論文地址:https://arxiv.org/abs/2106.02898
該論文指出識別每張圖片所需要的最小分辨率是不同的,而現有方法并沒有充分挖掘輸入分辨率的冗余性,也就是說輸入圖片的分辨率不應該是固定的。論文進一步提出了一種動態分辨率網絡 DRNet,其分辨率根據輸入樣本的內容動態決定。一個計算量可以忽略的分辨率預測器和我們所需要的圖片分類網絡一起優化訓練。在推理過程中,每個輸入分類網絡的圖像將被調整到分辨率預測器所預測的分辨率,以最大限度地減少整體計算負擔。
實驗結果表明,在 ImageNet 圖像識別任務中,DRNet 與標準 ResNet-50 相比,在相似準確率情況下,計算量減少了約 34%;在計算量減少 10% 的情況下,精度提高了 1.4%。
引言
隨著算法、計算能力和大規模數據集的快速發展,深度卷積網絡在各種計算機視覺任務中取得了顯著的成功。然而,出色的性能往往伴隨著巨大的計算成本,這使得 CNN 難以在移動設備上部署。隨著現實場景對于 CNN 的需求不斷增加,降低計算成本的同時維持神經網絡的準確率勢在必行。
近年來,研究人員在模型壓縮和加速方法方面投入了大量精力,包括網絡剪枝、低比特量化、知識蒸餾和高效的模型設計。然而,大多數現有的壓縮網絡中輸入圖像的分辨率仍然是固定的。一般而言,深度網絡使用固定統一的分辨率(例如,ImageNet 上的 224 X 224)進行訓練和推理,盡管每張圖片中目標的大小和位置完全不同。
不可否認,輸入分辨率是影響 CNN 計算成本和性能的一個非常重要的因素。對于同一個網絡,更高的分辨率通常會導致更大的 FLOPs 和更高的準確率。相比之下,輸入分辨率較小的模型性能較低,而所需的 FLOP 也較小。然而,縮小深度網絡的輸入分辨率為我們提供了另一種減輕 CNN 計算負擔的可能性。
