用AI取代SGD?無需訓練ResNet-50,AI秒級預測全部2400萬個參數(shù),準確率60%
本文轉自雷鋒網(wǎng),如需轉載請至雷鋒網(wǎng)官網(wǎng)申請授權。
只需一次前向傳播,這個圖神經(jīng)網(wǎng)絡,或者說元模型,便可預測一個圖像分類模型的所有參數(shù)。有了它,無需再苦苦等待梯度下降收斂!
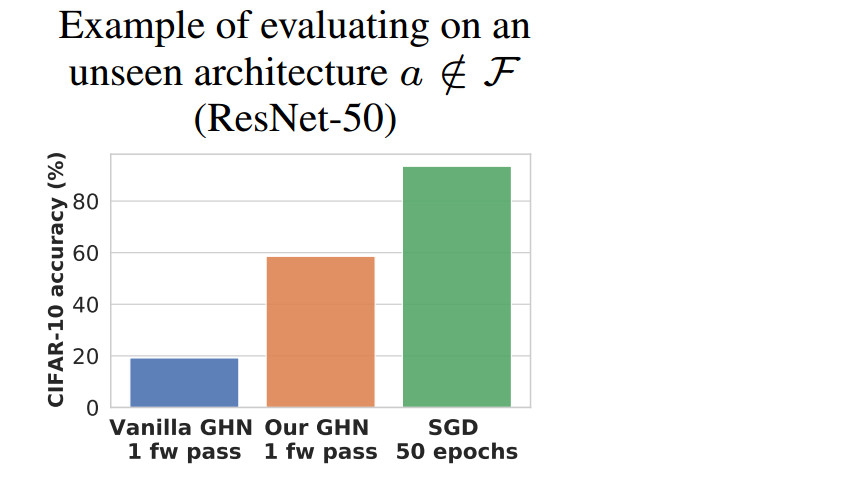
來自圭爾夫大學的論文一作 Boris Knyazev 介紹道,該元模型可以預測 ResNet-50 的所有2400萬個參數(shù),并且這個 ResNet-50 將在 CIFAR-10 上達到將近60%的準確率,無需任何訓練。特別是,該模型適用于幾乎任何神經(jīng)網(wǎng)絡。
基于這個結果,作者向我們發(fā)出了靈魂之問:以后還需要 SGD 或 Adam 來訓練神經(jīng)網(wǎng)絡嗎?
“我們離用單一元模型取代手工設計的優(yōu)化器又近了一步,該元模型可以在一次前向傳播中預測幾乎任何神經(jīng)網(wǎng)絡的參數(shù)。”
令人驚訝的是,這個元模型在訓練時,沒有接收過任何類似 ResNet-50 的網(wǎng)絡(作為訓練數(shù)據(jù))。
該元模型的適用性非常廣,不僅是ResNet-50,它還可以預測 ResNet-101、ResNet-152、Wide-ResNets、Visual Transformers 的所有參數(shù),“應有盡有”。不止是CIFAR-10,就連在ImageNet這樣更大規(guī)模的數(shù)據(jù)集上,它也能帶來不錯的效果。
同時,效率方面也很不錯。該元模型可以在平均不到 1 秒的時間內預測給定網(wǎng)絡的所有參數(shù),即使在 CPU 上,它的表現(xiàn)也是如此迅猛!
