十一張圖講透原理,最細的增量拉取
一、前言
上一篇我們講解了客戶端首次獲取注冊表時,需要從注冊中心全量拉取注冊表到本地存著。那后續如果有客戶端注冊、下線的話,注冊表肯定就發生變化了,這個時候客戶端就得更新本地注冊表了,怎么更新呢?下面我會帶著大家一起來看下客戶端第二次(這里代表全量獲取后的下一次)獲取注冊表的方式。
題外話:之前寫過一篇 Redis 主從同步的架構原理,里面也涉及到首次同步和第二次同步,其實原理也類似,但是 Redis 的主從同步原理要復雜些。強烈推薦配合著看一波:
鏡 | 5 個維度深度剖析「主從架構」原理
二、增量獲取引發的問題
上面我們說到,當第一次獲取全量信息后,本地就有注冊信息了。那如果 Server 的注冊表有更新,比如有服務注冊、下線,Client 必須要重新獲取一次注冊表信息才行。
那是否可以重新全量拉取一次呢?
可以是可以,但是,如果注冊表信息很大呢?比如有幾百個微服務都注冊上去了,那一次拉取是非常耗時的,而且占用網絡帶寬,性能較差,這種方案是不靠譜的。
所以我們就需要用增量拉取注冊信息表的方式,也就是說只拉取變化的數據,這樣數據量就比較小了。如下圖所示:
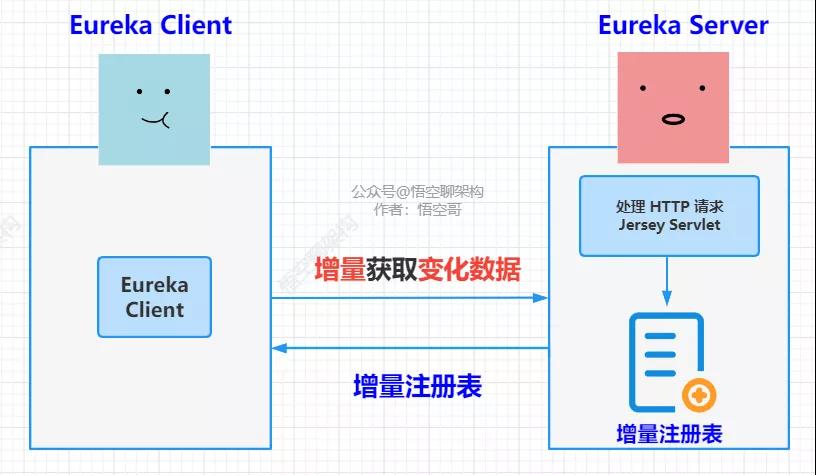
增量獲取注冊表
從源碼里面我們可以看到,Eureka Client 通過調用 getAndUpdateDelta 方法獲取增量的變化的注冊表數據,Eureka Server 將變化的數據返回給 Client。
這里就有幾個問題:
(1)Client 隔多久進行一次增量獲取?
(2)Server 將變化的數據存放在哪里?
(3)Client 如何將變化的數據合并到本地注冊表里面?
下面分別針對上面的幾個問題進行解答。
三、間隔多久同步一次?
3.1 默認間隔時間
默認每隔 30 s 執行一次同步,如下圖所示:
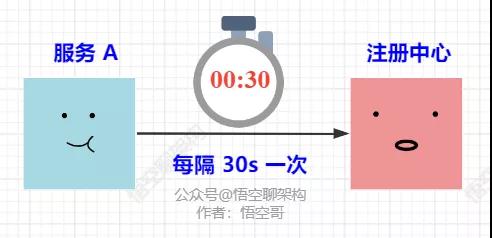
默認 30s 同步一次
這個 30 s 就是由變量 client.refresh.interval 定義的。
Eureka 每 30 s 會調用一個后臺線程去拉取增量注冊表,這個后臺線程的名字叫做:cacheRefresh。如下所示:
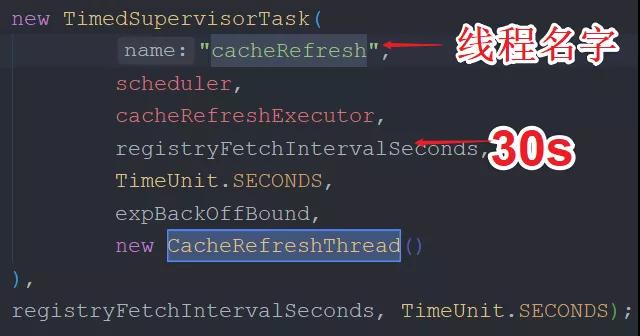
間隔時間的源碼
3.2 Client 發送拉取注冊表的請求
就是調用 getDelta 方法,發送 HTTP請求調用 jersey 的 restful 接口,然后 Server 端的 Jersey 框架就會去處理這個請求了。發送請求的方法 getDelta 如下所示:
- eurekaTransport.queryClient.getDelta(remoteRegionsRef.get());
- restful 接口的地址就長這樣:
- http://localhost:8080/v2/apps/delta
那么 Server 端如何過濾出增量的注冊表信息呢?我們可以找到這個方法:getContainerDifferential。如下圖所示:

這個方法主要干的活就是去獲取最近改變的數據。接下來我們看下最近改變的數據存放在哪。
四、變化的數據存放在哪?