為了更清晰地說明,研究者首先使用一個預訓練的 ResNet-50 測試不同分辨率下的圖像,如下圖 1 所示,并計算和展示每個樣本給出正確預測所需要的最小分辨率。對于一些簡單的樣本,如左側圖前景熊貓,可以準確地在低分辨率和高分辨率下被識別出來。然而對于一些難樣本如右側圖的昆蟲,目標被遮擋或者跟別的物體混合,只能通過高分辨率識別。
這一觀察表明,數據集中很大一部分圖片可以降低分辨率來識別。另一方面,這也和人類的感知系統一致,即一些樣本在模糊情況下可以被很好地識別,而另外一些在清晰的條件下才能有效識別。

圖 1:在不同輸入分辨率 (112X112、168X168 和 224X224) 下 ResNet-50 模型的預測結果
在本文中,研究者提出了一種新穎的動態分辨率網絡(DRNet),它動態調整每個樣本的輸入分辨率以進行有效推理。為了準確地找到每張圖像所需的最小分辨率,他們引入了一個嵌入在分類網絡前面的分辨率預測器。
在實踐中,研究者將幾個不同的分辨率設置為候選分辨率,并將圖像輸入分辨率預測器以生成候選分辨率的概率分布。分辨率預測器的網絡架構經過精心設計,計算復雜度可以忽略不計,并與分類器聯合訓練,以端到端的方式進行識別。通過利用所提出的動態分辨率網絡推理方法,研究者可以從每個圖像的輸入分辨率中挖掘其冗余度。這樣做不僅可以節省具有較低分辨率的簡單樣本的計算成本,并且還可以通過保持較高的分辨率來保持難樣本的準確性。
在大規模數據集和 CNN 架構上的大量實驗證明了研究者提出的方法在降低整體計算成本和提升網絡準確率方面的有效性。例如,DR-ResNet-50 僅用 3.7G FLOPs 就達到了 77.5% 的 ImageNet top-1 準確率,這比計算量多 10% 的 ResNet-50 高出了 1.4%。
方法
整體架構
研究者提出了一種實例感知的分辨率選擇方法,為大型分類器網絡選擇輸入圖像的分辨率。這種方法包含了兩個組件,第一個是大型分類器網絡,例如 ResNet,它的特點是準確率高和計算成本高。第二個是分辨率預測器,它的目標是找到一個最小的分辨率,這樣能為預測每張輸入圖片來平衡準確率和效率。