但天底下終究“沒有免費的午餐”,因此當該元模型預測其它不同類型的架構時,預測的參數(shù)不會很準確(有時可能是隨機的)。一般來說,離訓練分布越遠(見圖中的綠框),預測的結果就越差。
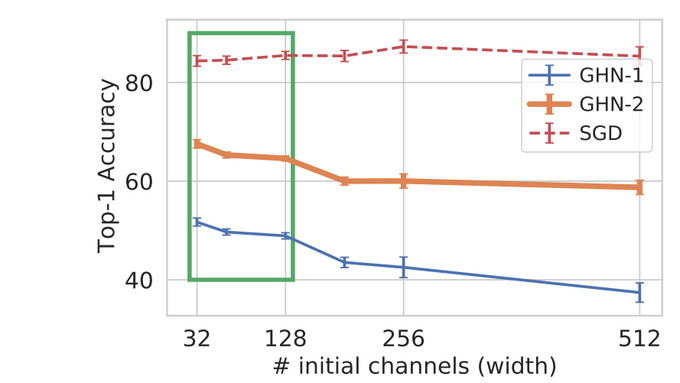
但是,即使使用預測參數(shù)的網(wǎng)絡分類準確率很差,也不要失望。
我們仍然可以將其作為具有良好初始化參數(shù)的模型,而不需要像過去那樣,使用隨機初始化,“我們可以在這種遷移學習中受益,尤其是在少樣本學習任務中。”
作者還表示,“作為圖神經(jīng)網(wǎng)絡的粉絲”,他們特地選用了GNN作為元模型。該模型是基于 Chris Zhang、Mengye Ren 和 Raquel Urtasun發(fā)表的ICLR 2019論文“Graph HyperNetworks for Neural Architecture Search”GHN提出的。

論文地址:https://arxiv.org/abs/1810.05749
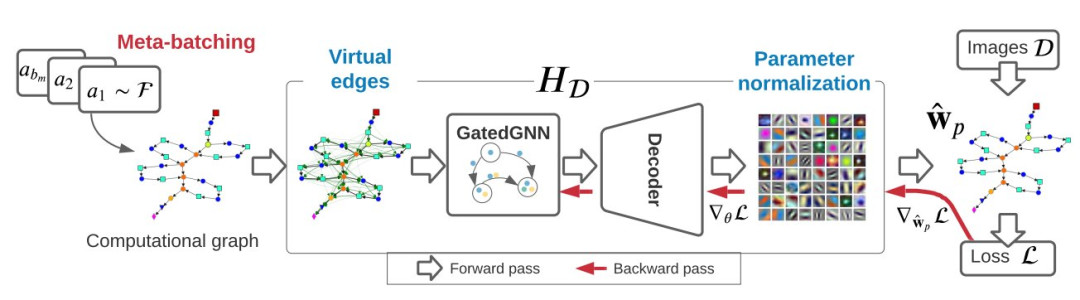
在他們的基礎上,作者開發(fā)并訓練了一個新的模型 GHN-2,它具有更好的泛化能力。
簡而言之,在多個架構上更新 GHN 參數(shù),并正確歸一化預測參數(shù)、改善圖中的遠程交互以及改善收斂性至關重要。
為了訓練 GHN-2,作者引入了一個神經(jīng)架構數(shù)據(jù)集——DeepNets-1M。
這個數(shù)據(jù)集分為訓練集、驗證集和測試集三個部分。此外,他們還使用更廣、更深、更密集和無歸一化網(wǎng)絡來進行分布外測試。
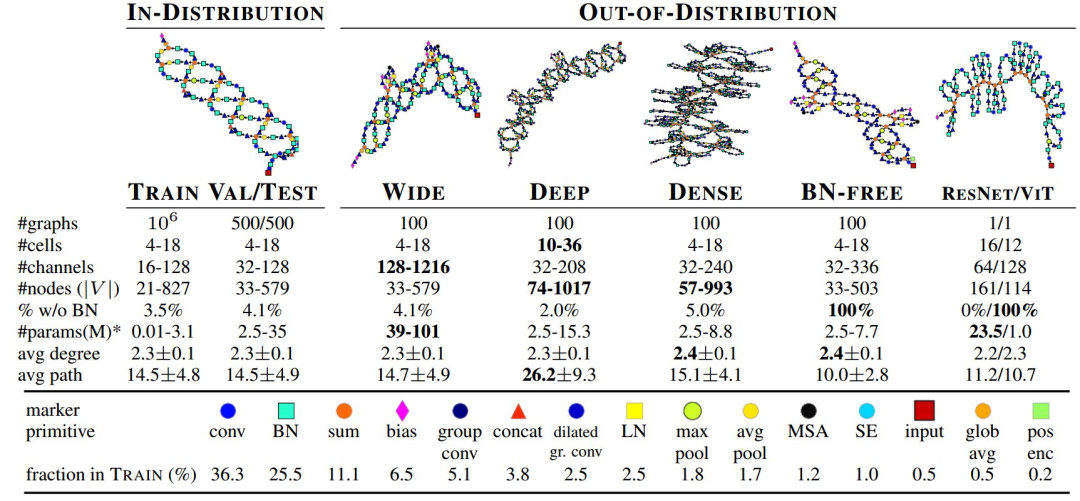