4.1 數據結構
其實就是放在這個隊列里面:recentlyChangedQueue。
它的數據結構是一個并發安全的鏈表隊列 ConcurrentLinkedQueue。
鏈表里面存放的元素就是最近變化的注冊信息 RecentlyChangedItem。
- ConcurrentLinkedQueue<RecentlyChangedItem>
當有客戶端注冊的時候,這個鏈表里面的尾部就會追加一個對象。
關于 ConcurrentLinkedQueue,還記得我之前寫過的 18 種隊列嗎?不記得話看下這篇:
45張圖庖丁解牛18種Queue,你知道幾種?
ConcurrentLinkedQueue 是由鏈表結構組成的線程安全的先進先出無界隊列。如下圖所示:
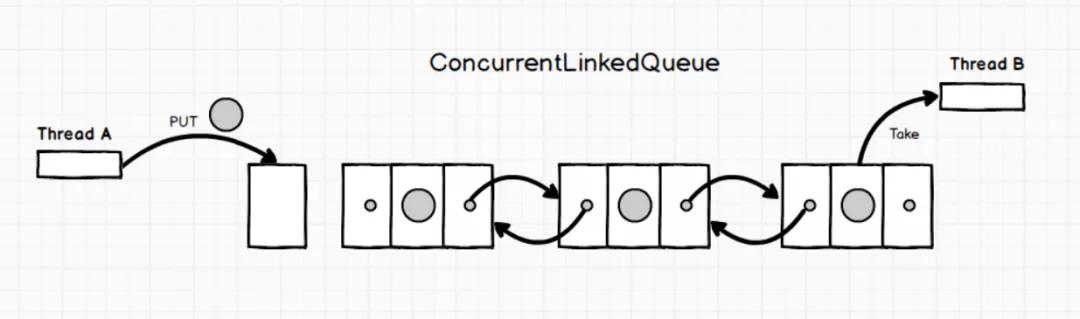
ConcurrentLinkedQueue原理
4.2 內部構造
我覺得這個隊列的構造還是非常值得我們學習的,我們來看下這個隊列的構造,如下圖所示:
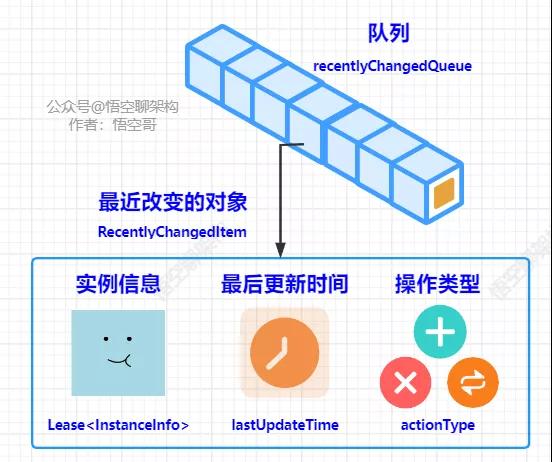
增量數據內部構造
- 這個隊列里面存放的對象是最近改變的對象 RecentlyChangedItem。
- RecentlyChangedItem 存有三個元素:實例信息、操作類型和最后更新時間。
- 實例信息:使用 Lease保存一個客戶端的注冊表信息,這個在第四篇講解注冊表結構已經介紹過。
- 操作類型:當有客戶端發起注冊、更新注冊表、下線時,會設置 actionType,對應三種枚舉值:新增、更新、刪除。
- 最后更新時間:客戶端注冊信息發生改變時,需要同時更新最后更新時間。
4.3 最近的數據
既然上面說到是最近改變的數據才會放進去,那這個最近是多近呢?1 分鐘?2分鐘?