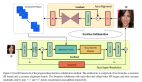
對于任意的輸入圖片,研究者首先用分辨率預測器來預測其合適的分辨率 r。然后,大型分類器網絡將 resized 后的圖像作為輸入。這樣,當 r 小于原始分辨率時,FLOPs 就會大幅度減少。兩種網絡在訓練時是端到端一起訓練的,如下圖 2 所示。
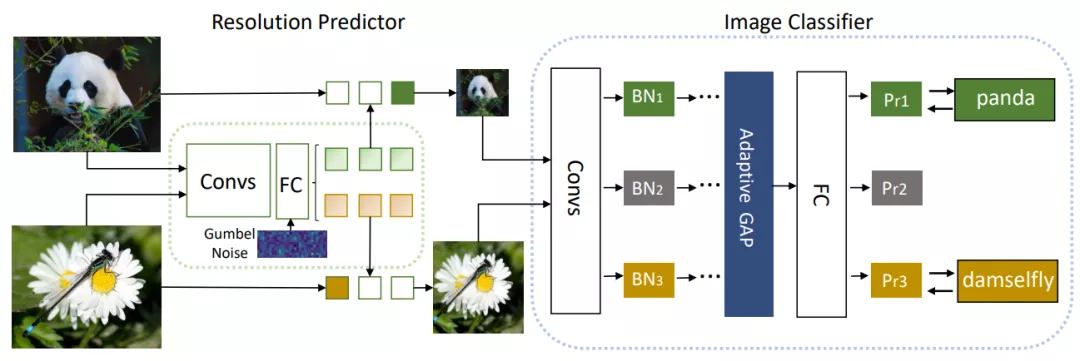
圖 2:模型整體結構圖
分辨率預測器
分辨率預測器的設計是基于 CNN 的。分辨率預測器的目標是通過得到一個概率分布來找到一個合適的分辨率。這里研究者提供 m 個候選分辨率以供分辨率預測器挑選。考慮到分辨率預測器會帶來額外的計算消耗,所以在設計分辨率預測器時只保留了很少的卷積層和全連接層。
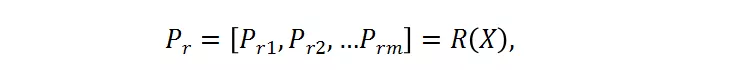
其中,X 是輸入的樣本,被送入分辨率預測器。P_r 是預測器的輸出,其代表了每個候選的概率。候選分辨率中對應的最高概率的那個分辨率將被選為送入大分類器的圖片的分辨率。這里采用了 Gumbel-Softmax 來實現這種選擇過程,將其轉變成是可微分的:
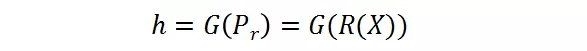
分辨率感知的批正則化(BN)
BN 常用于使得深度模型收斂得更快更穩定。然而不同分辨率下的激活統計值 (activation statistics) 包含了均值和方差,這使得它們不兼容。實驗表明,使用不同的分辨率下的共享的 BN 會導致更低的準確率。考慮到 BN 層只包含了可忽略不計的參數,研究者提出分辨率感知的批正則化,即對于不同的分辨率,使用他們對應的 BN 層。
訓練優化
分類網絡與分辨率預測器同時進行訓練優化。損失函數包含了交叉熵損失函數和研究者提出的 FLOPs 損失函數。FLOPs 損失函數用于限制計算量。
給定一個預訓練好的分類網絡
