













速度提升2倍,超強悍CPU級骨干網(wǎng)絡(luò)PP-LCNet出世
算法速度優(yōu)化遇到瓶頸,達不到要求?應(yīng)用環(huán)境沒有高性能硬件只有 CPU?
是不是直接戳中了各位開發(fā)者的痛點!莫慌,今天小編就來為萬千開發(fā)者破局。
這個破局點就是:針對 CPU 設(shè)備及加速庫 MKLDNN 定制的骨干網(wǎng)絡(luò) PP-LCNet!
空口無憑,上圖為證!

從上圖我們可以看出,PP-LCNet 在同樣精度的情況下,速度遠超當(dāng)前所有的骨架網(wǎng)絡(luò),最多可以有 2 倍的性能優(yōu)勢!它應(yīng)用在比如目標(biāo)檢測、語義分割等任務(wù)算法上,也可以使原本的網(wǎng)絡(luò)有大幅度的性能提升。
而這個 PP-LCNet 的論文發(fā)布和代碼開源后,也著實引來了眾多業(yè)界開發(fā)者的關(guān)注,各界大神把 PP-LCNet 應(yīng)用在 YOLO 系列算法上也真實帶來了極其可觀的性能收益。
這時候是不是有小伙伴已經(jīng)按耐不住也想直接上手試試了?!
小編識趣地趕緊送上開源代碼的傳送門。大家一定要 Star 收藏以免走失,也給開源社區(qū)一些認可和鼓勵。
地址:https://github.com/PaddlePaddle/PaddleClas
而這個 PP-LCNet 到底是如何設(shè)計,從而有這么好的性能的呢?下面小編就帶大家來領(lǐng)略一下:
PP-LCNet 核心技術(shù)解讀
近年來,很多輕量級的骨干網(wǎng)絡(luò)問世,各種 NAS 搜索出的網(wǎng)絡(luò)尤其亮眼。但這些算法的優(yōu)化都脫離了產(chǎn)業(yè)最常用的 Intel CPU 設(shè)備環(huán)境,加速能力也往往不合預(yù)期。百度飛槳圖像分類套件 PaddleClas 基于這樣的產(chǎn)業(yè)現(xiàn)狀,針對 Intel CPU 及其加速庫 MKLDNN 定制了獨特的高性能骨干網(wǎng)絡(luò) PP-LCNet。比起其他的輕量級 SOTA 模型,該骨干網(wǎng)絡(luò)可以在不增加推理時間的情況下,進一步提升模型的性能,最終大幅度超越現(xiàn)有的 SOTA 模型。