作者補充道,DeepNets-1M 可以作為一個很好的測試平臺,用于對不同的圖神經(jīng)網(wǎng)絡 (GNN) 進行基準測試。“使用我們的 PyTorch 代碼,插入任何 GNN(而不是我們的 Gated GNN )應該都很簡單。”
除了解決參數(shù)預測任務和用于網(wǎng)絡初始化之外, GHN-2 還可用于神經(jīng)架構搜索,“GHN-2可以搜索最準確、最魯棒(就高斯噪聲而言)、最有效和最容易訓練的網(wǎng)絡。”
這篇論文已經(jīng)發(fā)表在了NeurIPS 2021上,研究人員分別來自圭爾夫大學、多倫多大學向量人工智能研究所、CIFAR、FAIR和麥吉爾大學。

論文地址:https://arxiv.org/pdf/2110.13100.pdf
項目也已經(jīng)開源,趕緊去膜拜這個神經(jīng)網(wǎng)絡優(yōu)化器吧!
項目地址:https://github.com/facebookresearch/ppuda
1、模型詳解
考慮在大型標注數(shù)據(jù)集(如ImageNet)上訓練深度神經(jīng)網(wǎng)絡的問題, 這個問題可以形式化為對給定的神經(jīng)網(wǎng)絡 a 尋找最優(yōu)參數(shù)w。
損失函數(shù)通常通過迭代優(yōu)化算法(如SGD和Adam)來最小化,這些算法收斂于架構 a 的性能參數(shù)w_p。
盡管在提高訓練速度和收斂性方面取得了進展,但w_p的獲取仍然是大規(guī)模機器學習管道中的一個瓶頸。
例如,在 ImageNet 上訓練 ResNet-50 可能需要花費相當多的 GPU 時間。
隨著網(wǎng)絡規(guī)模的不斷增長,以及重復訓練網(wǎng)絡的必要性(如超參數(shù)或架構搜索)的存在,獲得 w_p 的過程在計算上變得不可持續(xù)。
