并學會尋求物理穩定的解決方案。
沒有明教,卻有暗示,只能說是「妙啊」!
獎勵函數是「施工獎勵」、「平整度獎勵」和「節省材料獎勵」的組合,說白了就是,用料要少,橋面要平,還不能倒。
為了解決上述的馬爾可夫決策過程問題,工程師們再次祭出三把「利器」:Transformer, 階段性策略梯度算法(Phasic Policy Gradient,PPG)和自適應課程學習。
具體來說,提取積木塊和懸崖的特征時,基于Transformer的特征提取器
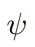
將對象和相互間關系的歸納偏差整合,傳送給策略網絡和價值網絡,并使用PPG算法來有效地訓練策略。
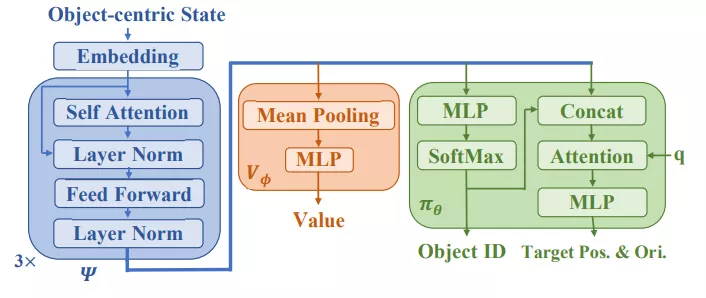
說到階段性策略梯度算法(Phasic Policy Gradient,PPG),不同于近端策略優化算法(Proximal Policy Optimization,PPO),在訓練時,它會階段性地將價值信息提取到策略中,以便更好地進行表征學習,相當于使用一個模仿學習目標來穩定策略網絡的訓練。
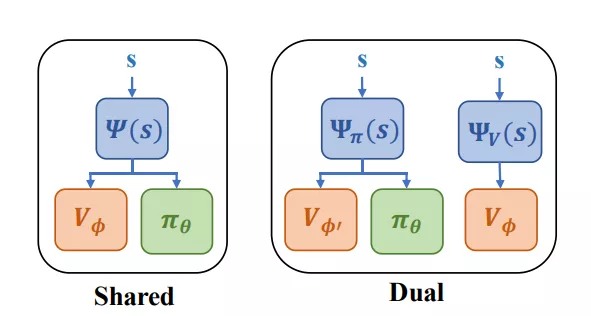
PPG有兩種架構變體,Dual和Shared。Shared架構中,策略和價值網絡共享同一個特征提取器
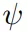
,后接策略頭
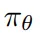
和價值頭
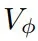
根據大量實踐,發現Shared表現更好。
算法再強,一上來就設計長橋,也太難為人了。
自適應課程學習提供了一種循序漸進的升級打怪思路,根據agent的訓練進度調整谷寬。當機器人在狹窄的谷間搭橋的成功率漸漸提升時,模擬器才會漸漸增加遠距離懸崖出現的概率。
低層運動執行策略
指揮的有了,執行就不難了。
產生裝配指令的藍圖策略訓練好后,低層運動執行策略就可以照著這些指令來操縱積木塊到目標狀態。而藍圖策略在訓練期間受到過物理規律的熏陶,所以它能夠為低級控制器產生物理上可行的指令。
因此,低級策略每次只需要完成一個簡單的取放任務,用經典的運動規劃算法就能解決:通過生成塊的質心抓取姿態,并使用雙向RRT算法規劃無碰撞路徑。
正是由于在本方法中,指令生成和運動執行是完全解耦的,所以學習到的藍圖策略可以以Zero-Shot的方式直接應用于任何真實的機器人平臺。
真實機器人實驗
模擬器里學習到的藍圖策略+現成的運動規劃方法放在真實的機器人系統身上表現如何呢?