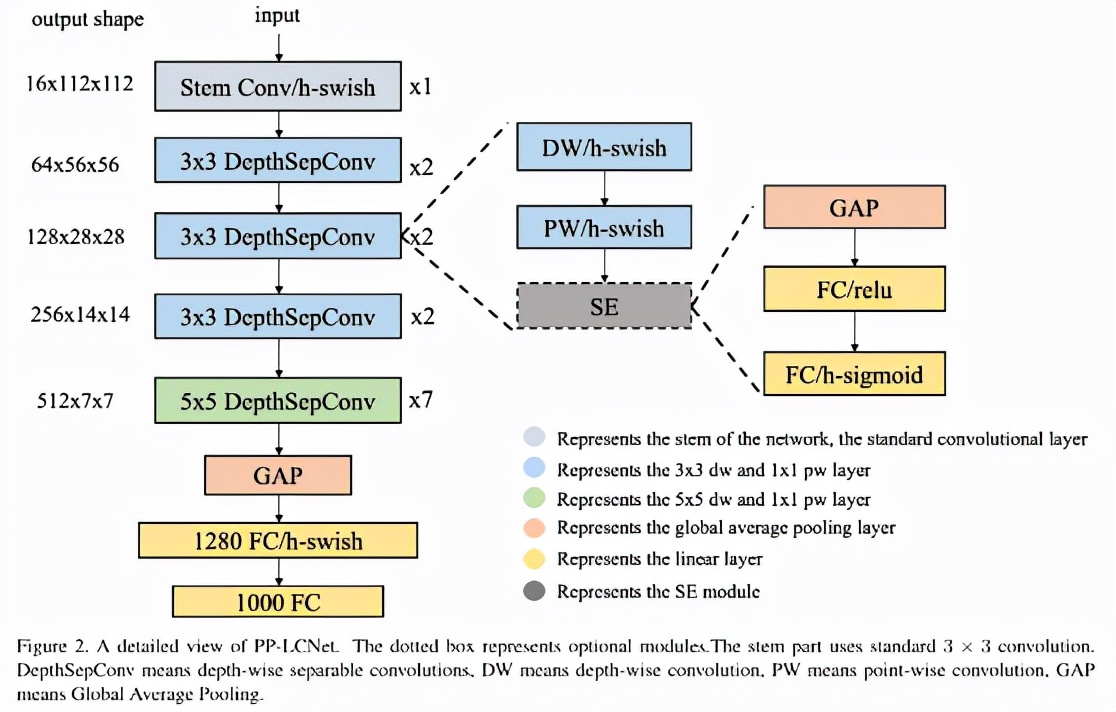
PP-LCNet 的網(wǎng)絡(luò)結(jié)構(gòu)整體如上圖所示。我們經(jīng)過大量的實驗發(fā)現(xiàn),在基于 Intel CPU 的設(shè)備上,尤其當(dāng)啟用 MKLDNN 加速庫后,很多看似不太耗時的操作反而會增加延時,比如 elementwise-add 操作、split-concat 結(jié)構(gòu)等。所以最終我們選用了結(jié)構(gòu)盡可能精簡、速度盡可能快的 block 組成我們的 BaseNet(類似 MobileNetV1)。基于 BaseNet,我們通過實驗,總結(jié)出四條幾乎不增加延時但又能夠提升模型精度的方法,下面將對這四條策略進行詳細介紹:
更好的激活函數(shù)
自從卷積神經(jīng)網(wǎng)絡(luò)使用了 ReLU 激活函數(shù)后,網(wǎng)絡(luò)性能得到了大幅度提升。近些年 ReLU 激活函數(shù)的變體也相繼出現(xiàn),如 Leaky-ReLU、P-ReLU、ELU 等。2017 年,谷歌大腦團隊通過搜索的方式得到了 swish 激活函數(shù),該激活函數(shù)在輕量級網(wǎng)絡(luò)上表現(xiàn)優(yōu)異。在 2019 年,MobileNetV3 的作者將該激活函數(shù)進一步優(yōu)化為 H-Swish,該激活函數(shù)去除了指數(shù)運算,速度更快,網(wǎng)絡(luò)精度幾乎不受影響。我們也經(jīng)過很多實驗發(fā)現(xiàn)該激活函數(shù)在輕量級網(wǎng)絡(luò)上有優(yōu)異的表現(xiàn)。所以在 PP-LCNet 中,我們選用了該激活函數(shù)。
合適的位置添加 SE 模塊
SE 模塊是 SENet 提出的一種通道注意力機制,可以有效提升模型的精度。但是在 Intel CPU 端,該模塊同樣會帶來較大的延時,如何平衡精度和速度是我們要解決的一個問題。雖然在 MobileNetV3 等基于 NAS 搜索的網(wǎng)絡(luò)中對 SE 模塊的位置進行了搜索,但是并沒有得出一般的結(jié)論。我們通過實驗發(fā)現(xiàn),SE 模塊越靠近網(wǎng)絡(luò)的尾部對模型精度的提升越大。下表也展示了我們的一些實驗結(jié)果:
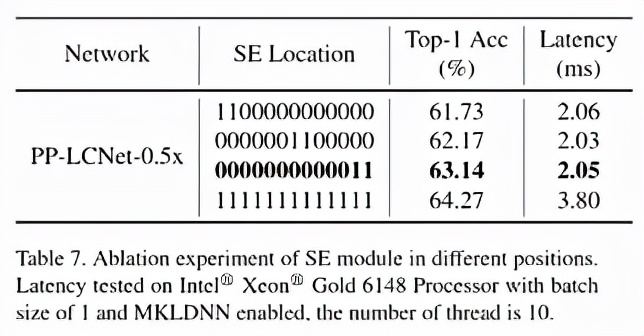
最終,PP-LCNet 中的 SE 模塊的位置選用了表格中第三行的方案。
更大的卷積核
在 MixNet 的論文中,作者分析了卷積核大小對模型性能的影響,結(jié)論是在一定范圍內(nèi)大的卷積核可以提升模型的性能,但是超過這個范圍會有損模型的性能,所以作者組合了一種 split-concat 范式的 MixConv,這種組合雖然可以提升模型的性能,但是不利于推理。我們通過實驗總結(jié)了一些更大的卷積核在不同位置的作用,類似 SE 模塊的位置,更大的卷積核在網(wǎng)絡(luò)的中后部作用更明顯,下表展示了 5x5 卷積核的位置對精度的影響:

實驗表明,更大的卷積核放在網(wǎng)絡(luò)的中后部即可達到放在所有位置的精度,與此同時,獲得更快的推理速度。PP-LCNet 最終選用了表格中第三行的方案。
GAP 后使用更大的 1x1 卷積層
在 GoogLeNet 之后,GAP(Global-Average-Pooling)后往往直接接分類層,但是在輕量級網(wǎng)絡(luò)中,這樣會導(dǎo)致 GAP 后提取的特征沒有得到進一步的融合和加工。如果在此后使用一個更大的 1x1 卷積層(等同于 FC 層),GAP 后的特征便不會直接經(jīng)過分類層,而是先進行了融合,并將融合的特征進行分類。這樣可以在不影響模型推理速度的同時大大提升準(zhǔn)確率。
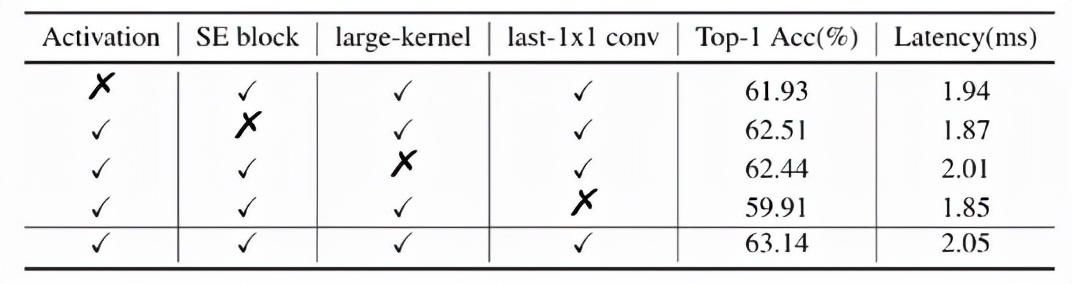
BaseNet 經(jīng)過以上四個方面的改進,得到了 PP-LCNet。下表進一步說明了每個方案對結(jié)果的影響:
下游任務(wù)性能驚艷提升
圖像分類
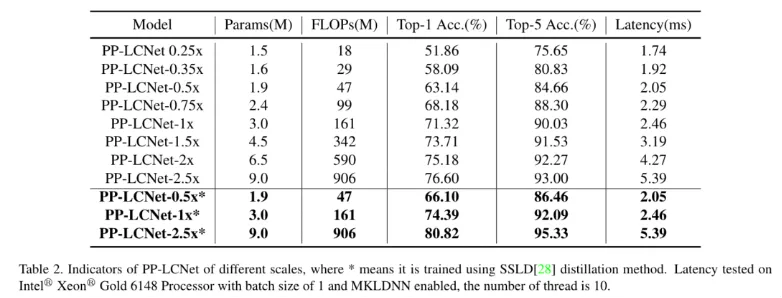
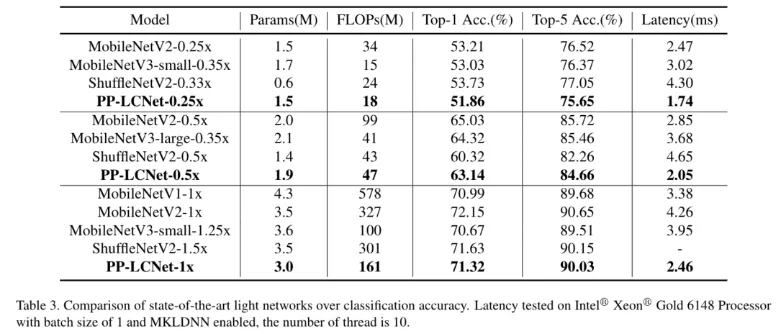
圖像分類我們選用了 ImageNet 數(shù)據(jù)集,相比目前主流的輕量級網(wǎng)絡(luò),PP-LCNet 在相同精度下可以獲得更快的推理速度。當(dāng)使用百度自研的 SSLD 蒸餾策略后,精度進一步提升,在 Intel CPU 端約 5ms 的推理速度下 ImageNet 的 Top-1 Acc 竟然超過了 80%,Amazing!!!