而對于一個新的參數(shù)預測任務,在優(yōu)化新架構 a 的參數(shù)時,典型的優(yōu)化器會忽略過去通過優(yōu)化其他網(wǎng)絡獲得的經(jīng)驗。
然而,利用過去的經(jīng)驗可能是減少對迭代優(yōu)化依賴的關鍵,從而減少高計算需求。
為了朝著這個方向前進,研究人員提出了一項新任務,即使用超網(wǎng)絡 HD 的單次前向傳播迭代優(yōu)化。
為了解決這一任務,HD 會利用過去優(yōu)化其他網(wǎng)絡的知識。
例如,我們考慮 CIFAR-10 和 ImageNet 圖像分類數(shù)據(jù)集 D,其中測試集性能是測試圖像的分類準確率。
讓 HD 知道如何優(yōu)化其他網(wǎng)絡的一個簡單方法是,在[架構,參數(shù)]對的大型訓練集上對其進行訓練,然而,這個過程的難度令人望而卻步。
因此,研究人員遵循元學習中常見的雙層優(yōu)化范式,即不需要迭代 M 個任務,而是在單個任務(比如圖像分類)上迭代 M 個訓練架構。
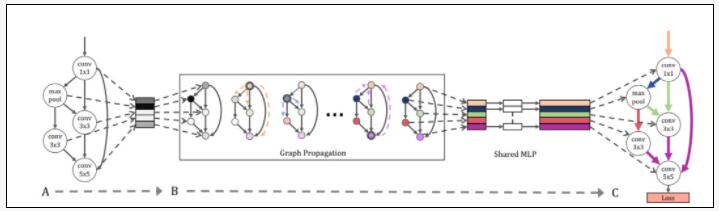
圖 0:GHN原始架構概覽。A:隨機采樣一個神經(jīng)網(wǎng)絡架構,生成一個GHN。B:經(jīng)過圖傳播后,GHN 中的每個節(jié)點都會生成自己的權重參數(shù)。C:通過訓練GHN,最小化帶有生成權重的采樣網(wǎng)絡的訓練損失。根據(jù)生成網(wǎng)絡的性能進行排序。來源:https://arxiv.org/abs/1810.05749
通過優(yōu)化,超網(wǎng)絡 HD 逐漸獲得了如何預測訓練架構的性能參數(shù)的知識,然后它可以在測試時利用這些知識。
為此,需要設計架構空間 F 和 HD。
對于 F,研究人員基于已有的神經(jīng)架構設計空間,我們以兩種方式對其進行了擴展:對不同架構進行采樣的能力和包括多種架構的擴展設計空間,例如 ResNets 和 Visual Transformers。
