前端Monorepo大倉代碼按需拉取技術實現(xiàn)原理
1、背景與難點
目前,前端平臺探索大倉研發(fā)模式,通過Monorepo大倉的技術,整合前端平臺現(xiàn)有應用的倉庫代碼,使得各業(yè)務域應用質量衡量標準統(tǒng)一,通用基礎組件以及工具函數(shù)能夠快速復用,當基礎通用功能出現(xiàn)問題的時候,能快速地在各應用中升級,提升研發(fā)工作效率,節(jié)省人效。
我們知道在普通的項目開發(fā)中進行 git 的克隆和拉取不會遇到什么問題。但是隨著我們代碼的不斷擴充,代碼倉庫內容會變得越來越大,需要幾個G甚至幾十上百G的磁盤空間時,如果把所有代碼都pull到本地屬實是個不現(xiàn)實的方式,不僅是我們沒有這么大的磁盤空間,而且還有網絡流量的占用問題以及網絡速度問題都是沒有辦法解決。而且,如果Git倉庫特別大,每次執(zhí)行Git命令,等待時間會特別長。對于這些問題,我們做了相關的技術調研。
2、技術調研
我們調研了下Facebook和Google大倉代碼按需拉取的實現(xiàn),其使用方式大致如下:
mercurial:是一個分布式版本控制工具(類似Git,是Matt Mackall開發(fā)),采用的是基于內容尋址的技術。當對一個文件進行修改時,mercurial 不會直接修改文件本身,而是創(chuàng)建一個新版本,該版本包括指向之前版本的引用以及所做修改的差異。這樣,就可以在沒有改變之前版本的基礎上構建新版本,同時正確地跟蹤文件的變化歷史。
Vscode工具:支持下載局部代碼 & 全局代碼檢索等能力
- Piper:代碼管理系統(tǒng)(類似github),是一個強大的分布式版本控制和數(shù)據(jù)管理系統(tǒng),它使用了 Google 自行開發(fā)的 Colossus 文件系統(tǒng)、索引機制等多項技術來實現(xiàn)高效的管理和處理大規(guī)模的代碼庫,并具有高可擴展性、高可靠性和高吞吐量等特點。
- Citc: 云存儲客戶端,用來和piper進行交互
像Facebook和Google都是自研的類似Git的工具,如果我們自己自研的話,成本會很大。所以,目前是另辟蹊徑選擇了基于 git 的sparse checkout 來實現(xiàn)。Git在2.25及以上版本提供了sparse checkout的能力,能夠實現(xiàn)代碼的按需拉取。
3、實現(xiàn)原理
3.1 git sparse checkout的原理
3.1.1 sparse checkout定義
所謂稀疏檢出就是,Git本地庫檢出時不檢出全部,只將指定的文件從Git本地庫檢出到Git工作區(qū),而其他未指定的文件則不予檢出(即使這些文件存在于工作區(qū),其修改也會被忽略)。
3.1.2 sparse checkout原理
當開啟sparse checkout功能的時候, Git 從遠程倉庫下載整個倉庫對象的元數(shù)據(jù)(metadata),而不是下載所有的文件。具體來說,Git下載倉庫時,首先下載倉庫的基礎元數(shù)據(jù)對象(如提交對象、樹和blob等),然后將基礎數(shù)據(jù)對象整合成commit對象,并下載相關的歷史記錄。在這個過程中,Git會逐步下載和存儲文件的有關信息(例如文件名、大小和內容哈希值),但并不會立即下載所有文件的內容。只有當執(zhí)行檢出命令時,Git才會根據(jù)指定的分支或標簽,從遠程倉庫下載所需的文件的實際內容。
Git 實現(xiàn)這個稀疏檢出,是靠一個skip-worktree的標識, 即在 index (即Git暫存區(qū))中為每個文件提供一個名為 skip-worktree 的標志位,默認這個標志位處于關閉狀態(tài)。如果開啟該標志位,則無論Git工作區(qū)對應的文件存在是否,或者是否被修改,Git都認為Git工作區(qū)該文件的版本是最新的、無變化的。Git通過配置文件 .git/info/spare-checkout 定義一個要檢查的目錄和或文件列表,當前Git的基于合并(git merge、git checkout)等命令能夠根據(jù)該配置文件更新的index中文件的 skip-worktree 表示位,實現(xiàn)Git本地庫文件的稀疏檢出。

- 執(zhí)行 "git checkout" 命令來檢出僅僅包含所選目錄或文件路徑的副本倉庫,不包括篩選掉的文件或目錄。
- 當執(zhí)行 "git add" 命令時,會根據(jù) sparse-checkout 文件進行文件過濾,只有匹配到正則表達式描述的文件才會被加入到 Git 的跟蹤列表中。
3.2 基于sparse checkout的CLI實現(xiàn)
我們先來看下在 git 中手動使用sparse checkout 操作的一般步驟 :
第一步,git 初始化
git init
第二步,設置remote倉庫地址
git remote add orgin git@pkg.xxx.com:du-monorepo/XXXXX.git
第三步,初始化
git sparse-checkout init —cone
第四步,添加目錄
git sparse-checkout add xxx/xx ...
