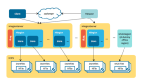
神奇:內存池化和分布式AI集群優化
分布式機器學習產生的原因很簡單, 一方面是可供訓練的數據越來越多,另一方面是模型自身的規模越來越大,所以必須要多個機器來搞。RoCE一類的通信協議自然被用到了,這其實也是nVidia要買Mellanox的根本原因,而并行的方法主要有如下兩種:
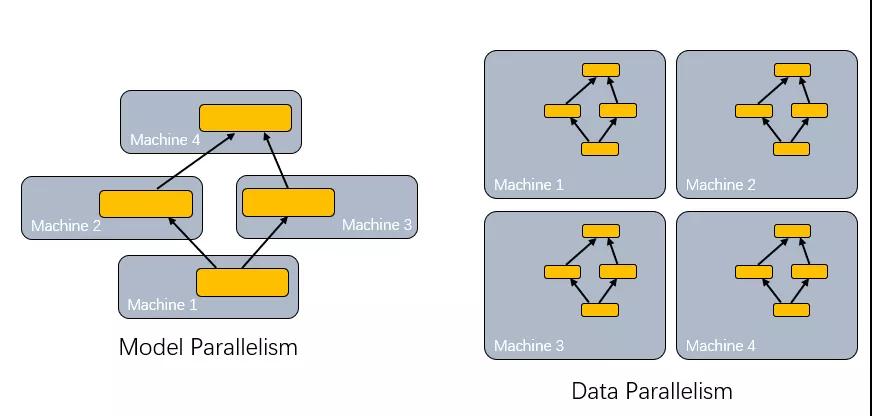
數據并行很容易解釋,主要是如何存儲訓練樣本,并且在多機器之間傳遞混淆樣本,基本上大家大同小異的都在采用SSD、分布式存儲解決這些問題,當然還有內存池化的需求.
另一個問題便是模型并行,當單個工作節點無法存儲時,就需要對模型本身進行分割。當分布式訓練每輪迭代完成都需要將參數進行同步,通常是將每個模型對應的參數加總求和再獲得平均值,這種通信被稱為AllReduce
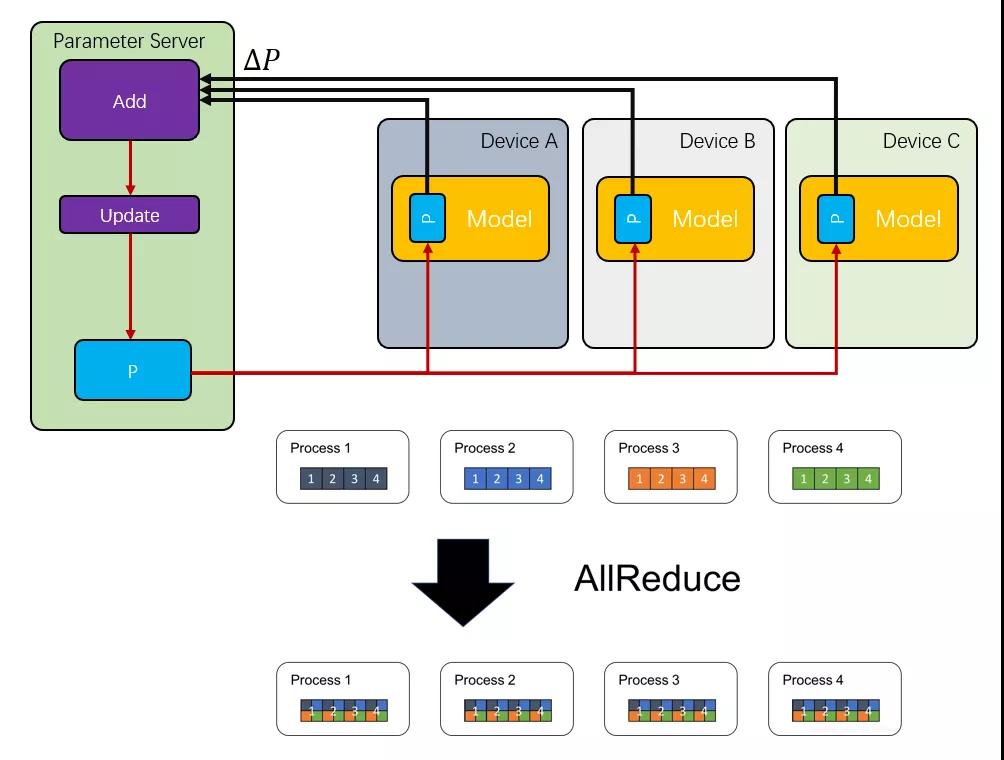