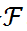
。輸入 X 并輸出概率
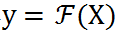
以用于圖像分類。對于輸入 X,研究者首先將其 resize 成 m 個候選分辨率 X_r1, X_r2,... , X_rm,然后使用分辨率預測器對每張圖片產生分辨率概率矢量 P_rR^m。然后軟分辨率概率 P_r 被轉變成硬的獨熱選擇 h ϵ{0,1}^m,使用 Gumbel-Softmax。h 代表了每個樣本的分辨率選擇。在實踐中,他們首先獲得了對于每個分辨率的最終的預測 y_rj=F(X_rj),然后將其通過 h 加起來:
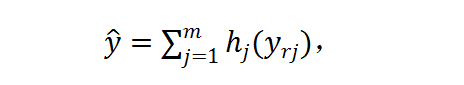
交叉熵損失函數
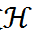
將在預測 ^y 和標簽 y 之間執行:
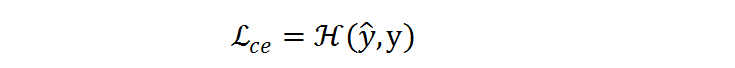
梯度被反向傳播到分類網絡和分辨率預測器以同時優化。
如果只使用交叉熵損失函數,分辨率預測器將會收斂到一個次優點,并傾向于選擇最大的分辨率,因為最大的分辨率往往對應著更低的分類損失。為了減少計算量,研究者提出了一個 FLOPs constraint regularization 去指導分類預測器的學習:
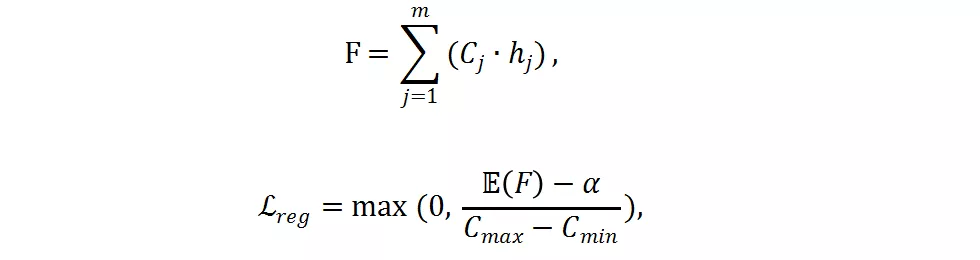
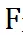
是實際 FLOPs,C_j 是預先計算好的第 j 個分辨率的 FLOPs,
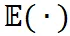
是在樣本層面的期望值,
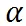