這樣的架構可以以計算圖的形式完整描述(圖 1)。
因此,為了設計超網(wǎng)絡 HD,將依賴于圖結構數(shù)據(jù)機器學習的最新進展。
特別是,研究人員的方案建立在 Graph HyperNetworks (GHNs) 方法的基礎上。
通過設計多樣化的架構空間 F 和改進 GHN,GHN-2在 CIFAR-10和 ImageNet上預測未見過架構時,圖像識別準確率分別提高到77% (top-1)和48% (top-5)。
令人驚訝的是,GHN-2 顯示出良好的分布外泛化,比如對于相比訓練集中更大和更深的架構,它也能預測出良好的參數(shù)。
例如,GHN-2可以在不到1秒的時間內在 GPU 或 CPU 上預測 ResNet-50 的所有 2400 萬個參數(shù),在 CIFAR-10 上達到約 60%的準確率,無需任何梯度更新(圖 1,(b))。
總的來說,該框架和結果為訓練網(wǎng)絡開辟了一條新的、更有效的范式。
本論文的貢獻如下:
(a)引入了使用單個超網(wǎng)絡前向傳播預測不同前饋神經(jīng)網(wǎng)絡的性能參數(shù)的新任務;
(b)引入了 DEEPNETS-1M數(shù)據(jù)集,這是一個標準化的基準測試,具有分布內和分布外數(shù)據(jù),用于跟蹤任務的進展;
(c)定義了幾個基線,并提出了 GHN-2 模型,該模型在 CIFAR-10 和 ImageNet( 5.1 節(jié))上表現(xiàn)出奇的好;
(d)該元模型學習了神經(jīng)網(wǎng)絡架構的良好表示,并且對于初始化神經(jīng)網(wǎng)絡是有用的。
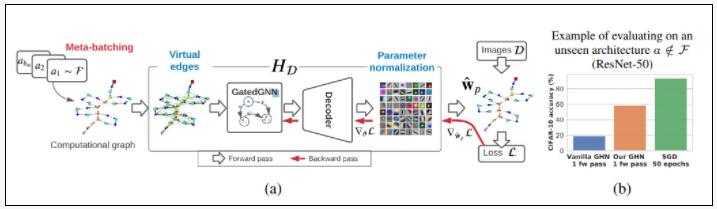
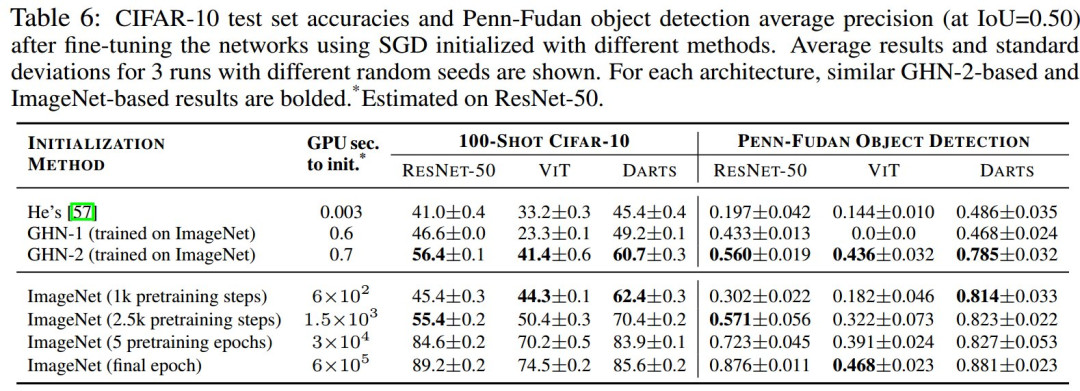