第五步,檢出
git pull orgin master為了更方便地使用 sparse checkout 特性,我們開發(fā)了命令行工具,集合封裝了按需檢出相關的操作步驟。
3.2.1 cli 操作步驟
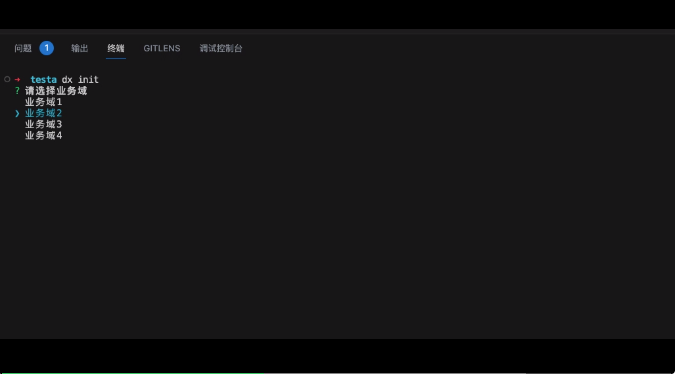
- 命令行執(zhí)行 dx init
- 選擇業(yè)務域
- 選擇項目
- 檢出目標項目
這里面所做的就是把稀疏檢出的操作流程集合在了統(tǒng)一的命令行里面了,便于操作。本質上還是差不多上文demo里面所描述的內容。
 圖片
圖片
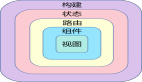
上圖是前端大倉目前已經遷移的全部應用目錄結構,可以看到不同的業(yè)務域下有不同的應用,比如客服的研發(fā)只關注客服的應用,商家的研發(fā)只關注商家的應用,通過上面的CLI操作步驟只需拉取對應目錄下的代碼就可以了,流程效果如下:
3.2.2 實現(xiàn)流程
 圖片
圖片
如上圖所示,整個cli 是基于Pipline 的設計模式,Pipeline模式為管道模式,也稱為流水線模式。通過預先設定好的一系列的階段來處理輸入的數(shù)據(jù),每個階段的輸出即是下一個階段的輸入(Pipeline其實是使用了責任鏈模式的思想)。模型圖如下:
 圖片
圖片
Pipeline設計模式的精髓在于它的可配置化,并且嵌套可拓展。在使用Pipeline時,如果想調換Valve的順序,或者某些業(yè)務是不是用某個Valve,都是可以在外部配置的。這樣就可以很靈活地適配多樣化的業(yè)務,針對不同的業(yè)務配置不同的處理流程,擴展性、靈活性比較強。
3.3 基于sparse checkout的VSCode插件實現(xiàn)
3.3.1 大倉VsCode插件組成要素
大倉VsCode插件由【啟動按鈕】、主側邊欄【HELP】以及【Monorepo管理面板】三個要素組成
 插件組成要素
插件組成要素
3.3.2 插件實現(xiàn)原理
下面介紹下這三個元素以及元素間聯(lián)動的代碼實現(xiàn)。
- 插件代碼結構&基本架構
 代碼結構
代碼結構
 插件基本架構
插件基本架構
- 插件啟動按鈕
啟動按鈕是在package.json里配置的,配置項為contributes.viewsContainers.viewsContainers,可以配置按鈕的id,標題和icon
 圖片
圖片
當點擊啟動按鈕后,就會激活插件,并執(zhí)行activate的鉤子函數(shù),activate需要在名為extension.ts的文件中實現(xiàn)并導出:
 圖片
圖片
當插件被銷毀時,會調用extension.ts導出的deactivate鉤子函數(shù),在這個鉤子里可以進行一些資源的銷毀。
其中activate執(zhí)行了打開【Monorepo管理面板】的代碼,這樣插件在啟動時就會自動打開面板。
- 主側邊欄【HELP】
該元素也是在package.json中配置的,配置項為:contributes.viewsWelcome,可以在content配置項中配置內容,綁定視圖,并為按鈕的點擊事件綁定響應指令,這里綁定的指令是自定義指令:monorepo-init-extend.startClone。
 圖片
圖片
在extension.ts中注冊自定義指令:monorepo-init-extend.startClone,以及執(zhí)行該指令的響應。
 圖片
圖片
可以看到該指令將創(chuàng)建并打開【Monorepo管理面板】,從而實現(xiàn)主側邊欄【HELP】和【Monorepo管理面板】之間的聯(lián)動效果。當用戶點擊【HELP】中的【請選擇應用】時,就會執(zhí)行該指令并打開【Monorepo管理面板】。
- Monorepo管理面板