目標(biāo)檢測
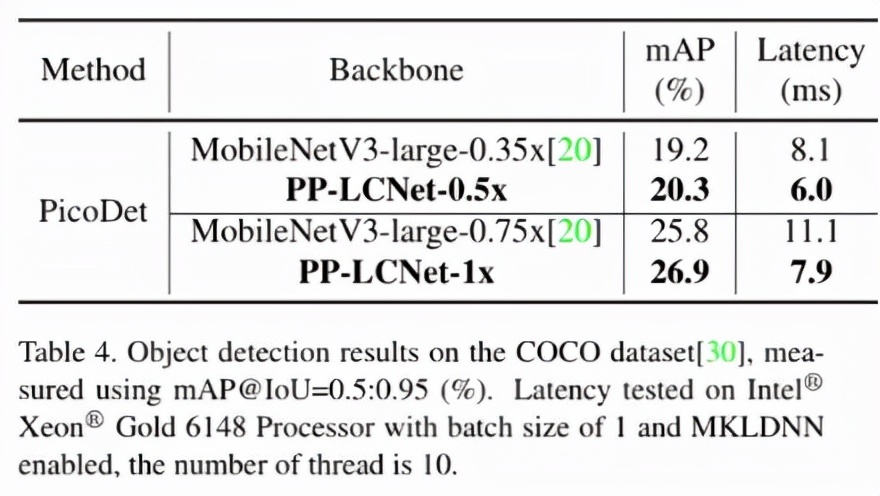
目標(biāo)檢測的方法我們選用了百度自研的 PicoDet,該方法主打輕量級目標(biāo)檢測場景。下表展示了在 COCO 數(shù)據(jù)集上、backbone 選用 PP-LCNet 與 MobileNetV3 的結(jié)果的比較。無論在精度還是速度上,PP-LCNet 的優(yōu)勢都非常明顯。
語義分割
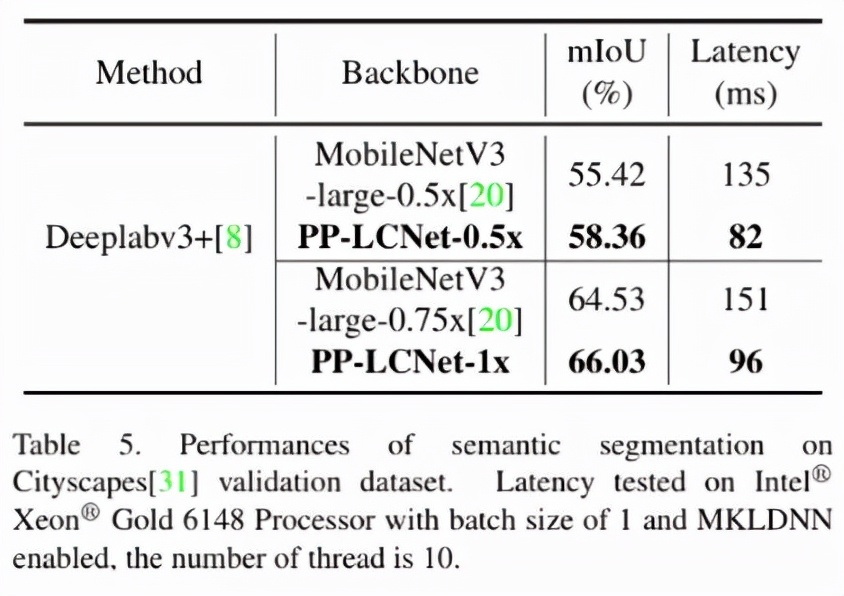
語義分割的方法我們選用了 DeeplabV3+。下表展示了在 Cityscapes 數(shù)據(jù)集上、backbone 選用 PP-LCNet 與 MobileNetV3 的比較。在精度和速度方面,PP-LCNet 的優(yōu)勢同樣明顯。
實際拓展應(yīng)用結(jié)果說明
PP-LCNet 在計算機視覺下游任務(wù)上表現(xiàn)很出色,那在真實的使用場景如何呢?本節(jié)簡述其在 PP-OCR v2、PP-ShiTu 上的表現(xiàn)。
在 PP-OCR v2 上,只將識別模型的 backbone 由 MobileNetV3 替換為 PP-LCNet 后,在速度更快的同時,精度可以進一步提升。

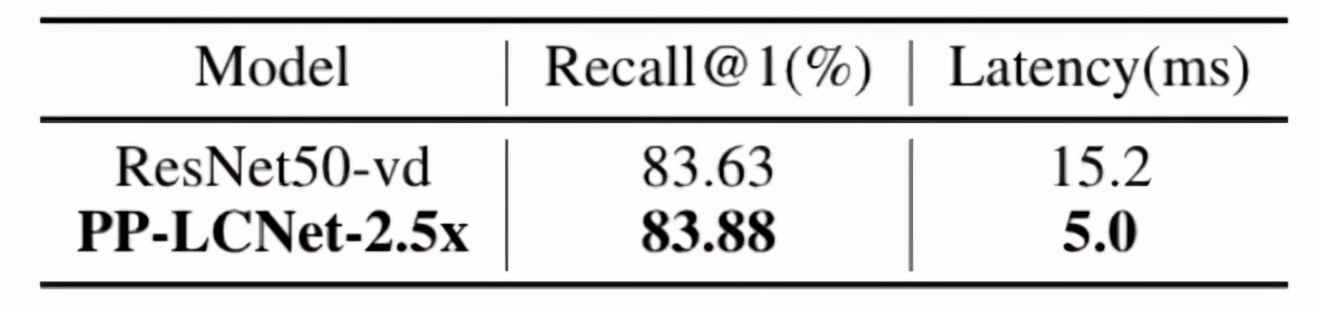
在 PP-ShiTu 中,將 Backbone 的 ResNet50_vd 替換為 PP-LCNet-2.5x 后,在 Intel-CPU 端,速度快 3 倍,recall@1 基本和 ResNet50_vd 持平。