通過源碼我們找到了這個默認配置,三分鐘刷新一次,也就是 180s 刷新一次。

那刷新了什么?刷新其實是會遍歷這個隊列:recentlyChangedQueue。
將隊列里面的所有元素都遍歷一遍,比對每個對象的最后更新時間是否超過了三分鐘,如果超過了,就移除這個元素。如下圖所示:

比較最后更新時間
當元素的最后更新時間超過 3 分鐘未更新,則移除該元素。如下圖所示:
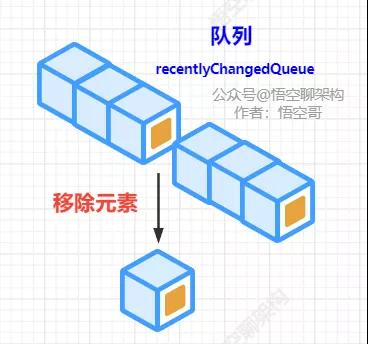
移除元素
4.4 檢查間隔
Server 端會將最近 3 分鐘有更新的注冊信息放入到隊列中,超過 3 分鐘未更新的數據將會被移除。那么多久會檢查一次呢?
通過源碼我們找到,每隔 30s 就會調用一次檢查任務。如下圖所示:
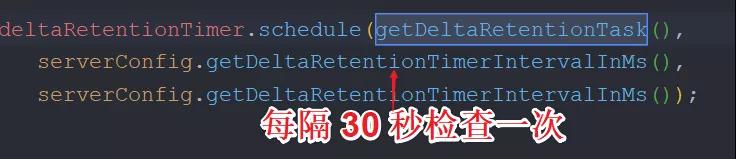
檢查間隔
4.5 小結
- Client 每隔 30 秒調用一次增量獲取注冊表的接口。
- Server 每隔 30 秒調用檢查一次隊列。
- 如果隊列中有元素在 3 分鐘以內都沒有更新過,則從隊列中移除該元素。
五、客戶端注冊表合并
這里有個問題:客戶端首次拿到的全量注冊表,存放本地了。第二次拿到的是增量的注冊表,怎么將兩次的數據合并在一起呢?如下圖所示:
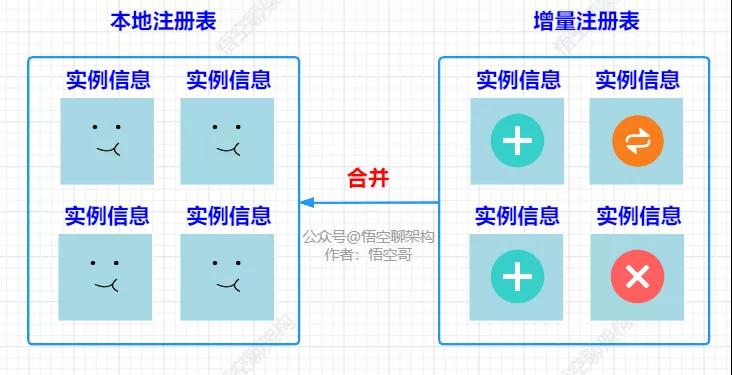
注冊表合并
下面我們來看看下客戶端注冊表合并的原理。
當客戶端調用獲取增量注冊表的請求后,注冊表會返回增量信息,然后客戶端就會調用本地合并的方法:updateDelta。
合并注冊表的原理圖如下所示:
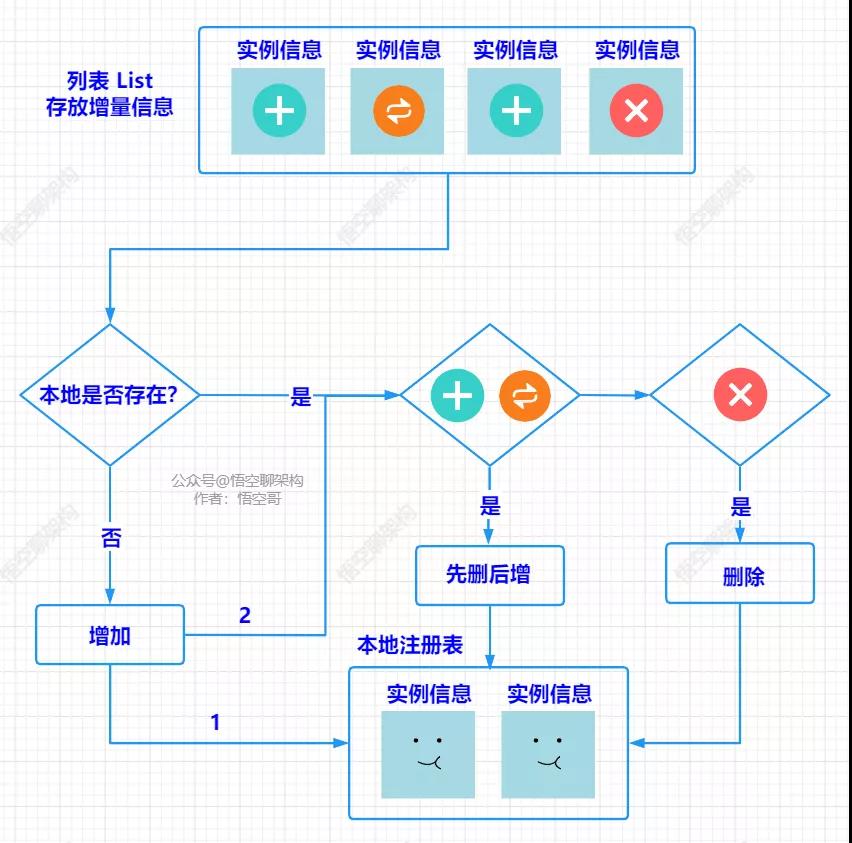
合并注冊表的原理
首先就會遍歷增量注冊表,檢查其中的每一項,不論 actionType 是新增、刪除還是更新,如果本地本來就有,則執行后續的類型判斷邏輯。
如果實例信息的名字在本地不存在則會先往本地注冊表新增一個注冊信息。然后本地肯定存在注冊信息了,執行后續的判斷邏輯。
當類型字段 actionType 等于新增或更新時,先刪除后增加。
當類型字段 actionType 等于刪除時,直接進行刪除。
經過這一些列的邏輯之后,增量注冊表和本地注冊表就合并好了。
六、比對注冊表
經過重重判斷 + 合并操作,客戶端終于完成了本地注冊表的刷新,理論上來說,這個時候客戶端的注冊表應該和注冊中心的注冊表一致了。
但是如何確定是一致的呢?這里我們來考慮幾種方案:
- 再全量拉取一次注冊表,和本地注冊表進行比對。但是既然又要做一次全量拉取,那之前的增量拉取就沒有必要了。
- 拉取增量注冊表,Server 返回全量注冊表的實例 id,客戶端比對每個實例 id 是否存在,以及檢查本地是否有多余的,如果能匹配上,則認為是一致的。但是這里也有一個問題,對于新增和更新的注冊實例,得把更新的實例信息的字段一一比對才能確定是否一致,這就太麻煩了。另外還有一個致命的問題:如果客戶端因為網絡故障下線了,上一次最近 3 分鐘的增量數據沒有拉取到,那么相當于丟失了一次增量數據,這個時候,就不是完整的注冊表信息了。
有沒有既方便又準確的比對方式呢?
有的,那就是哈希比對。哈希比對的意思就是將兩個對象經過哈希算法計算出兩個 hash 值,如果兩個 hash 值相等,則認為這兩個對象相等。這種方式在代碼中也非常常見,比如類的 hashcode() 方法。