最開始的時候,是采用一個集中式的參數服務器(Parameter Server)構建,但是很快就發現它成了整個集群的瓶頸,然后又有了一些環形拓撲的All-Reduce
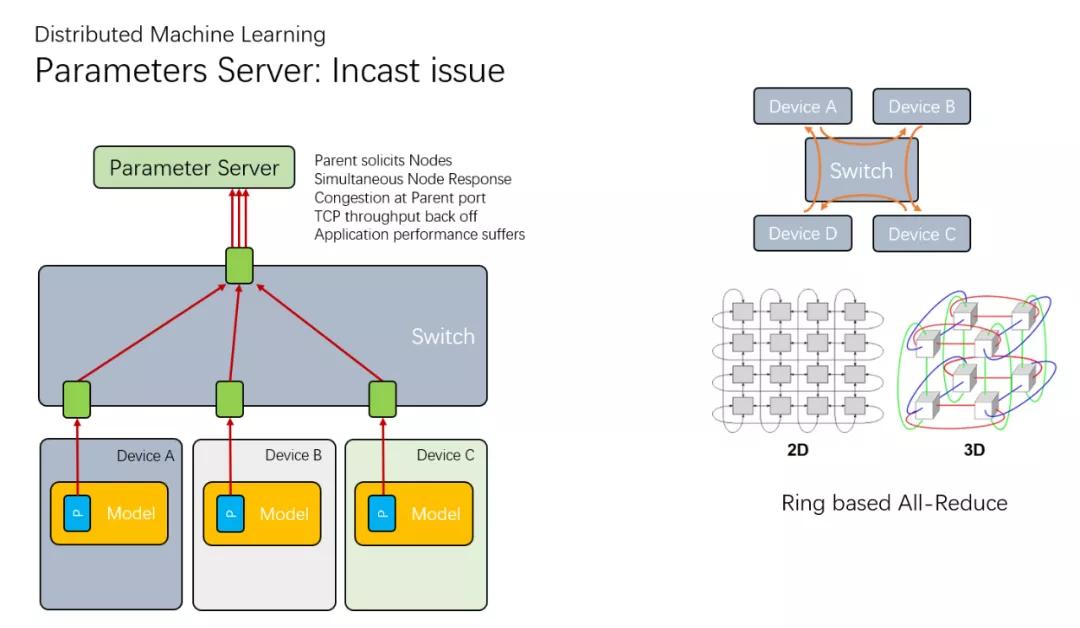
而對于nVidia而言,它們極力的擴大NVLink的帶寬,同時也快速的迭代NCCL,都是為了解決這個AllReduce的問題,但是這些只在單機或者一個極度緊耦合的集群內部。另一方面主機間的通信,自然就選擇了超算中非常常見的RDMA ROCE了。
但是即便如此,AllReduce的延遲還是極大的影響了整個訓練集群的規模:
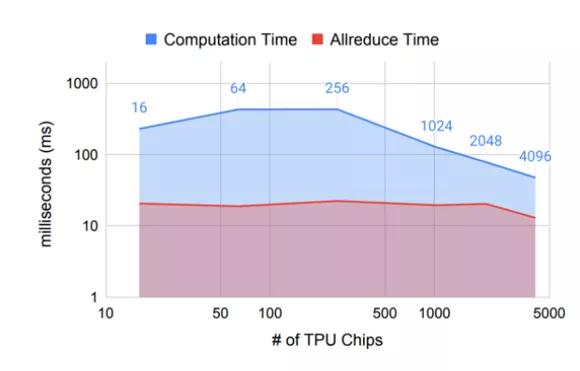
Allreduce算法簡介可以參考鵝廠總結的:
騰訊機智團隊分享--AllReduce算法的前世今生[1]
另一個工作:EFLOPS
阿里在HPCA2020上發布了一篇論文
阿里其實也看清楚了這個問題,PCIe的擁塞,內部調度的擁塞,網卡的擁塞:
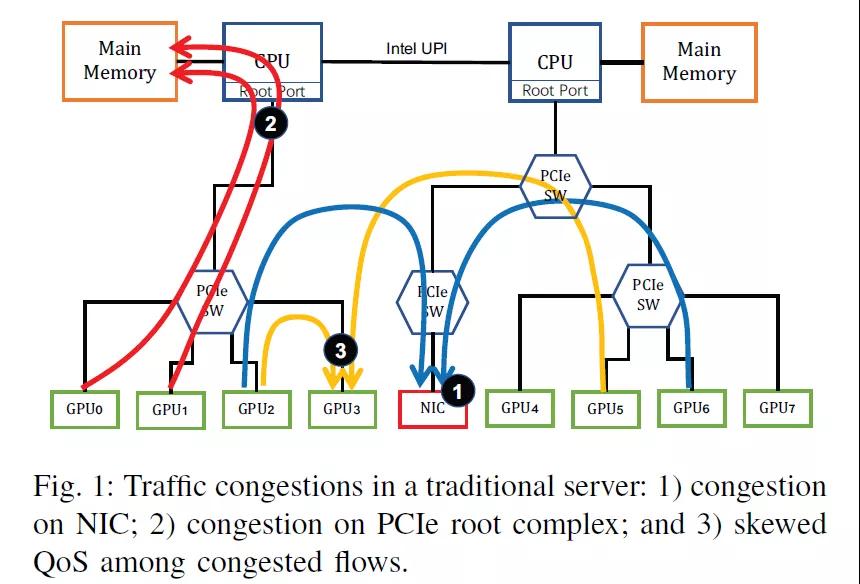
然后解決方案很簡單,反正錢多,一個GPU配一個網卡就好,然后網口多了,交換網也改成兩套Fat-Tree
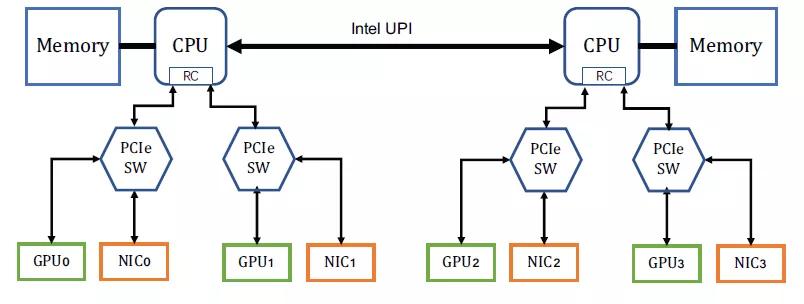
阿里的文章中有一個結論
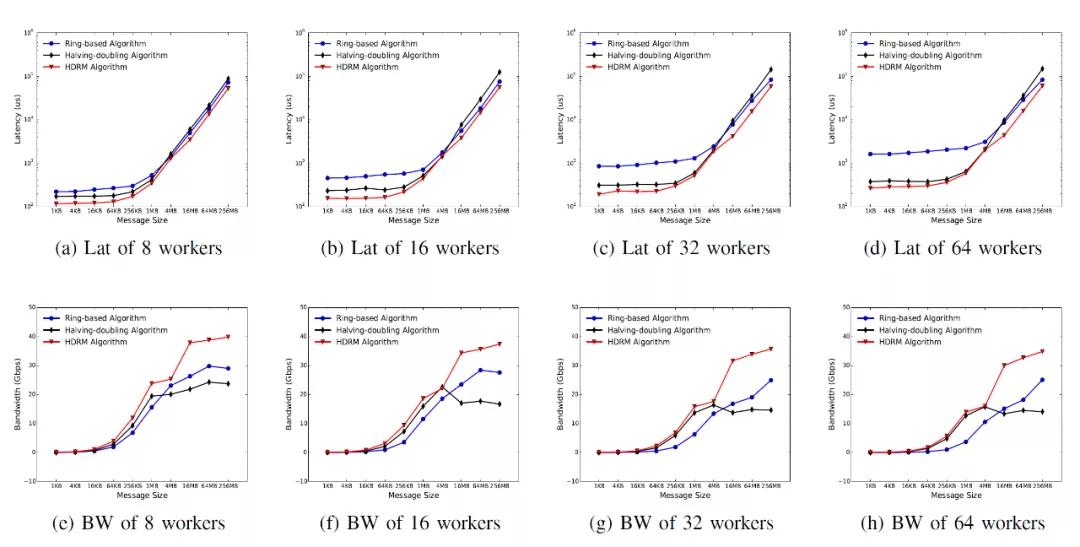
也就是說即便是用了HDRM,也就40Gbps的帶寬了,那我先告訴你們NetDAM的一個結論100Gps輕松跑滿,單個Alveo U55N可以跑滿200Gbps,贈送一句話: In me tiger sniffs the rose.
NetDAM實現AllReduce
首先不談AllReduce的算法和相應的拓撲,在帶寬一定的條件下的約束是通信延遲和計算延遲. 如果采用RoCE,從一臺機器讀和寫都要經過一次PCIe,所以從根源上要解決這個問題就是內存前置,延遲不就下來了么?