上圖圖1(a)展示了GHN 模型概述(詳見第 4 節(jié)),基于給定圖像數(shù)據(jù)集和DEEPNETS-1M架構數(shù)據(jù)集,通過反向傳播來訓練GHN模型,以預測圖像分類模型的參數(shù)。
研究人員對 vanilla GHN 的主要改進包括Meta-batching、Virtual edges、Parameter normalization等。
其中,Meta-batching僅在訓練 GHN 時使用,而Virtual edges、Parameter normalization用于訓練和測試時。a1 的可視化計算圖如表 1 所示。
圖1(b)比較了由 GHN 預測ResNet-50 的所有參數(shù)的分類準確率與使用 SGD 訓練其參數(shù)時的分類準確率。盡管自動化預測參數(shù)得到的網(wǎng)絡準確率仍遠遠低于人工訓練的網(wǎng)絡,但可以作為不錯的初始化手段。
2、實驗:參數(shù)預測
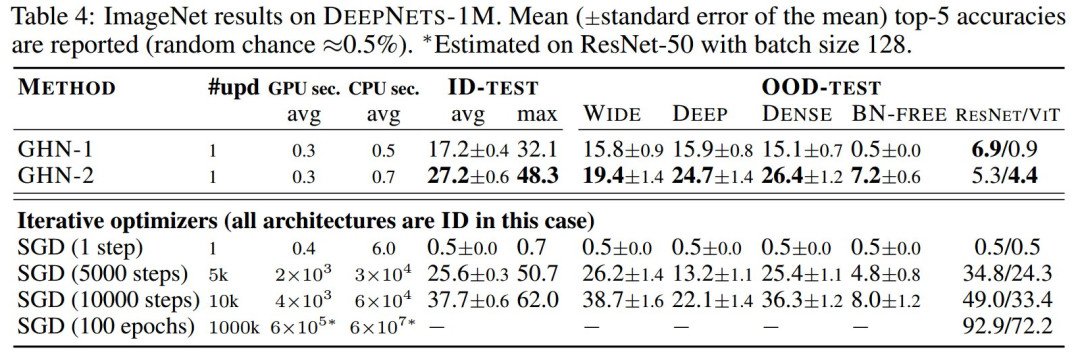
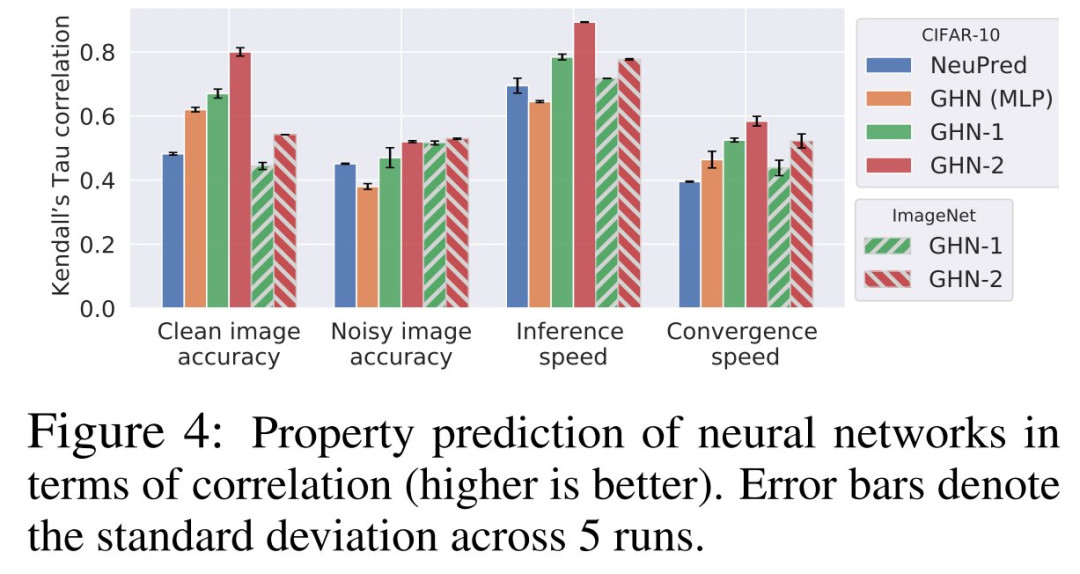
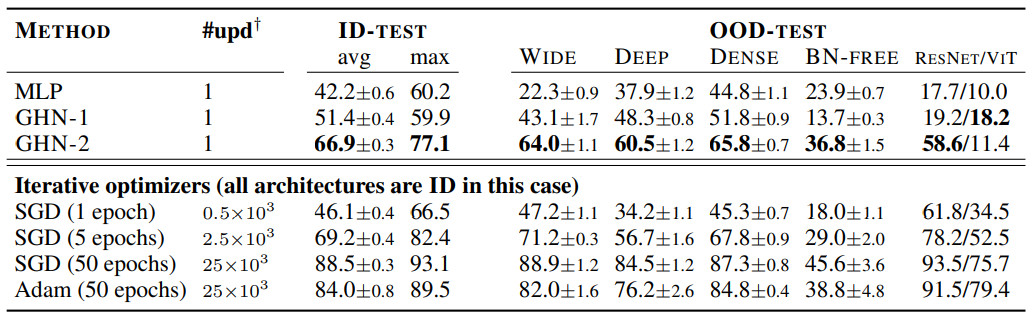
盡管 GHN-2 從未觀察過測試架構,但 GHN-2 為它們預測了良好的參數(shù),使測試網(wǎng)絡在兩個圖像數(shù)據(jù)集上的表現(xiàn)都出奇的好(表 3 和表 4)。
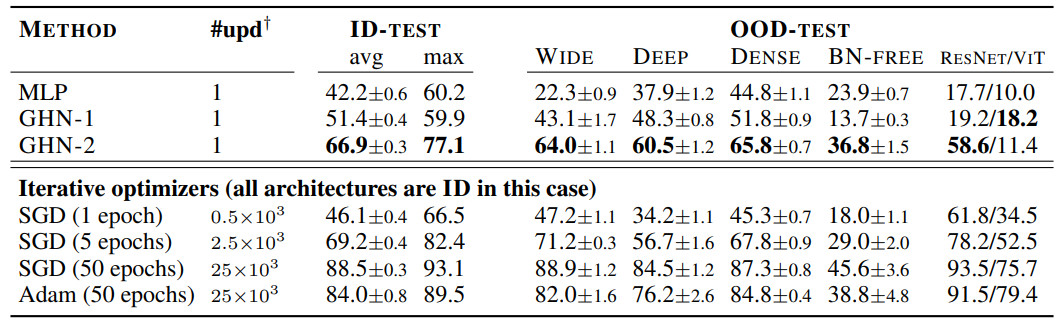
表 3:GHN-2在DEEPNETS-1M 的未見過 ID 和 OOD 架構的預測參數(shù)結果(CIFAR-10 )
GHN-2甚至在 ImageNet 上展示了良好的結果,其中對于某些架構,實現(xiàn)了高達 48.3% 的top-5準確率。