從源碼中,我們看到 Eureka Server 返回注冊表時,會返回一個 hash 值,是將全量注冊表 hash 之后的值。調用的是這個方法:getReconcileHashCode()。
如下圖所示,獲取增量注冊表的接口,會返回增量注冊表和 hashcode。
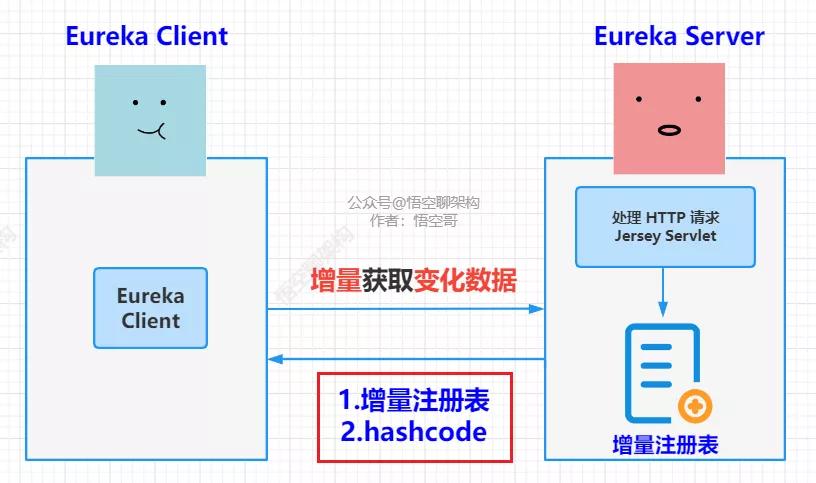
然后本地注冊表合并后,再計算出一個 hashcode,和 Server 返回的 hashcode 進行比對,如果一致,說明本地注冊表和 Server 端一致。如果不一致,則會進行一次全量拉取。
上面說的原理我們畫一張原理圖看下就清楚了:
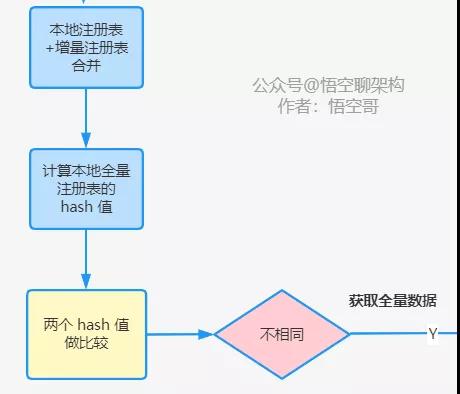
七、總結
本篇文章可以用一張圖來做總結,直接上圖:
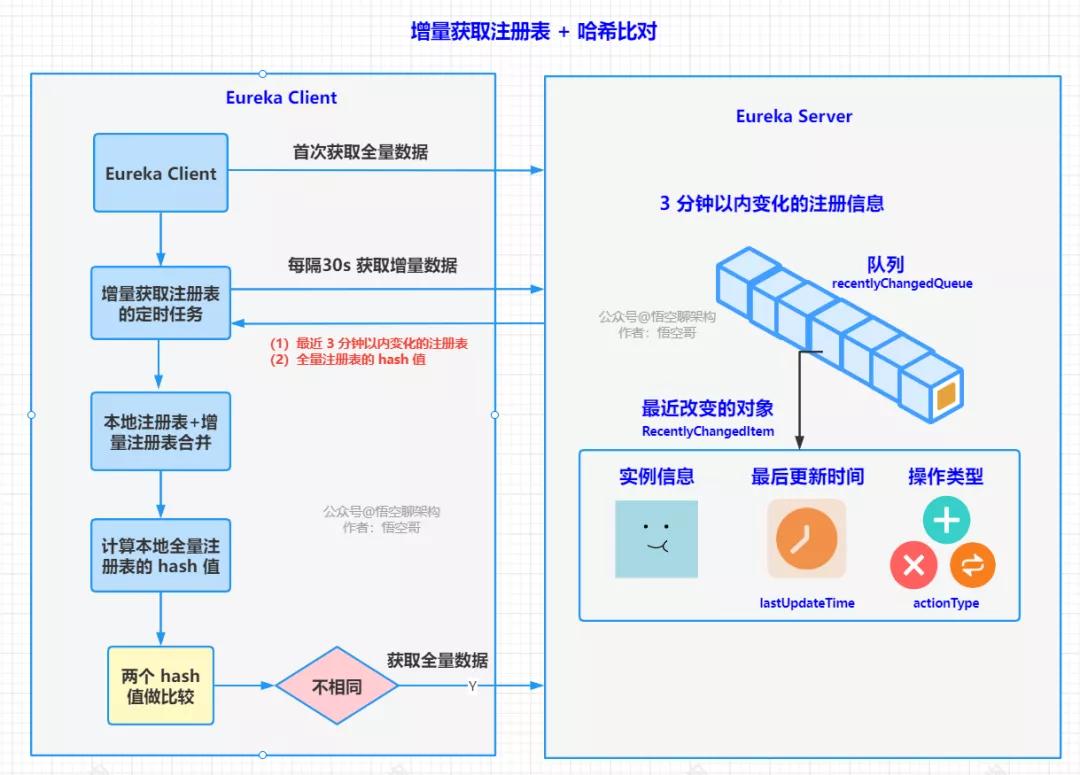
客戶端注冊表同步原理
- 客戶端每隔 30s 獲取一次增量數據,注冊中心返回最近 3 分鐘變化的注冊信息,包含了新注冊的、更新的和下線的服務實例。然后將增量注冊表 + 全量注冊表的 hash 值返回。
- 客戶端將本地注冊表 + 增量注冊表進行合并。合并完成后,計算一個 hash 值,和 Server 返回的 hash 值進行比對,如果相等,則說明客戶端的注冊表和注冊中心的注冊表一致,同步完成。如果不一致,則還需要全量拉取一次。
提個問題:為什么 hash 比對會不一致?答案在文中哦!
下篇,注冊中心的緩存架構走起!