現實世界中橋梁設計和施工的結果
拿三種情況測一測,其中懸崖之間的距離分別設置為10厘米、22厘米和32厘米,機器人可以成功地遵循所學習的藍圖策略給出的指令,使用不同的塊數以不同的方式建造橋梁。
「老司機」領進門,修行在個「機器人」
學會了抓和放,機器人終于入了師門。
拜師學藝,學的可不是簡單本領,光能擺弄兩下胳膊顯然是不夠的,任務復雜了「腦子」轉不過彎也不行。
這個看著很簡單,照著「師傅」的操作照貓畫虎地模仿幾遍就會了。
但是機器人看了卻只能直呼:「模仿難,難于上青天」。
比如把衣架掛起來這么一個操作,就需要讓機器人去完成4個子任務,其中每一個子任務都是相互依賴的:
- 接近衣架
- 抓取衣架
- 移動衣架到掛桿附近
- 將衣架掛在桿子上
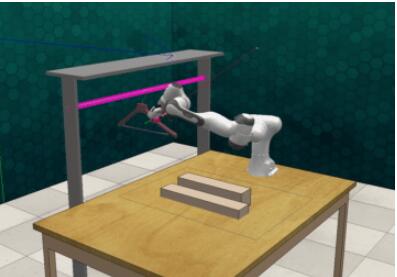
師傅領進門,修行在個人,機器人需要能理解整個任務過程是需要按階段進行劃分的,而且還需要「意識到」在一個階段沒有完成的情況下,是不能進行下一個階段的。
把任務進行拆解之后,每個子任務的復雜度也得到了簡化,同時也可以通過對已有的子任務進行重新組合實現新的更復雜的任務需求。
長序列操作任務
目前,主流的方法是利用分層模仿學習(HIL),包括行為克隆(BC)和逆向強化學習(IRL)。然而不幸的是,BC在專家示例有限的情況下,很容易出現累計誤差。IRL則將強化學習和環境探索引入了模仿過程中,通過不斷探索環境試錯,最終得到對環境變化不敏感的行為策略。
雖然IRL可以避免這類錯誤,但是考慮到高層和低層策略的時間耦合問題,在option模型上實現絕非易事。
不過,問題不大,字節跳動在收錄于ICML 2021的論文中提出了一個新的分層IRL框架「Option-GAIL」。
簡單來說,Option-GAIL可以通過分析、利用專家給定的行為示教信息,學習其背后的行為邏輯,使機器人在相似環境和任務下能完整重現與專家一致的行為結果。

https://arxiv.org/pdf/2106.05530.pdf
方法實現
Option-GAIL算法基于對抗生成模仿學習(GAIL),其行為的整體相似度由對抗生成網絡來近似得到,并且采用option模型代替MDP進行分層建模。
論文采用了單步(one-step)option 模型,也就是每一步都要決定下一步應該做什么子任務,然后再根據當前所處的子任務和觀測到的狀態決定采取什么動作。
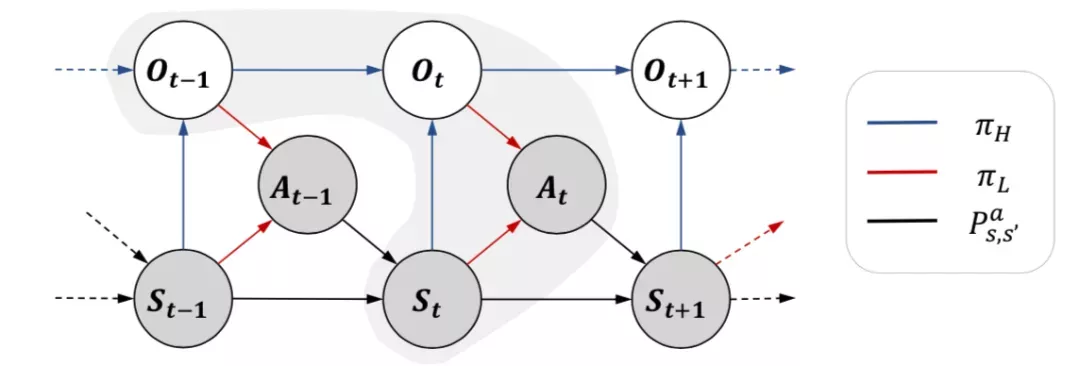
藍色箭頭所指是的決策過程,紅色箭頭是決策,黑色箭頭是環境的狀態轉移