雖然這些結果對于直接下游應用來說很不夠,但由于三個主要原因,它們非常有意義。
首先,不依賴于通過 SGD 訓練架構 F 的昂貴得令人望而卻步的過程。
其次,GHN 依靠單次前向傳播來預測所有參數(shù)。
第三,這些結果是針對未見過的架構獲得的,包括 OOD 架構。即使在嚴重的分布變化(例如 ResNet-506 )和代表性不足的網(wǎng)絡(例如 ViT7 )的情況下,GHN-2仍然可以預測比隨機參數(shù)表現(xiàn)更好的參數(shù)。
在 CIFAR-10 上,GHN-2 的泛化能力特別強,在 ResNet-50 上的準確率為 58.6%。
在這兩個圖像數(shù)據(jù)集上,GHN-2 在 DEEPNETS-1M 的所有測試子集上都顯著優(yōu)于 GHN-1,在某些情況下絕對增益超過 20%,例如BN-FREE 網(wǎng)絡上的 36.8% 與 13.7%(表 3)。
利用計算圖的結構是 GHN 的一個關鍵特性,當用 MLP 替換 GHN-2 的 GatedGNN 時,在 ID(甚至在 OOD)架構上的準確率從 66.9% 下降到 42.2%。
與迭代優(yōu)化方法相比,GHN-2 預測參數(shù)的準確率分別與 CIFAR-10 和 ImageNet 上 SGD 的 ∼2500 次和 ∼5000 次迭代相近。
相比之下,GHN-1 的性能分別與僅 ~500 次和 ~2000次(未在表 4 中展示)迭代相似。
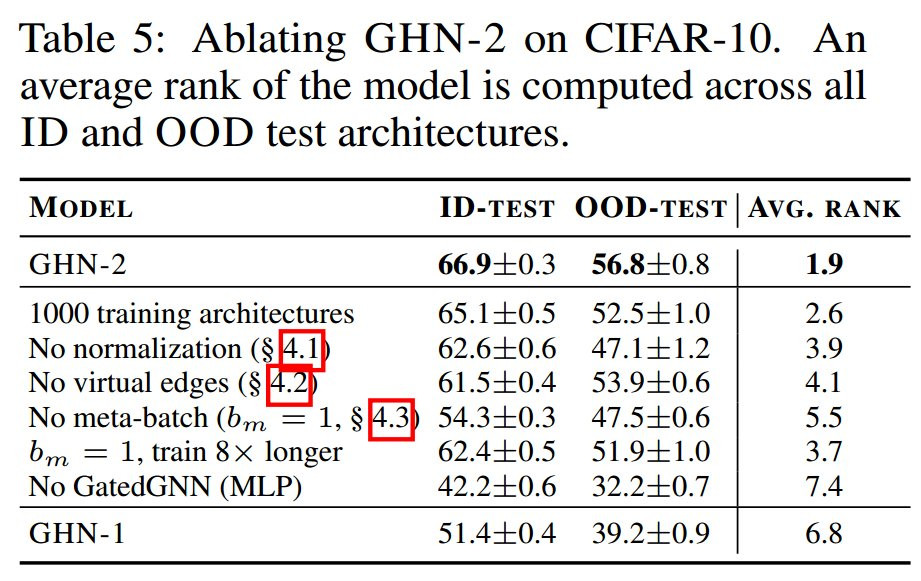
消融實驗(表 5)表明第 4 節(jié)中提出的所有三個組件都很重要。
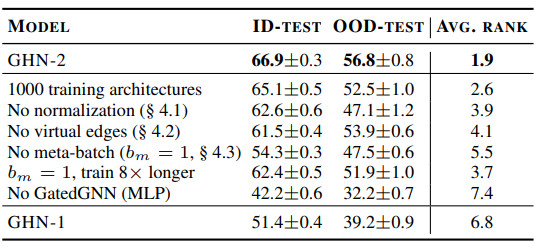
表 5:在 CIFAR-10 上消融 GHN-2,在所有 ID 和 OOD 測試架構中計算模型的平均排名