













一日一技:XPath 匹配如何忽略大小寫?
GNE[1]在對新聞進行預處理的時候,會提前移除一些顯然不可能包含正文的 Dom 節點,從而增加提取的準確性。
一般來說,網頁的版權信息,頁尾信息,會放在一個叫做<div class="footer"></div>的標簽里面。所以,要用 XPath 找到這種版權信息,本來應該非常簡單://div[@class="footer"]。但實際場景中,可能有兩種情況:<div class="xxxfooteryyy"></div>和<div class="Footer">。
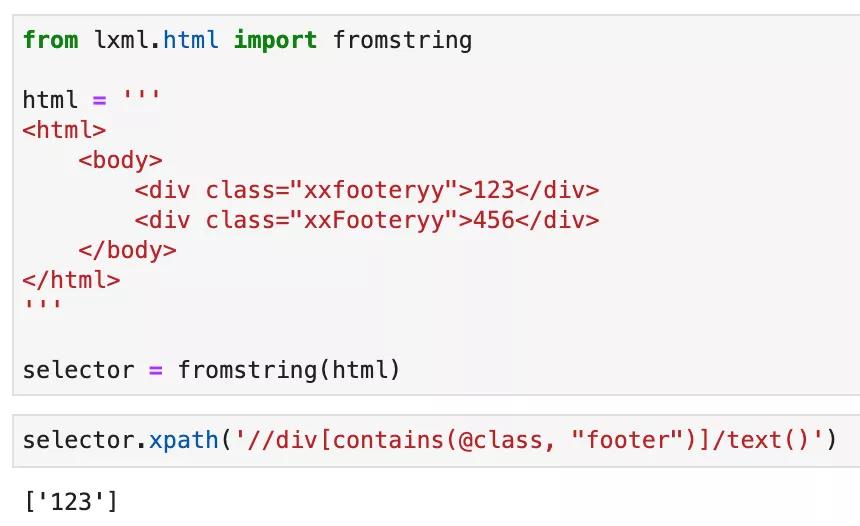
footer前后都有字符的時候,我們可以使用 XPath 的關鍵詞contains://div[contains(@class, "footer")],運行效果如下圖所示:
但如果我們想忽略大小寫的時候怎么辦呢?實際上,在 XPath 2.0的標準里面,有一個關鍵字叫做lower-case就可以實現這個需求,XPath 寫為: //div[lower-case(@class)="footer"]/text()。我們可以在一些在線 XPath 檢查的工具里面看到提取效果,如下圖所示:

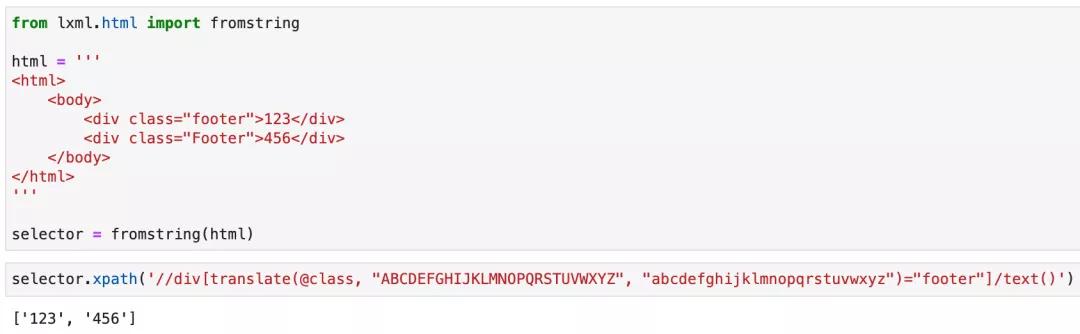
但壞就壞在,Python 的第三方庫lxml使用的是 XPath 1.0標準,因此沒有lower-case這個關鍵字。所以要實現這個需求,我們需要使用另一個關鍵字translate://div[translate(@class, "ABCDEFGHIJKLMNOPQRSTUVWXYZ", "abcdefghijklmnopqrstuvwxyz")="footer"]/text()。
運行效果如下圖所示:
這里的translate效果就跟 Python 字符串的translate差不多。我以前寫過一篇文章:一日一技:在字符串中批量替換單個字符介紹在 Python 里面怎么使用translate方法。
XPath 的translate的語法為:translate(目標屬性, 需要替換的字符, 替換成字符)。這樣就可以把節點的目標屬性值轉成小寫再來對比。
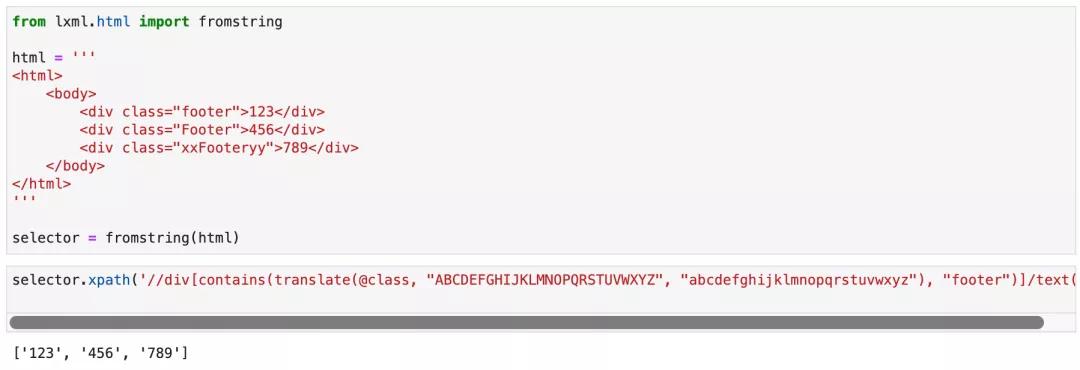
那么,如果HTML 標簽的屬性值是xxxFooteryyy怎么辦呢?其實我們也可以像函數嵌套一樣再套一層contains://div[contains(translate(@class, "ABCDEFGHIJKLMNOPQRSTUVWXYZ", "abcdefghijklmnopqrstuvwxyz"), "footer")]
運行效果如下圖所示:
參考文獻
[1]GNE: https://github.com/GeneralNewsExtractor/GeneralNewsExtractor
本文轉載自微信公眾號「未聞Code」,可以通過以下二維碼關注。轉載本文請聯系未聞Code公眾號。

