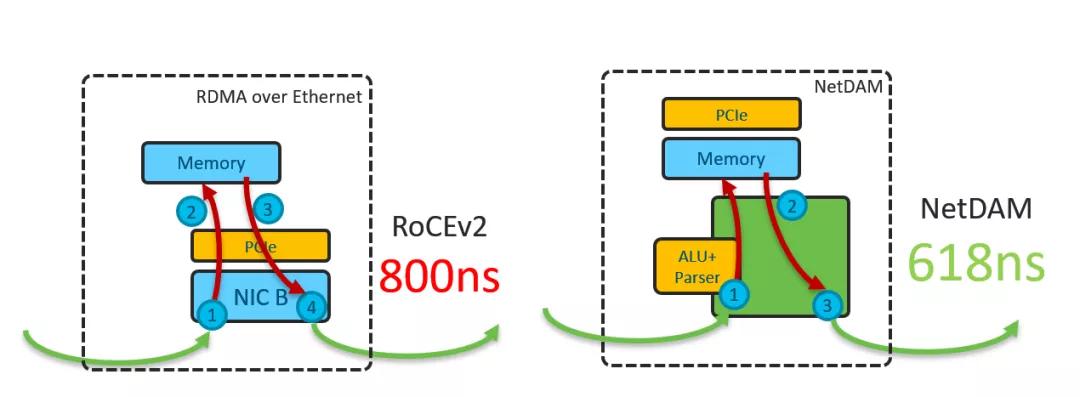
通信延遲降下來了,我們再來看計算延遲,傳統的方式要怎么加:
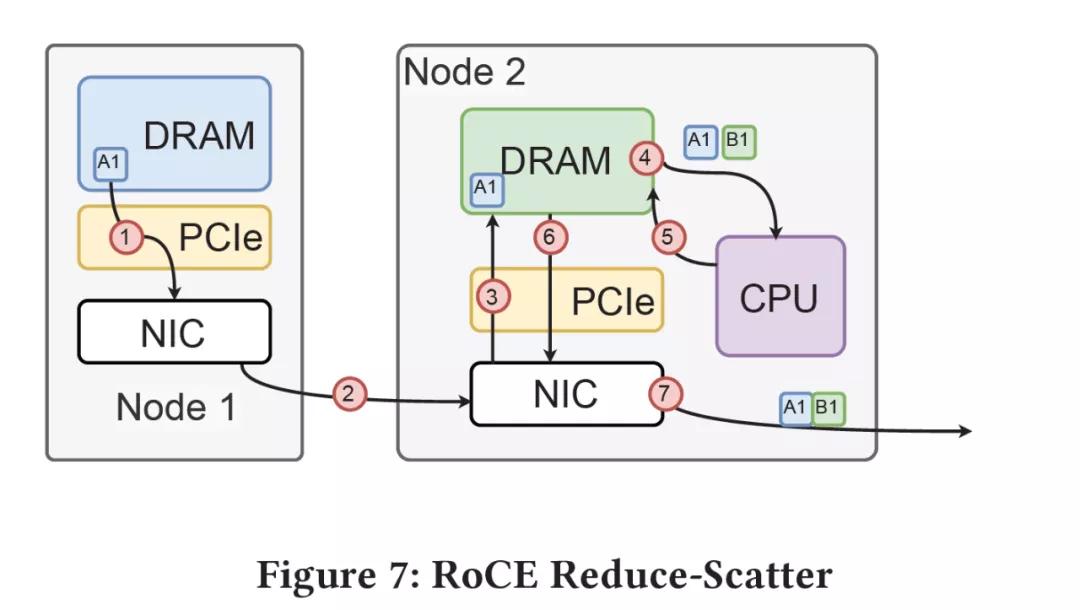
而在計算域內,CPU嘛,AVX512加咯還能怎么樣,帶上Cache延遲抖動都不好控制,丟GPU上還要多一次Memory Copy,即便是直接使用GPU-Direct不也要過一次PCIe么?所以你跑不到線速100Gbps很正常
直接在網卡上放置大量ALU,收到包的時候,包還在SRAM buffer中,這個時候ALU根據包頭的NetDAM Instruction,可以多個ALU同時去load本地DRAM,然后add到相應的SRAM里。加完以后,整個包改個IP頭直接就轉發,這樣一個9000B的報文可以承載2048個float32,等同于AVX(32*2048)的SIMD-Add,所以我當然比你CPU快咯,而且加的時候沒有DRAM的Store,只有最后一跳才會Store,又省了多少?
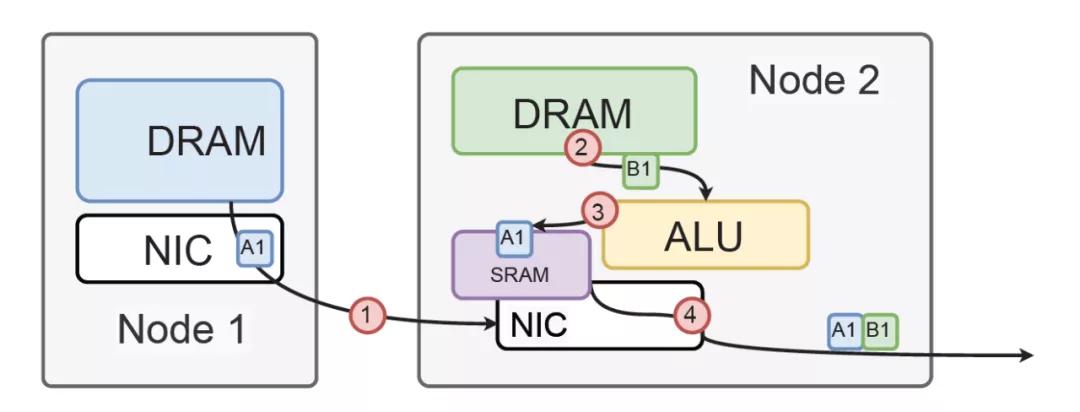