Monorepo管理面板是通過在VSCode中創(chuàng)建一個webviewPanel,并注入html模版來實現(xiàn)的。并且插件和webview之間可以通過postMessage api來進行通信。如在【Monorepo管理面板】中,當點擊了【確定】按鈕,就會通過postMessage將所選應用的信息通過postMessage發(fā)送給插件,插件將這些信息作為執(zhí)行初始化或代碼追加指令的參數(shù),借助稀疏檢出的命令行工具,執(zhí)行相應的指令,即可按需拉取代碼到本地。在插件執(zhí)行完指令后,就會將相應的反饋信息通過postMessage發(fā)送給【Monorepo管理面板】。
Monorepo管理面板中樹形結構的應用列表數(shù)據(jù)是通過前端統(tǒng)一配置中心獲取的,支持動態(tài)可配置:
 圖片
圖片
4、技術挑戰(zhàn)
基于Git的代碼按需拉取雖然實現(xiàn)了,但是基于Git的文件系統(tǒng)是存在弊端的:
- Git 文件系統(tǒng)中的每個版本都是一組完整的快照,因此在執(zhí)行稀疏操作時,用戶需要指定需要的文件或目錄,此時 Git 會進行文件或目錄的部分檢出。但是,由于 Git 文件系統(tǒng)中的快照是完整的,因此即使只檢出部分文件或目錄,Git 仍需要讀取不相關的文件或目錄,導致 I/O 操作和網絡傳輸量增加,尤其對于大型代碼庫來說,這會增加服務器和網絡的負擔。
Git 仍需要讀取不相關的文件或目錄:這是因為 Git 文件系統(tǒng)使用的是內容尋址(content-addressable)的存儲方式,即每個對象的名稱都是由其內容(也就是文件的具體內容)計算出的 SHA-1 校驗和。每個提交(commit)都是一個完整的目錄樹(tree)對象,其中包含了所有的文件和子目錄。由此,在執(zhí)行稀疏檢出時,Git 需要讀取整個目錄樹(包括不相關的文件和目錄)以計算出其 SHA-1 校驗和和對象名,然后根據(jù)用戶的請求將需要的文件和目錄進行檢出。
- Git 文件系統(tǒng)中的歷史記錄是由一系列提交組成的,每個提交最多保存一個完整的快照。因此,如果對代碼庫進行了稀疏檢出,從歷史記錄中檢查或恢復文件或目錄可能會變得更加困難,因為歷史記錄只能訪問和操作現(xiàn)在存在的文件或目錄,而不包括被檢出的、或不再在代碼庫中的文件或目錄。
由于 Git 文件系統(tǒng)是基于快照(snapshot)記錄歷史記錄的,每個提交都包含整個代碼庫的目錄樹對象和其中所有文件的快照,那么如果使用稀疏檢出機制來指定只檢出部分文件或者目錄,那么在檢查或恢復歷史版本的時候,只能訪問和操作現(xiàn)在存在的文件或目錄。因為那些之前被篩選過去的文件或目錄現(xiàn)在不在當前檢出的代碼庫中,所以無法直接訪問它們的歷史版本。
- sparse checkout是基于Git的元數(shù)據(jù)實現(xiàn)的,跟Git文件系統(tǒng)天然綁定。如果當代碼量達到一定體量的時候,Git的元數(shù)據(jù)會非常龐大,特別是后續(xù)試行主干開發(fā)分支的時候,元數(shù)據(jù)會膨脹的很快,當達到Git本身性能臨界點的時候,就會出現(xiàn)git相關操作卡頓的情況,如git add、git commit等相關命令執(zhí)行會非常緩慢。所以維護好Git的元數(shù)據(jù)在一定的范圍內非常重要,這也是我們后續(xù)在分支維護策略上比較大的技術挑戰(zhàn)。
5、總結
本文主要對于git sparse checkout 的原理和在其之上的應用——大倉按需拉取cli和 vscode按需拉取插件展開講解,實現(xiàn)了初版的基礎能力,當然不可避免也存在著一些問題,當下的按需檢出實現(xiàn)方案可能不是最終極的解決辦法,但它卻是最適合我們當下業(yè)務進程的方案。后面還會繼續(xù)迭代和優(yōu)化,同時關注git官方能力的改善以及我們自身對未來滿足需求能力上的前置探索。