是目標 FLOPs。經過這個正則,如果平均 FLOPs 值過大,將會有一個懲罰,促使提出的分辨率預測器高效且準確。最終,整個損失函數是兩者加權和:
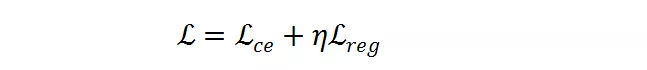
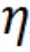
是超參數以用于平衡
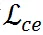
和
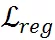
的幅度。
Gumbel Softmax 可以使得離散的 decision 在反向傳播中可微。對于前述概率值 P_r = [p_r1, p_r2, , p_rm],離散的候選分辨率選擇可以由此得到:
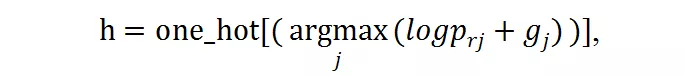
g_j 是 gumbel noise,由下式得到:
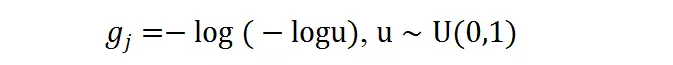
在訓練過程中,獨熱操作的求導可以由 gumbel softmax 近似,其中
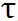
是溫度系數:
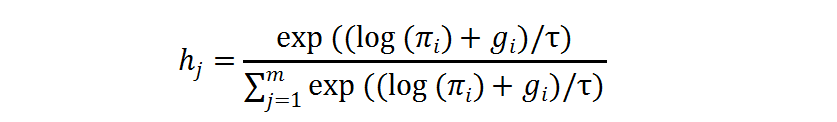
實驗
研究者在 ImageNet-1K 和 ImageNet-100 數據集上訓練和驗證 DRNet 模型,其中 ImageNet-100 是 ImageNet-1K 的子集。
ImageNet-100 實驗
從下表 1 可以看出,在 ImageNet-100 數據集上,DRNet 相比于 ResNet-50,減少了 17% 的 FLOPs,同時獲得了 4.0% 的準確率提升。當調整超參數和時,可以減少 32% 的 FLOPs 并提升 1.8% 準確率。另外,采用分辨率感知的 BN 獲得了性能提升而 FLOPs 相似。