除此之外,針對AI訓練的場景,還有很多可以直接通過NetDAM ALU過濾的方法,例如當一個SIMD內部的2048個float32有一半以上的0時,我可以很簡單的使用
而在AllGather階段,也就是說算好數據需要再次分發的時候,RoCE的組播似乎只是一個概念上的東西,而NetDAM則可以在這個階段充分發揮以太網組播或者廣播的能力,當然具體的丟包重傳,這些都在NetDAM之間就可以完成,FPGA檢測到Seq丟失直接產生一個READ報文給源就行了,壓根不需要CPU參與,具體內容明天講擁塞控制的時候詳細說。
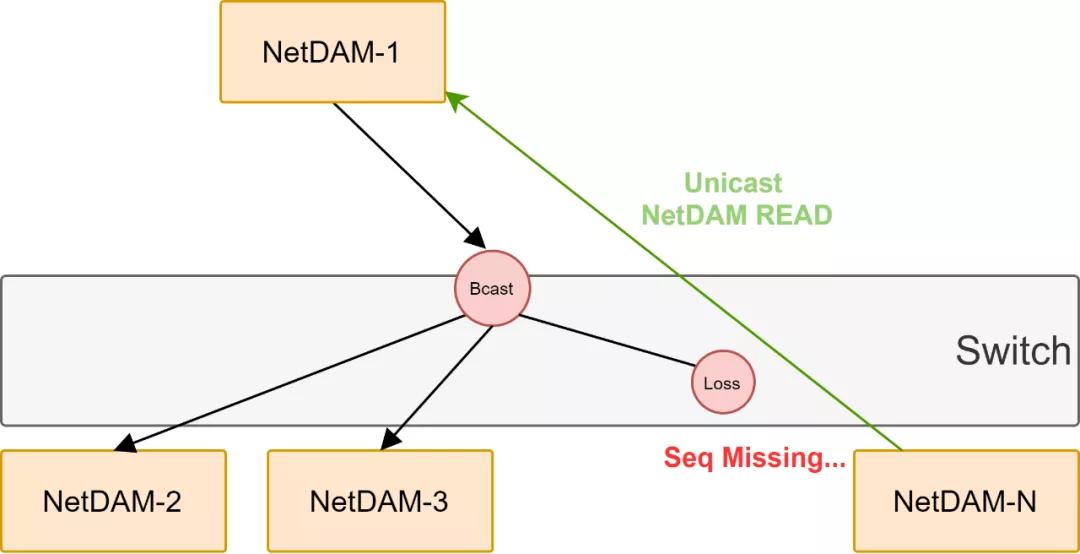
關鍵還不止這一點,它還內帶了一個Segment Routing頭,可以做鏈式反應,就像原子彈那樣~嘣~~~
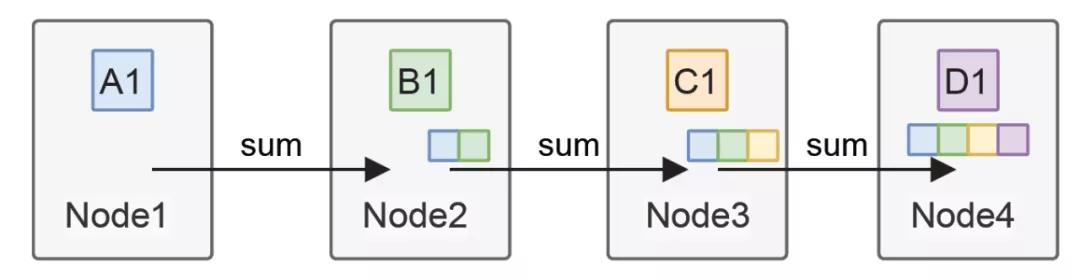
鏈式反應另一個特點就是,打開了通向3D-Torus拓撲的新空間,畢竟連交換機延遲都省了,而且用RingAllreduce跑滿帶寬還不需要考慮incast,漂亮不?香不香?