PP-LCNet 并不是追求極致的 FLOPs 與 Params,而是著眼于深入技術(shù)細節(jié),耐心分析如何添加對 Intel CPU 友好的模塊來提升模型的性能來更好地進行準(zhǔn)確率和推理時間的平衡,其中的實驗結(jié)論也很適合其他網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計的研究者,同時也為 NAS 搜索研究者提供了更小的搜索空間和一般結(jié)論。
自論文發(fā)出以來,PP-LCNet 引起了國內(nèi)外學(xué)術(shù)界和產(chǎn)業(yè)界的廣泛關(guān)注,無論是各類版本的復(fù)現(xiàn),還是極具探索意義和實用價值的各類視覺任務(wù)應(yīng)用和技術(shù)分析文章層出不窮,將簡單模型的實用性優(yōu)化方案重新帶入大家的視野,真正踐行技術(shù)讓 “生活” 更美好的初心,期待 PP-LCNet 在實際落地和應(yīng)用中的更多表現(xiàn)。
前面提到的論文,鏈接如下:https://arxiv.org/pdf/2109.15099.pdf
本論文工作的總體研究思路由百度飛槳 PaddleClas 團隊提出并實施。PaddleClas 提供全球首個開源通用圖像識別系統(tǒng),并力求為工業(yè)界和學(xué)術(shù)界提供更高效便捷的開發(fā)工具,為開發(fā)者帶來更流暢優(yōu)質(zhì)的使用體驗,訓(xùn)練出更好的飛槳視覺模型,實現(xiàn)行業(yè)場景實現(xiàn)落地應(yīng)用。
想要獲取更多 PaddleClas 相關(guān)介紹及教程文檔可前往:GitHub: https://github.com/PaddlePaddle/PaddleClas
