現在有了能把長周期任務表示成多個子任務分階段執行的option模型,下一步就要解決如何訓練這個模型,使得學到的策略能復刻演示數據。
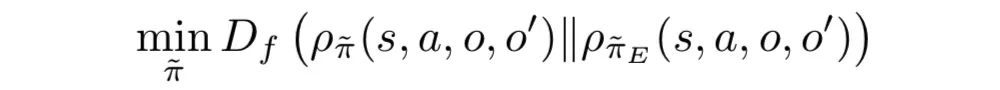
雖然和 GAIL 所解決的占用率度量(occupancy measurement)匹配問題很像,但是模型里多出來的 option 在演示數據里是觀測不到的。
因此,論文提出了一種類似EM算法來訓練Option-GAIL的參數,從而實現端到端的訓練。
E(Expectation)步驟利用Viterbi算法推斷出專家數據的option。
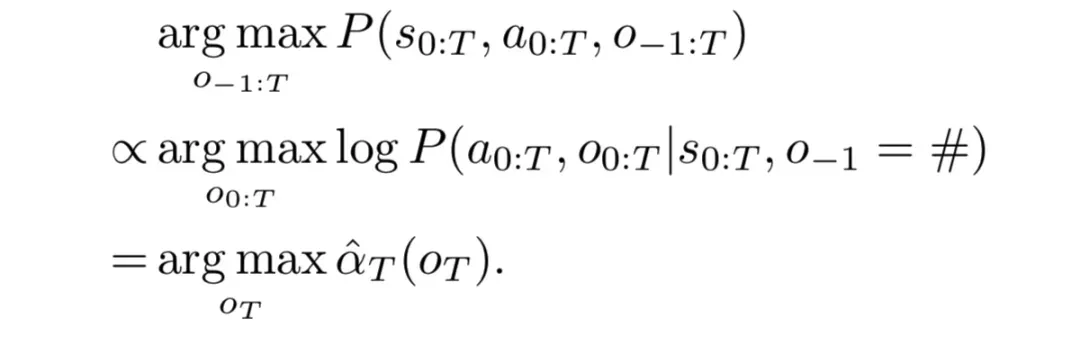
M(Maximization)步驟通過最小-最大博弈來交替優化內層和外層算子,從而得到給定專家option時最優的策略。
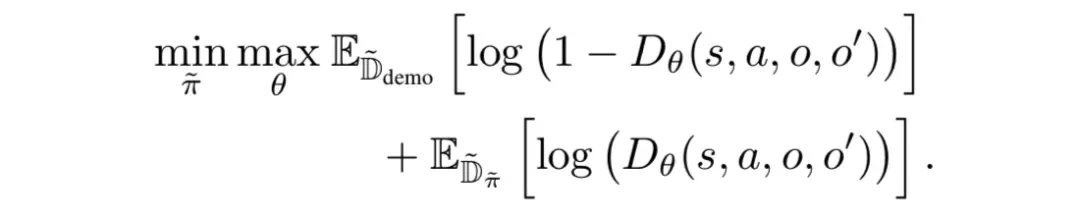
實驗結果
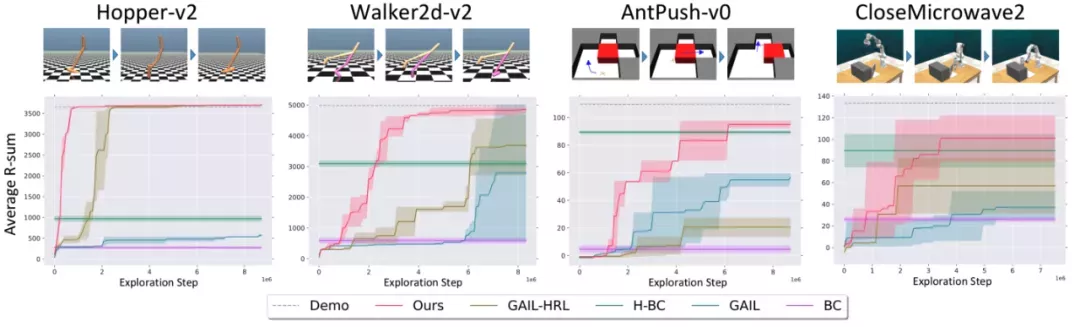
在常用的機器人移動和操作環境上測試我們的算法。測試任務包括:
- 控制單足、雙足機器人運動,機器人需要在邁腿、彈跳等不同行為模式之間切換才能穩健行走;
- 控制螞蟻機器人先推開迷宮里的障礙物才能走到終點;
- 控制機械臂關微波爐門,機械臂要靠近微波爐,抓住爐門把手,最后繞門軸旋轉到關閉。
為了驗證 Option-GAIL 中引入的層次化結構以及在演示數據以外和環境的交互是否能幫助智能體更好地學習長周期任務,選擇如下四種基線方法和Option-GAIL進行對比:
- BC(純動作克隆):只在演示數據上做監督學習,不和環境交互,也沒有任何層次化的結構信息;
- GAIL:有在演示數據之外自己和環境交互,但沒有利用長周期任務的結構信息;
- H-BC(層次化動作克隆):建模了層次化結構,但自己不和環境交互;
- GAIL-HRL:在占用率測度匹配的過程中不考慮option。
結果表明,Option-GAIL相比非層次化的方法收斂速度更快,相比不和環境交互的純模仿學習算法最終的表現更貼近演示數據。
測試環境及各種算法的性能曲線
不如,一起來鼓搗機器人!
當然,除了讓機器人學會抓取操作之外,字節跳動還研發了2D/3D環境語義感知、人機交互等系列技術,之前也對外開源了SOLO等系列機器人感知模型和代碼,在GitHub上頗受歡迎。
不過,技術研究到產業化落地還有很長的路要走,這就需要長期的投入和探索。希望大廠們繼續努力,讓機器人早日真正走進我們的生活。