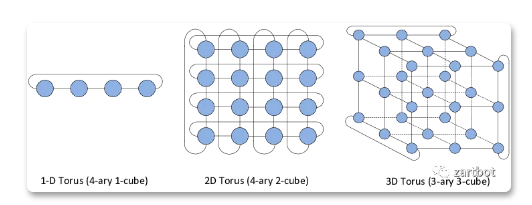
而Google TPU集群為什么要用Torus-Ring,甚至一些超算用6D-Torus,想明白了么?其實就是在擴展性上,Non-Blocking成本很高,而且臨時擴大或者縮小集群規模需要添加額外的設備構成FatTree,Incast也不好控制,而Torus雖然是有阻塞的但是可以通過通信模式來避免阻塞。

即便是用Fat-Tree的數據中心,我們也給你們準備了Ruta的方案來做流量工程,比起那啥搞什么PortRank,更加簡單直觀的是哪兒不堵走哪兒~ 擁塞控制,明天給你們安排~
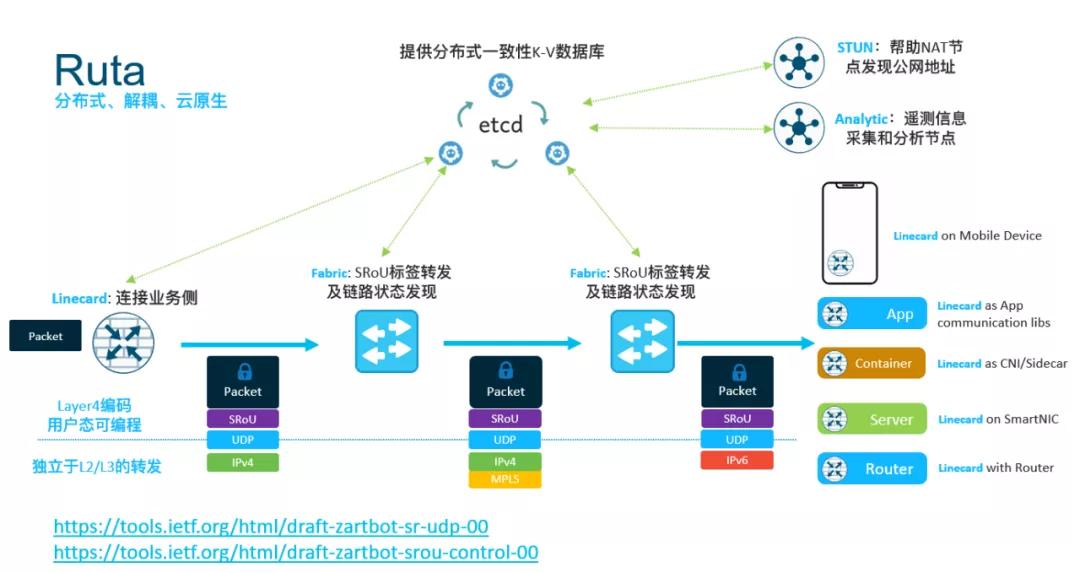
NetDAM實現內存池
NetDAM是一個標準的UDP協議,NetDAM可以獨立于主機單獨部署, 因此可以構成一個非常大規模的內存池:
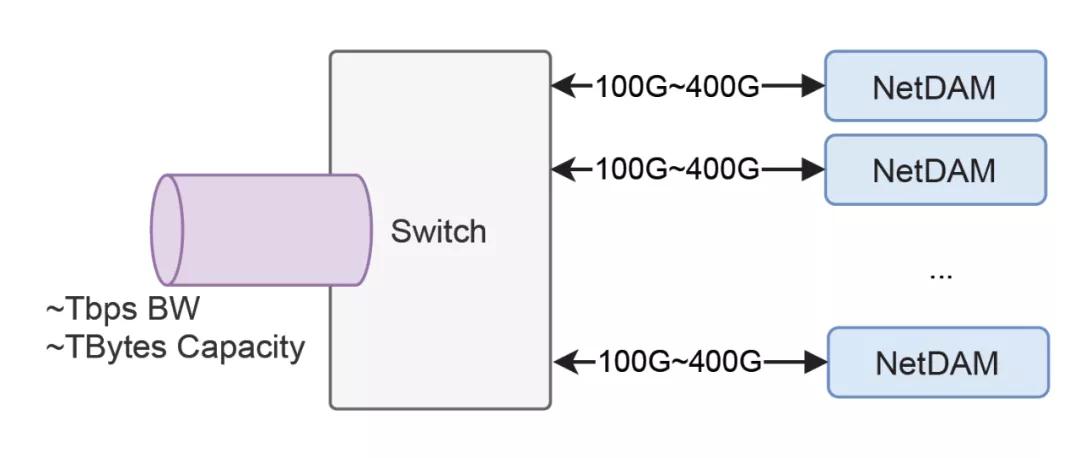
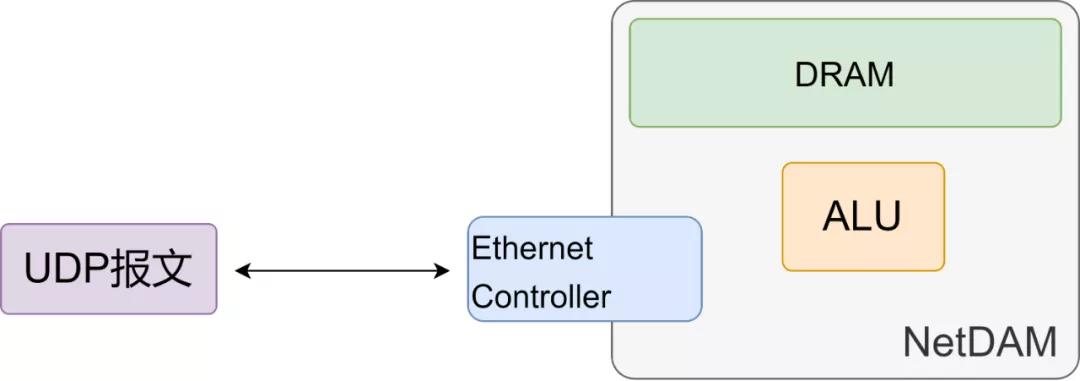
因此普通主機 用戶態不需要任何特殊的開發套件,直接一個UDP Socket就可以控制整個內存集群,爽不爽?