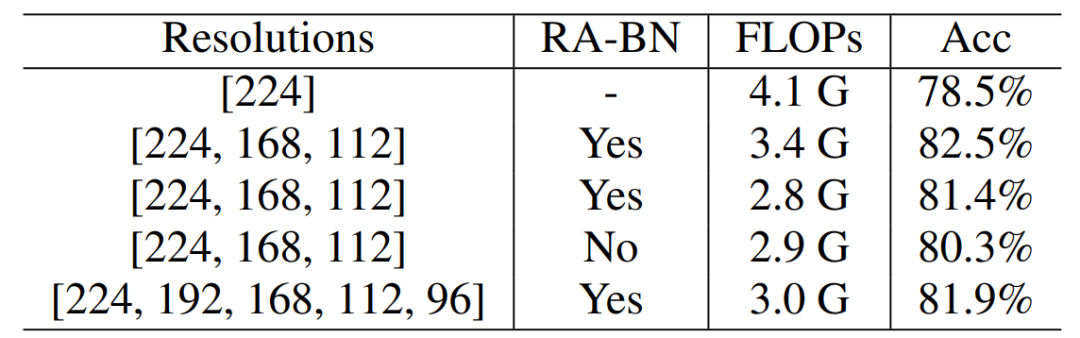
表 1 :ResNet-50 骨干網絡在 ImageNet-100 上的結果
下表 2 中,研究者進一步減少,可以獲得 44% 的 FLOPs 減少而準確率還是增加。
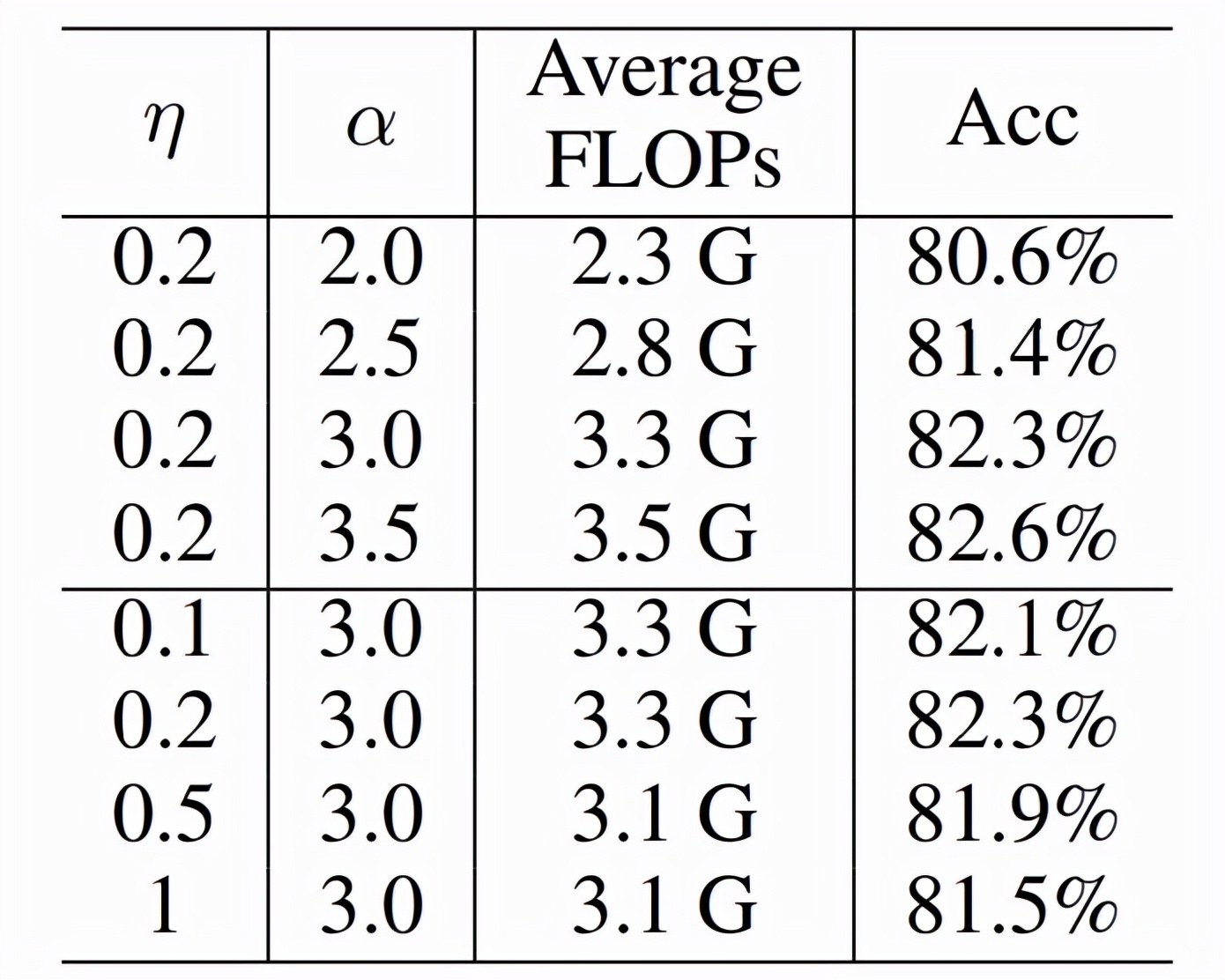
表 2 :FLOPs Loss 的影響
ImageNet-1K 實驗
研究者在 ImageNet-1K 上進行大規模實驗,發現 DR-ResNet-50 減少了 10% 的 FLOPs,性能提升 1.4%,如下表 3 所示。
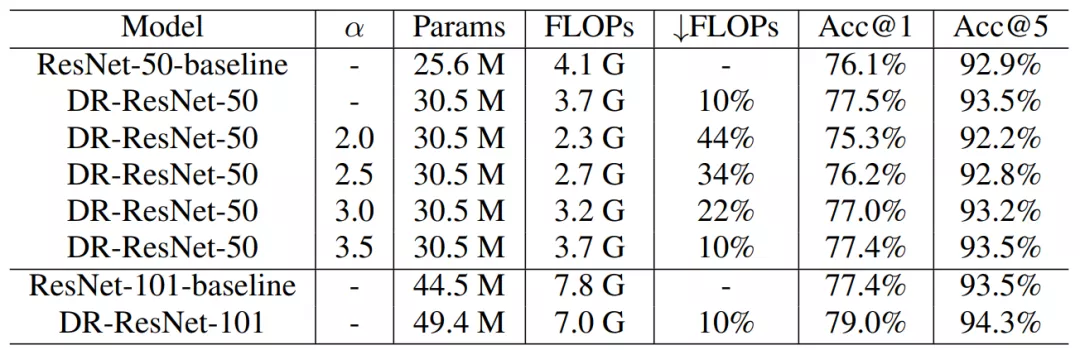
表 3 :ResNet-50 和 ResNet-101 在 ImageNet-1K 上的結果
與其他方法的結果比較見下表 4。
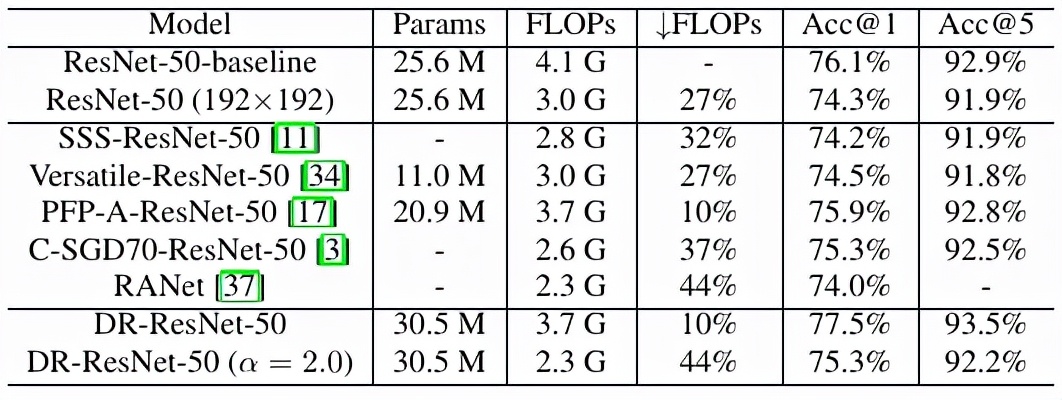
表 4:和其他模型壓縮方法的比較
為了驗證所提出的動態分辨率機制的作用,研究者對比了 DR-ResNet-50 和隨機選擇機制的性能,見下表 5。
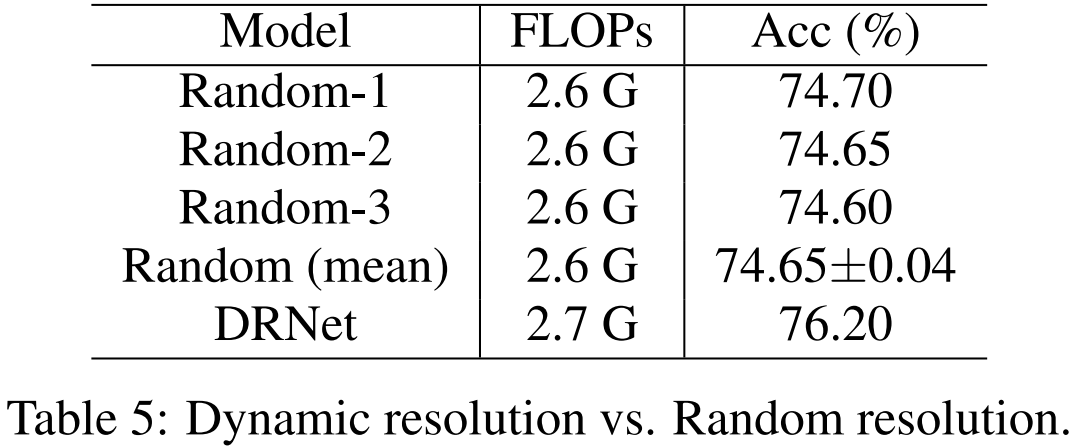
表 5:動態分辨率與隨機分辨率對比
下圖 3 展示了實際情況下測速,表明該方法比 ResNet-50 優越。
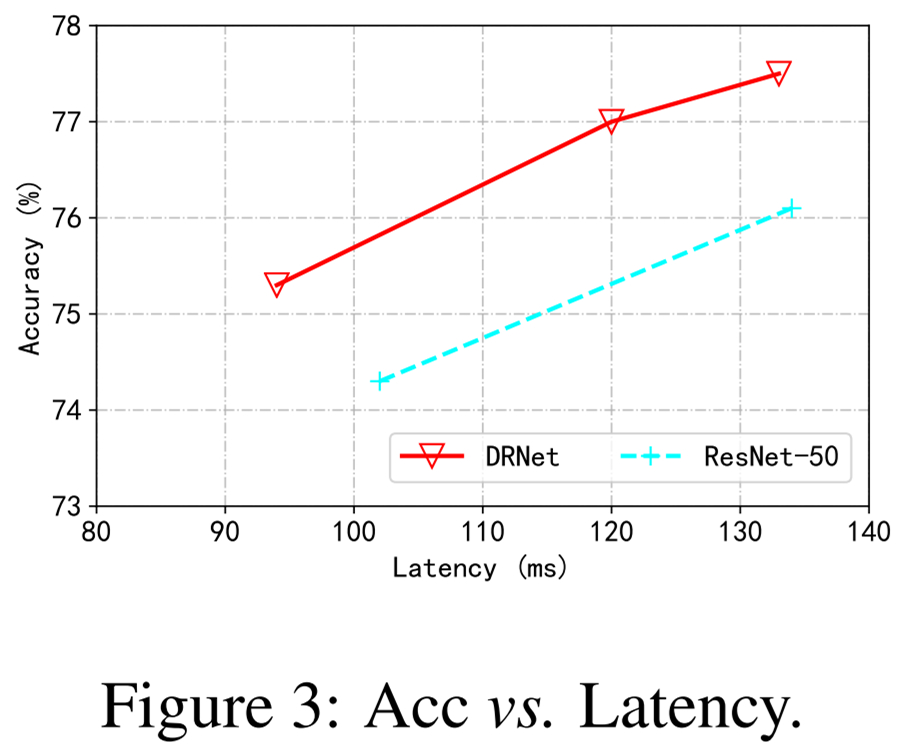
圖 3:準確率和 Latency 對比
下表 6 則將骨干模型從 ResNet 擴展到了 MobileNet,并展示了其有效性。
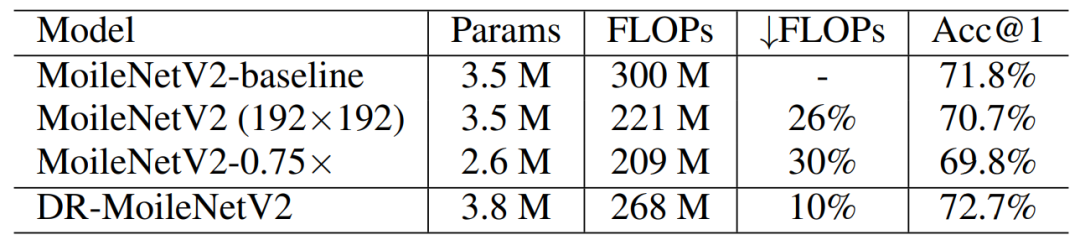
表 6:MoblieNet V2 結果
下圖 4 展示了 DRNet 的預測結果可視化,可以看到,視覺上更難識別的圖像往往被預測為使用更高的分辨率,反之則是更低的分辨率。

圖 4:圖片可視化結果