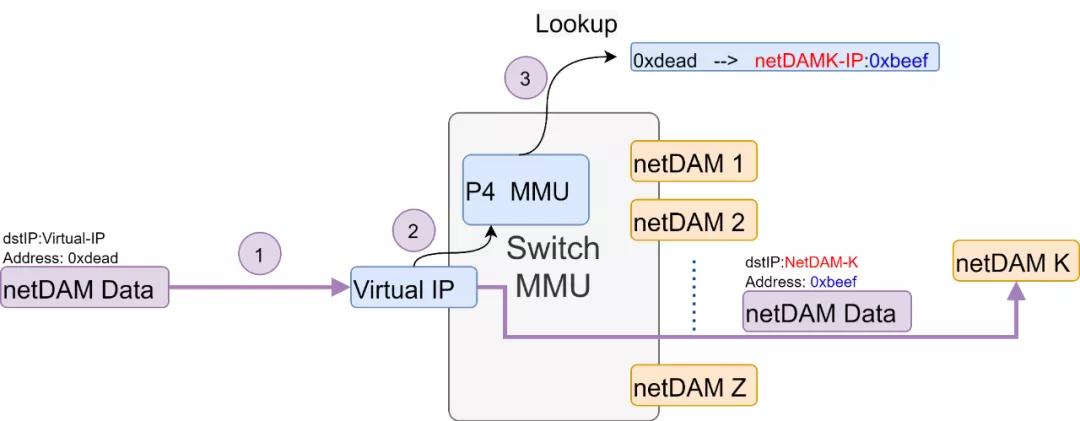
而當你主機自己有了NetDAM卡了以后,可以玩的更High, 分區全局地址空間(partitioned global address space:PGAS)了解一下, 在這種場景下,我們可以把一個交換機芯片改造成MMU,對外提供一個虛擬的IP地址和UDP端口,然后構成一個大的虛擬化池隱藏內部拓撲。而每個netDAM報文訪問的內存地址由交換芯片查表做地址轉換到最終的NetDAM。這種情況下,交換機MMU還可以采用Interleave編址來解決內存局部使用過熱的問題...
繼續從分布式AI訓練集群來看,對內存池的需求主要是一個是訓練數據集的分發和混淆,另一個是參數和梯度的更新。所以這次HotChip中Cerebras提供了一個Memory-X套件:
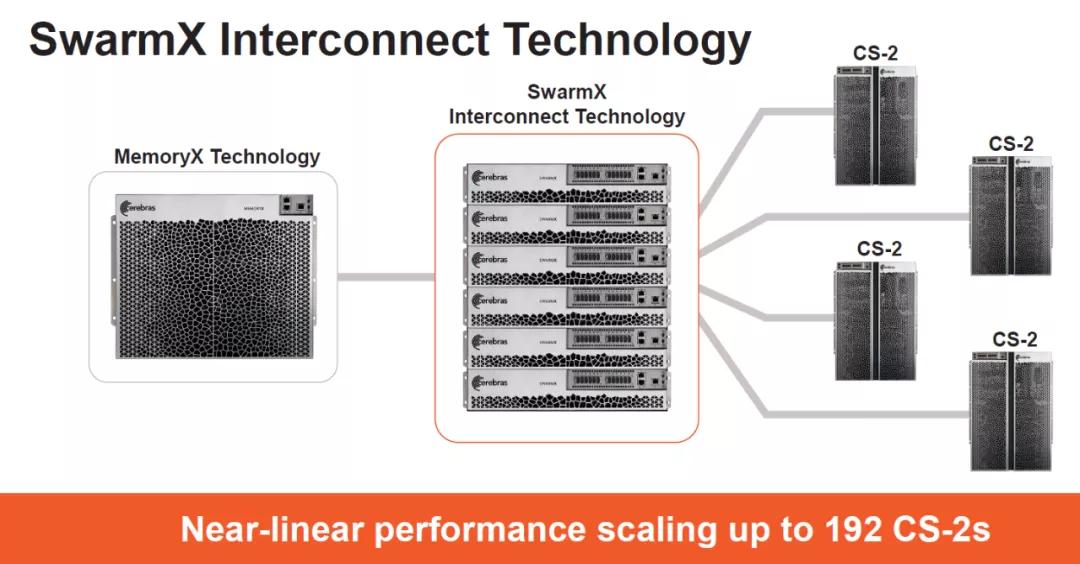
計算任務上,MemoryX還添加了Optimizer
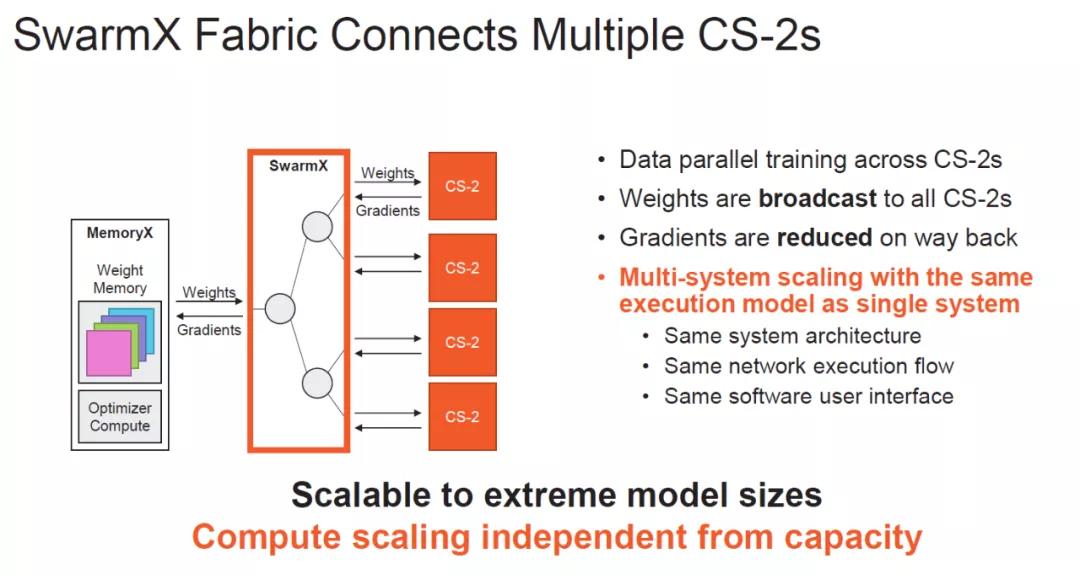
結論 NetDAM也可以同樣的實現這個功能:)
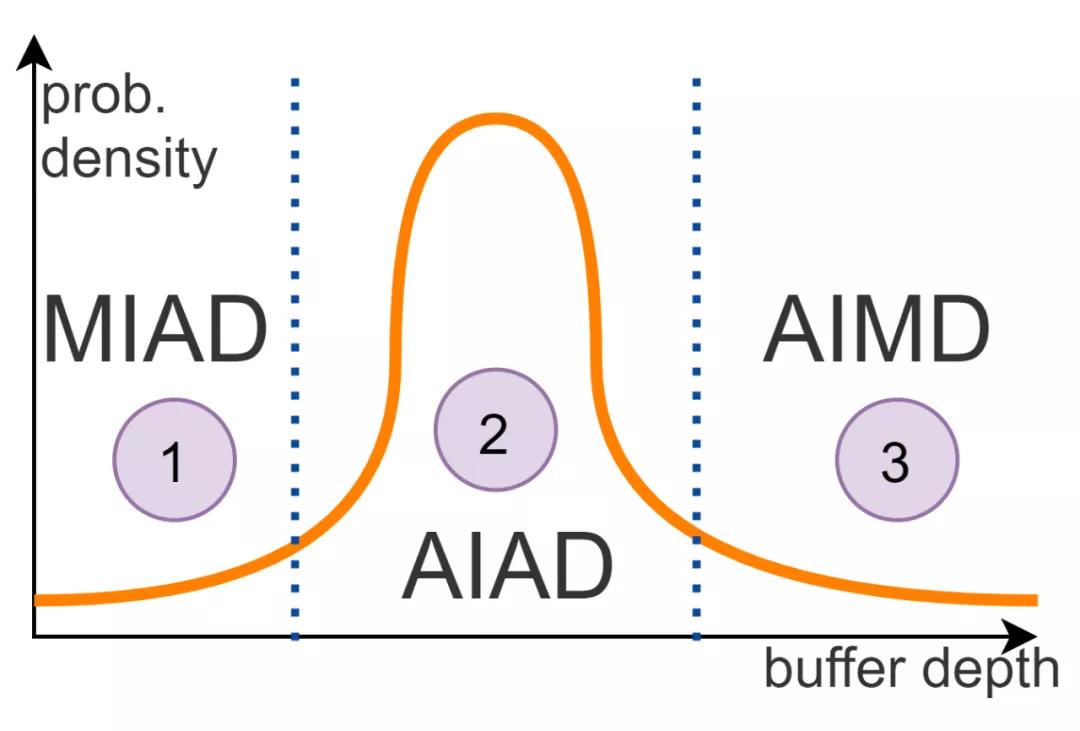
預告....EFLOPS談完了,我們來談談HPCC?當延遲為確定性時,只需要考慮Buffer深度了,那么算法就更簡單了:
Reference
[1]騰訊機智團隊分享--AllReduce算法的前世今生:
https://zhuanlan.zhihu.com/p/79030485